CNN-ების მომზადებისას, ერთ-ერთი პრობლემა ის არის, რომ ჩვენ გვჭირდება ბევრი ეტიკეტირებული მონაცემები. გამოსახულების კლასიფიკაციის შემთხვევაში, ჩვენ გვჭირდება სურათების გამოყოფა სხვადასხვა კლასებად, რაც არის ხელით ძალისხმევა.
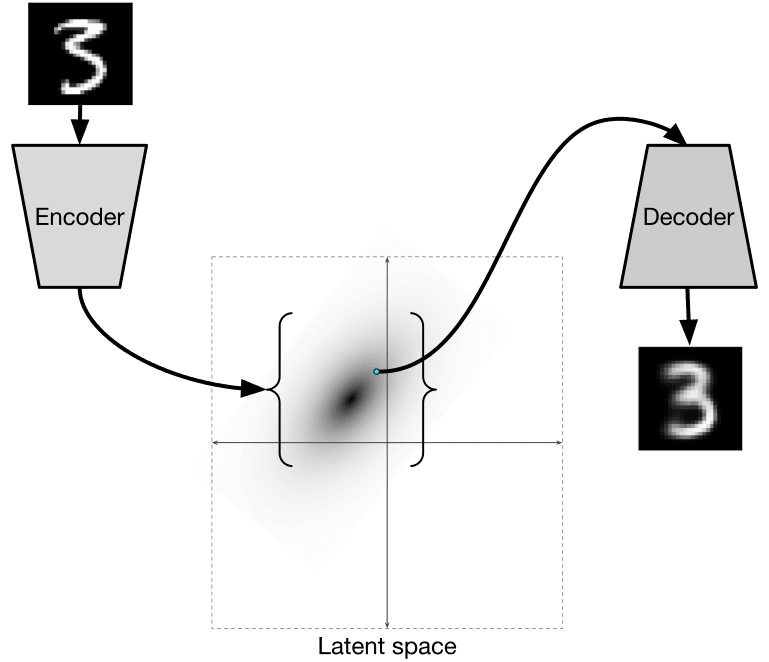
თუმცა, ჩვენ შეიძლება გვსურს გამოვიყენოთ ნედლეული (არა მარკირებული) მონაცემები CNN-ის ფუნქციების ამომყვანების ტრენინგისთვის, რასაც თვით ზედამხედველობითი სწავლება ეწოდება. ეტიკეტების ნაცვლად, ჩვენ გამოვიყენებთ ტრენინგ სურათებს როგორც ქსელის შეყვანის, ასევე გამოსავლის სახით. autoencoder-ის მთავარი იდეა არის ის, რომ ჩვენ გვექნება კოდერის ქსელი, რომელიც გარდაქმნის შეყვანის სურათს რაღაც ლატენტურ სივრცეში (ჩვეულებრივ, ეს არის მხოლოდ მცირე ზომის ვექტორი), შემდეგ დეკოდერის ქსელი, რომლის მიზანი იქნება ორიგინალური სურათის რეკონსტრუქცია.
იმის გამო, რომ ჩვენ ვამზადებთ ავტოენკოდერს, რათა აღბეჭდოს რაც შეიძლება მეტი ინფორმაცია ორიგინალური სურათიდან ზუსტი რეკონსტრუქციისთვის, ქსელი ცდილობს მოიძიოს შეყვანის სურათების საუკეთესო ემბედინგი მნიშვნელობის დასაფიქსირებლად.
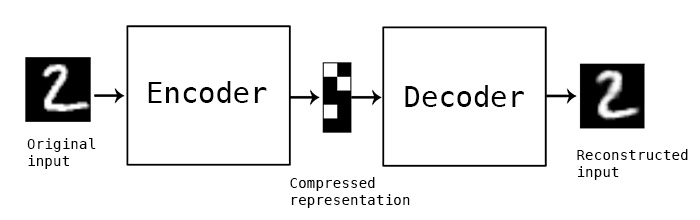
სურათი კერას ბლოგი-დან
მოდით შევქმნათ უმარტივესი ავტოკოდერი MNIST-ისთვის!
იტვირთება…განსაზღვრეთ ტრენინგის პარამეტრები და შეამოწმეთ არის თუ არა GPU ხელმისაწვდომი:
იტვირთება…შემდეგი ფუნქცია ჩატვირთავს MNIST მონაცემთა ბაზას და გამოიყენებს მასზე მითითებულ გარდაქმნებს. ის ასევე დაყოფს მას მატარებლის/ტესტის მონაცემთა ნაკრებებად.
იტვირთება…ახლა მოდით ჩატვირთოთ მონაცემთა ნაკრები და განვსაზღვროთ მონაცემთა ჩამტვირთველები მატარებლისა და ტესტირებისთვის:
იტვირთება…იტვირთება…იტვირთება…იტვირთება…გამოტანა
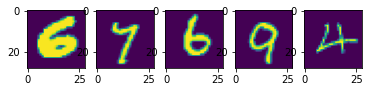
იტვირთება…იტვირთება…იტვირთება…იტვირთება…იტვირთება…იტვირთება…გამოტანა
100%|██████████| 30/30 [06:49<00:00, 13.65s/it, train loss:=0.104, test loss:=0.104]
იტვირთება…გამოტანა
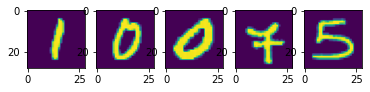
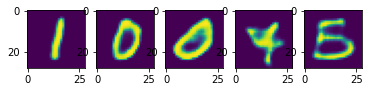
ამოცანა 1: შეეცადეთ მოამზადოთ ავტოენკოდერი ძალიან მცირე ფარული ვექტორის ზომით, მაგ. 2 და დახაზეთ წერტილები, რომლებიც შეესაბამება სხვადასხვა ციფრს. მინიშნება: გამოიყენეთ სრულად დაკავშირებული მკვრივი ფენა კონვოლუტონური ნაწილის შემდეგ, რათა შეამციროთ ვექტორის ზომა საჭირო მნიშვნელობამდე.
ამოცანა 2: დაწყებული სხვადასხვა ციფრიდან, მიიღეთ მათი ფარული სივრცის წარმოდგენები და ნახეთ, რა გავლენას ახდენს ლატენტურ სივრცეში გარკვეული ხმაურის დამატება მიღებულ ციფრებზე.
დენოიზირება
ავტოინკოდერები შეიძლება ეფექტურად იქნას გამოყენებული სურათებიდან ხმაურის მოსაშორებლად. დენოიზერის მომზადების მიზნით, ჩვენ დავიწყებთ ხმაურის გარეშე გამოსახულებებით და დავამატებთ მათ ხელოვნურ ხმაურს. შემდეგ, ჩვენ გამოვკვებავთ ავტოინკოდერს ხმაურიანი სურათებით, როგორც შეყვანის სახით, და ხმაურის გარეშე გამოსახულებით, როგორც გამომავალი.
ვნახოთ, როგორ მუშაობს ეს MNIST-ისთვის:
იტვირთება…გამოტანა
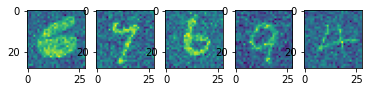
იტვირთება…იტვირთება…იტვირთება…გამოტანა
100%|██████████| 100/100 [22:29<00:00, 13.49s/it, train loss:=0.134, test loss:=0.133]
იტვირთება…გამოტანა
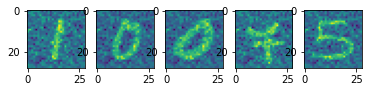

სავარჯიშო: ნახეთ, როგორ მუშაობს MNIST ციფრებზე მომზადებული დენოიზერი სხვადასხვა სურათზე. მაგალითად, შეგიძლიათ აიღოთ მოდის MNIST მონაცემთა ნაკრები, რომელსაც აქვს სურათის იგივე ზომა. გაითვალისწინეთ, რომ დენოიზერი კარგად მუშაობს მხოლოდ იმავე ტიპის გამოსახულებაზე, რომელზედაც ივარჯიშეს (ანუ შეყვანის მონაცემების იგივე ალბათობის განაწილებისთვის).
სუპერ რეზოლუცია
დენოიზერის მსგავსად, ჩვენ შეგვიძლია მოვამზადოთ ავტოენკოდერები გამოსახულების გარჩევადობის გაზრდის მიზნით. სუპერ გარჩევადობის ქსელის მოსამზადებლად, ჩვენ დავიწყებთ მაღალი გარჩევადობის სურათებით და ავტომატურად შევამცირებთ მათ მასშტაბებს ქსელის შეყვანის შესაქმნელად. ამის შემდეგ ჩვენ გამოვკვებავთ ავტოინკოდერს მცირე სურათებით, როგორც შეყვანის სახით და მაღალი გარჩევადობის სურათებს, როგორც გამოსავალს.
ამისათვის მოდით შევამციროთ სურათი 14x14-მდე მატარებელში.
იტვირთება…გამოტანა
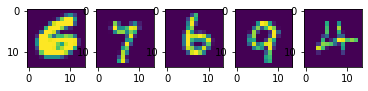
იტვირთება…იტვირთება…იტვირთება…გამოტანა
100%|██████████| 30/30 [06:43<00:00, 13.47s/it, train loss:=0.102, test loss:=0.103]
იტვირთება…გამოტანა
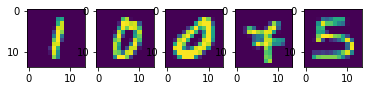

სავარჯიშო: სცადეთ ავარჯიშოთ სუპერ გარჩევადობის ქსელი CIFAR-10-ზე 2x და 4x გაფართოებისთვის. გამოიყენეთ ხმაური, როგორც შემავალი 4x გაფართოების მოდელი და დააკვირდით შედეგს.
ვარიაციული ავტომატური შიფრები (VAE)
ტრადიციული ავტოკოდერები გარკვეულწილად ამცირებენ შეყვანის მონაცემების განზომილებას, აცნობიერებენ შეყვანის სურათების მნიშვნელოვან მახასიათებლებს. თუმცა, ლატენტურ ვექტორებს ხშირად დიდი აზრი არ აქვს. სხვა სიტყვებით რომ ვთქვათ, MNIST მონაცემთა ნაკრების მაგალითზე აყვანა, იმის გარკვევა, თუ რომელი ციფრები შეესაბამება სხვადასხვა ლატენტურ ვექტორებს, არ არის ადვილი ამოცანა, რადგან ახლო ფარული ვექტორები აუცილებლად არ შეესაბამება იმავე ციფრებს.
მეორეს მხრივ, გენერაციული მოდელების მოსამზადებლად უმჯობესია ლატენტური სივრცის გარკვეული გაგება. ეს იდეა მიგვიყვანს ვარიაციული ავტომატური კოდირებით (VAE).
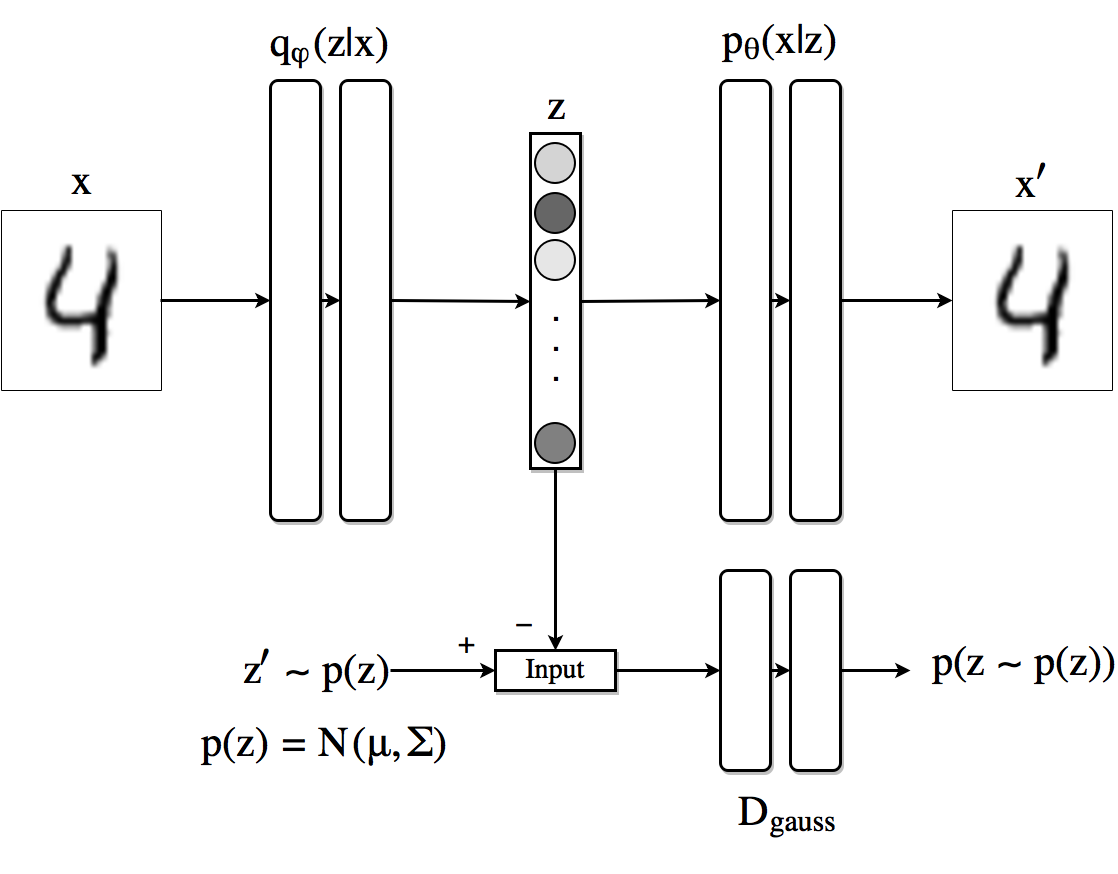
VAE არის ავტოკოდერი, რომელიც სწავლობს ფარული პარამეტრების სტატისტიკური განაწილების წინასწარმეტყველებას, ე.წ. ლატენტური განაწილების. მაგალითად, შეგვიძლია ვივარაუდოთ, რომ ფარული ვექტორები განაწილებული იქნება $N(\mathrm{z_mean},e^{\mathrm{z_log}})$, სადაც $\mathrm{z_mean}, \mathrm{z_log} \in\mathbb{R}^d$. Encoder in VAE სწავლობს ამ პარამეტრების პროგნოზირებას, შემდეგ კი დეკოდერი იღებს შემთხვევით ვექტორს ამ განაწილებიდან ობიექტის რეკონსტრუქციისთვის.
შეჯამება:
- შეყვანის ვექტორიდან ჩვენ ვიწინასწარმეტყველებთ
z_meanდაz_log-ს (თვითონ სტანდარტული გადახრის პროგნოზირების ნაცვლად, ჩვენ ვიწინასწარმეტყველებთ მის ლოგარითმს) - ჩვენ ვატარებთ ვექტორს
sample(z_val in code)განაწილებიდან $N(\mathrm{z_mean},e^{\mathrm{z_log_sigma}})$ - დეკოდერი ცდილობს ორიგინალური სურათის გაშიფვრას
sampleშეყვანის ვექტორის გამოყენებით
სურათი ეს ბლოგის პოსტი-დან ისააკ დიკემანის მიერ
იტვირთება…იტვირთება…იტვირთება…ვარიაციური ავტომატური შიფრები იყენებენ კომპლექსურ დაკარგვის ფუნქციას, რომელიც შედგება ორი ნაწილისგან:
- რეკონსტრუქციის დაკარგვა არის დაკარგვის ფუნქცია, რომელიც გვიჩვენებს, რამდენად ახლოს არის რეკონსტრუქციული სურათი მიზანთან (შეიძლება იყოს MSE). ეს არის იგივე დაკარგვის ფუნქცია, როგორც ჩვეულებრივ ავტოენკოდერებში.
- KL დაკარგვა, რაც უზრუნველყოფს ფარული ცვლადი განაწილების ნორმალურ განაწილებასთან ახლოს ყოფნას. იგი ეფუძნება კულბეკ-ლეიბლერის დივერგენცია ცნებას - მეტრიკა, რათა შეფასდეს, რამდენად მსგავსია ორი სტატისტიკური განაწილება.
იტვირთება…იტვირთება…იტვირთება…იტვირთება…გამოტანა
100%|██████████| 30/30 [04:54<00:00, 9.83s/it, train loss:=35.1, test loss:=35.6]
იტვირთება…გამოტანა

ამოცანა: ჩვენს ნიმუშში ჩვენ მოვამზადეთ სრულად დაკავშირებული VAE. ახლა აიღეთ CNN ზემოთ არსებული ტრადიციული ავტომატური კოდირებიდან და შექმენით CNN-ზე დაფუძნებული VAE.
საპირისპირო ავტომატური შიფრები (AAE)
Adversarial Auto-Encoders არის გენერაციული საპირისპირო ქსელებისა და ვარიაციური ავტომატური შიფრების კომბინაცია.
ენკოდერი იქნება გენერატორი, დისკრიმინატორი ისწავლის რეალური სურათების შიფრატორის გამომავალი გენერირებისგან გარჩევას. შიფრატორის გამომავალი არის განაწილება, ამ გამომავალი დეკოდერი შეეცდება სურათის გაშიფვრას.
ამ მიდგომაში გვაქვს სამი დაკარგვის ფუნქცია: გენერატორის დაკარგვა, დისკრიმინატორის დაკარგვა GAN-ისგან და რეკონსტრუქციის დანაკარგი VAE-სგან.
სურათი ეს ბლოგის პოსტი-დან ფელიპე დუკაუდან
იტვირთება…იტვირთება…იტვირთება…იტვირთება…იტვირთება…იტვირთება…იტვირთება…იტვირთება…იტვირთება…იტვირთება…გამოტანა
100%|██████████| 30/30 [09:22<00:00, 18.75s/it, train reconst loss:=0.0919, train disc loss:=1.39, train enc loss=0.692, test reconst loss:=0.0945, test disc loss:=1.39, test enc loss=0.692]
იტვირთება…გამოტანა
დამატებითი მასალები
- ბლოგის პოსტი NeuroHive-ზე
- ვარიაციური ავტოენკოდერები განმარტებულია