სკეტნოტი ტომომი იმურა-ის მიერ
AIს ძიება ემყარება ცოდნის ძიებას, სამყაროს გაგებას, ისევე როგორც ადამიანებს. მაგრამ როგორ შეგიძლია ამის გაკეთება?
სალექციო ვიქტორინა
AIს ადრეულ დღეებში პოპულარული იყო ზემოდან ქვევით მიდგომა ინტელექტუალური სისტემების შესაქმნელად (განხილული იყო წინა გაკვეთილზე). იდეა იყო ხალხისგან ცოდნის ამოღება მანქანით წაკითხულ ფორმაში და შემდეგ მისი გამოყენება პრობლემების ავტომატურად გადასაჭრელად. ეს მიდგომა ეფუძნებოდა ორ დიდ იდეას:
- ცოდნის წარმოდგენა
- მსჯელობა
ცოდნის წარმომადგენლობა
სიმბოლური AIს ერთ-ერთი მნიშვნელოვანი ცნებაა ცოდნა. მნიშვნელოვანია ცოდნის დიფერენცირება ინფორმაციისგან ან მონაცემებისგან. მაგალითად, შეიძლება ითქვას, რომ წიგნები შეიცავს ცოდნას, რადგან შეიძლება წიგნების შესწავლა და ექსპერტი გახდეს. თუმცა, რას შეიცავს წიგნები, სინამდვილეში ეწოდება მონაცემები და წიგნების კითხვით და ამ მონაცემების ჩვენს მსოფლიო მოდელში ინტეგრირებით ჩვენ ამ მონაცემებს ცოდნად ვაქცევთ.
ცოდნა არის ის, რაც ჩვენს თავშია და წარმოადგენს სამყაროს ჩვენს გაგებას. ის მიიღება აქტიური სწავლის პროცესით, რომელიც აერთიანებს ინფორმაციას, რომელსაც ჩვენ ვიღებთ მსოფლიოს ჩვენს აქტიურ მოდელში.
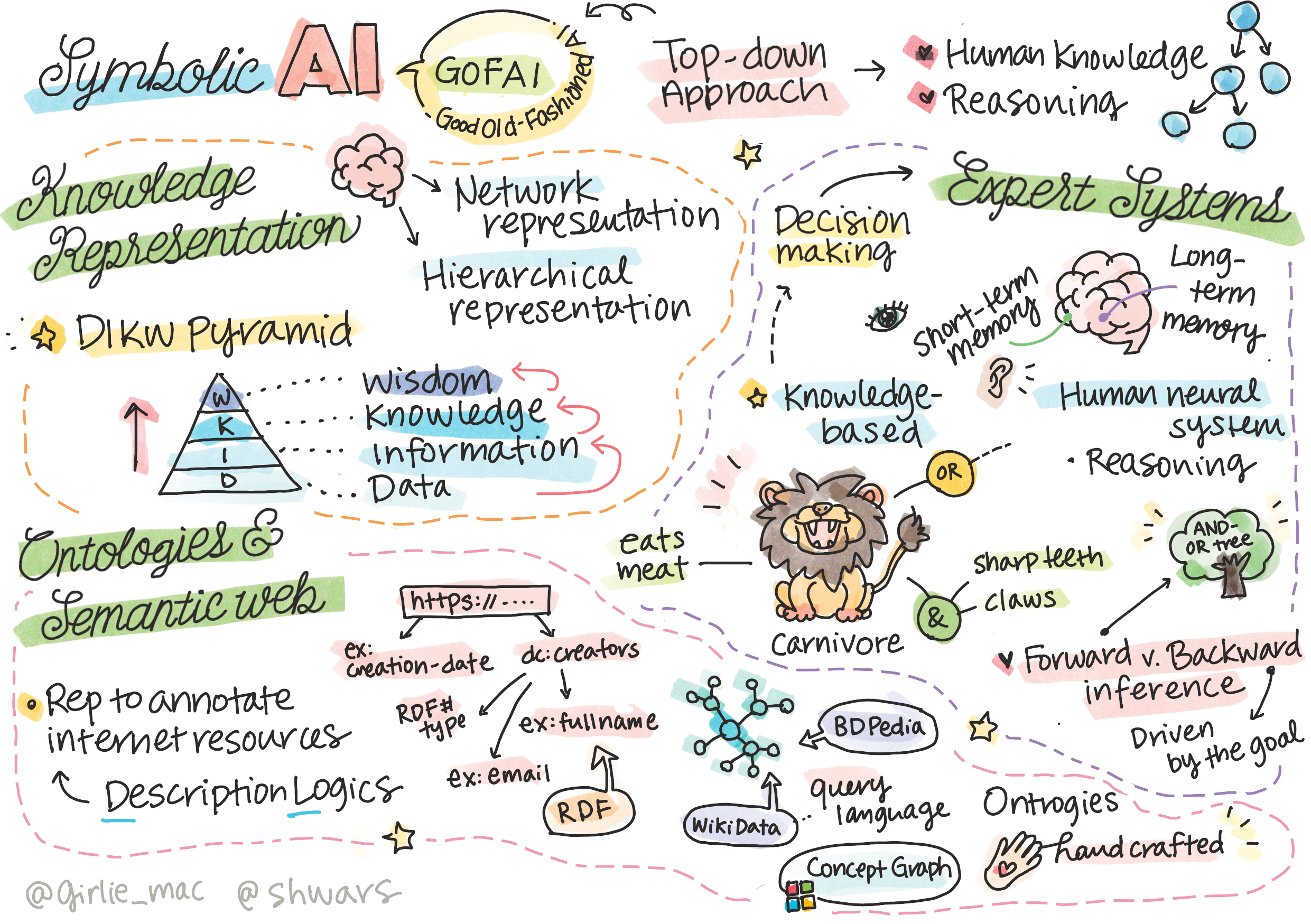
ყველაზე ხშირად, ჩვენ მკაცრად არ განვსაზღვრავთ ცოდნას, მაგრამ ვასწორებთ მას სხვა დაკავშირებულ ცნებებთან DIKW პირამიდა-ის გამოყენებით. იგი შეიცავს შემდეგ ცნებებს:
- მონაცემები არის ის, რაც წარმოდგენილია ფიზიკურ მედიაში, როგორიცაა წერილობითი ტექსტი ან სალაპარაკო სიტყვები. მონაცემები არსებობს ადამიანებისგან დამოუკიდებლად და შეიძლება გადაეცეს ადამიანებს შორის.
- ინფორმაცია არის ის, თუ როგორ განვიხილავთ მონაცემებს ჩვენს თავში. მაგალითად, როდესაც გვესმის სიტყვა კომპიუტერი, ჩვენ გვესმის, რა არის ეს.
- ცოდნა არის ინფორმაცია, რომელიც ინტეგრირებულია ჩვენს მსოფლიო მოდელში. მაგალითად, როგორც კი ვიგებთ რა არის კომპიუტერი, ვიწყებთ იდეების გააზრებას იმის შესახებ, თუ როგორ მუშაობს ის, რა ღირს და რისთვის შეიძლება მისი გამოყენება. ურთიერთდაკავშირებული ცნებების ეს ქსელი აყალიბებს ჩვენს ცოდნას.
- სიბრძნე არის სამყაროს ჩვენი გაგების კიდევ ერთი დონე და ის წარმოადგენს მეტა-ცოდნას, მაგ. გარკვეული წარმოდგენა იმის შესახებ, თუ როგორ და როდის უნდა იქნას გამოყენებული ცოდნა.
სურათი ვიკიპედიიდან, ავტორი Longlivetheux - საკუთარი ნამუშევარი, CC BY-SA 4.0
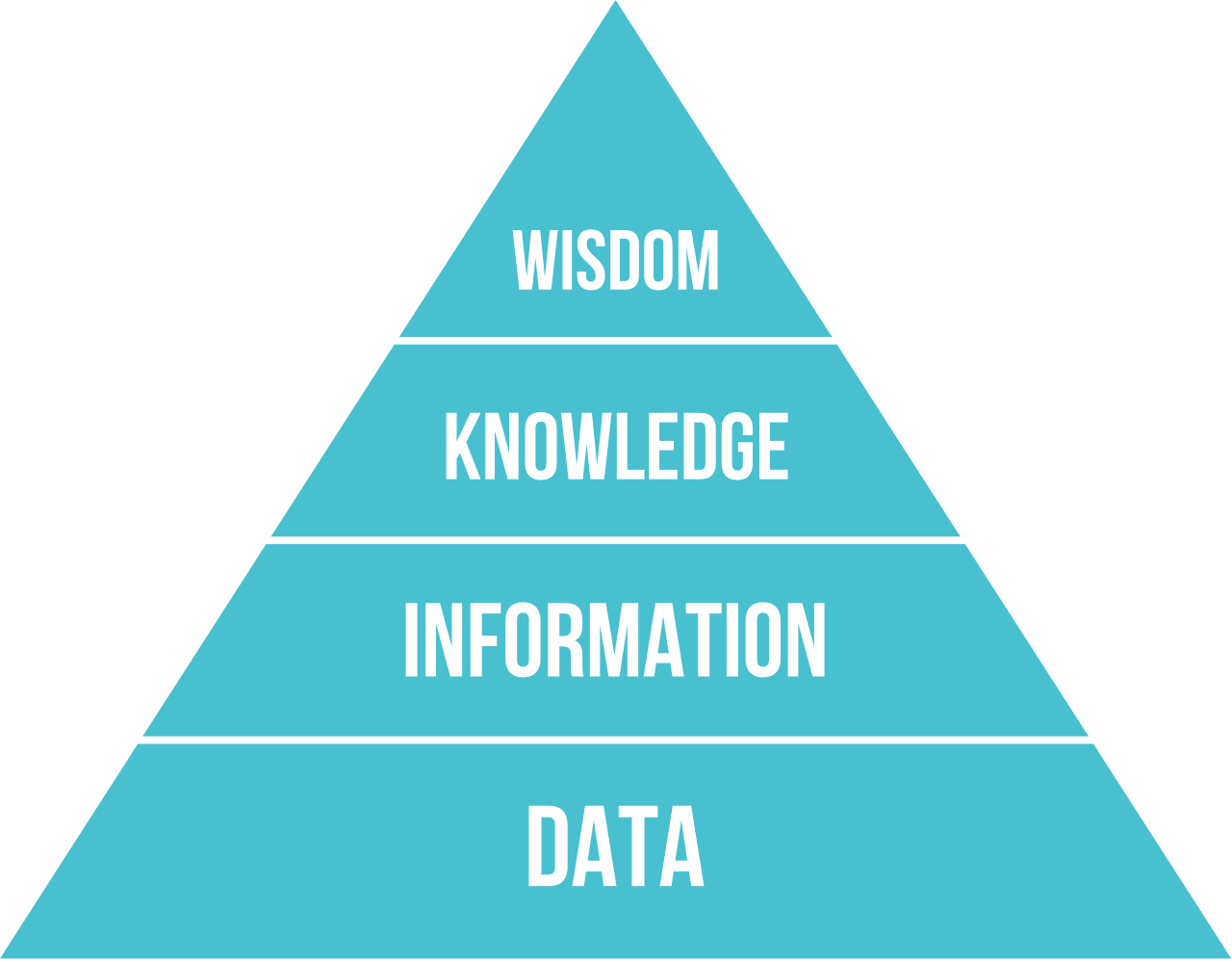
ამრიგად, ცოდნის წარმოდგენის პრობლემა არის კომპიუტერის შიგნით ცოდნის მონაცემების სახით წარმოდგენის ეფექტური გზების პოვნა, რათა ის ავტომატურად გამოსაყენებელი გახდეს. ეს შეიძლება ჩაითვალოს სპექტრის სახით:
სურათი დიმიტრი სოშნიკოვი-ის მიერ
- მარცხნივ არის ცოდნის წარმოდგენის ძალიან მარტივი ტიპები, რომლებიც შეიძლება ეფექტურად გამოიყენონ კომპიუტერებმა. უმარტივესი არის ალგორითმული, როდესაც ცოდნა წარმოდგენილია კომპიუტერული პროგრამით. თუმცა, ეს არ არის ცოდნის წარმოდგენის საუკეთესო გზა, რადგან ის არ არის მოქნილი. ჩვენს თავში ცოდნა ხშირად არაალგორითმულია.
- მარჯვნივ არის გამოსახულებები, როგორიცაა ბუნებრივი ტექსტი. ეს არის ყველაზე ძლიერი, მაგრამ არ შეიძლება გამოყენებულ იქნას ავტომატური მსჯელობისთვის.
ერთი წუთით დაფიქრდით, როგორ წარმოადგენთ ცოდნას თქვენს თავში და გადააკეთეთ იგი ნოტებად. არსებობს რაიმე კონკრეტული ფორმატი, რომელიც კარგად მუშაობს თქვენთვის, რათა დაგეხმაროთ შენარჩუნებაში?
კომპიუტერული ცოდნის რეპრეზენტაციების კლასიფიკაცია
ჩვენ შეგვიძლია დავყოთ კომპიუტერული ცოდნის წარმოდგენის სხვადასხვა მეთოდები შემდეგ კატეგორიებად:
- ქსელის წარმოდგენები ეფუძნება იმ ფაქტს, რომ ჩვენს თავში გვაქვს ურთიერთდაკავშირებული კონცეფციების ქსელი. ჩვენ შეგვიძლია ვცადოთ იგივე ქსელების რეპროდუცირება, როგორც გრაფიკი კომპიუტერის შიგნით - ეგრეთ წოდებული სემანტიკური ქსელი.
- ობიექტი-ატრიბუტი-მნიშვნელობის სამეულები ან ატრიბუტი-მნიშვნელობის წყვილები. ვინაიდან გრაფიკი შეიძლება წარმოდგენილი იყოს კომპიუტერის შიგნით, როგორც კვანძებისა და კიდეების სია, ჩვენ შეგვიძლია გამოვსახოთ სემანტიკური ქსელი სამეულების სიით, რომელიც შეიცავს ობიექტებს, ატრიბუტებს და მნიშვნელობებს. მაგალითად, ჩვენ ვაშენებთ შემდეგ სამეულებს პროგრამირების ენების შესახებ:
| ობიექტი | ატრიბუტი | ღირებულება |
|---|---|---|
| პითონი | არის | Untyped-Language |
| პითონი | გამოგონილი-ის მიერ | გვიდო ვან როსუმი |
| პითონი | ბლოკ-სინტაქსი | ჩაღრმავება |
| Untyped-Language | არ აქვს | ტიპის განმარტებები |
დაფიქრდით, როგორ შეიძლება ტრიპლეტების გამოყენება სხვა ტიპის ცოდნის წარმოსაჩენად.
- იერარქიული წარმოდგენები ხაზს უსვამს იმ ფაქტს, რომ ჩვენ ხშირად ვქმნით ობიექტების იერარქიას ჩვენს თავში. მაგალითად, ჩვენ ვიცით, რომ კანარა არის ჩიტი და ყველა ფრინველს აქვს ფრთები. ჩვენ ასევე გვაქვს გარკვეული წარმოდგენა იმაზე, თუ რა ფერისაა ჩვეულებრივ კანარი და როგორია მათი ფრენის სიჩქარე.
- ჩარჩოების წარმოდგენა ეფუძნება თითოეული ობიექტის ან ობიექტების კლასის ჩარჩოებად წარმოდგენას, რომელიც შეიცავს სლოტებს. სლოტებს აქვთ შესაძლო ნაგულისხმევი მნიშვნელობები, ღირებულების შეზღუდვები ან შენახული პროცედურები, რომელთა გამოძახება შესაძლებელია სლოტის მნიშვნელობის მისაღებად. ყველა ჩარჩო ქმნის იერარქიას, როგორც ობიექტის იერარქიას ობიექტზე ორიენტირებულ პროგრამირების ენებში.
- სცენარები არის სპეციალური ტიპის ჩარჩოები, რომლებიც წარმოადგენენ რთულ სიტუაციებს, რომლებიც შეიძლება განვითარდეს დროში.
პითონი
| სლოტი | ღირებულება | ნაგულისხმევი მნიშვნელობა | ინტერვალი |
|---|---|---|---|
| სახელი | პითონი | ||
| Is-A | Untyped-Language | ||
| ცვლადი საქმე | CamelCase | ||
| პროგრამის ხანგრძლივობა | 5-5000 ხაზი | ||
| ბლოკის სინტაქსი | შეწევა |
-
პროცედურული წარმოდგენები ეფუძნება ცოდნის წარმოდგენას იმ ქმედებების სიით, რომლებიც შეიძლება შესრულდეს, როდესაც ხდება გარკვეული პირობა.
- წარმოების წესები არის თუ-მაშინ განცხადებები, რომლებიც საშუალებას გვაძლევს გამოვიტანოთ დასკვნები. მაგალითად, ექიმს შეიძლება ჰქონდეს წესი, რომ თუ პაციენტს აქვს მაღალი სიცხე ან C-რეაქტიული ცილის მაღალი დონე სისხლის ანალიზში მაშინ მას აქვს ანთება. როგორც კი ერთ-ერთ პირობას წავაწყდებით, შეგვიძლია დასკვნის გაკეთება ანთების შესახებ და შემდეგ გამოვიყენოთ შემდგომ მსჯელობაში.
- ალგორითმები შეიძლება ჩაითვალოს პროცედურული წარმოდგენის სხვა ფორმად, თუმცა ისინი თითქმის არასოდეს გამოიყენება უშუალოდ ცოდნაზე დაფუძნებულ სისტემებში.
-
ლოგიკა თავდაპირველად შემოთავაზებული იყო არისტოტელეს მიერ, როგორც უნივერსალური ადამიანური ცოდნის წარმოდგენის საშუალება.
- პრედიკატის ლოგიკა, როგორც მათემატიკური თეორია, ზედმეტად მდიდარია გამოსათვლელად, ამიტომ მისი ზოგიერთი ქვეჯგუფი ჩვეულებრივ გამოიყენება, მაგალითად, პროლოგში გამოყენებული Horn პუნქტები.
- აღწერილობითი ლოგიკა არის ლოგიკური სისტემების ოჯახი, რომელიც გამოიყენება ობიექტების იერარქიის წარმოსაჩენად და მსჯელობის მიზნით, განაწილებული ცოდნის წარმოდგენების შესახებ, როგორიცაა სემანტიკური ვებ.
საექსპერტო სისტემები
სიმბოლური AIს ერთ-ერთი ადრეული წარმატება იყო ეგრეთ წოდებული ექსპერტული სისტემები - კომპიუტერული სისტემები, რომლებიც შექმნილია იმისთვის, რომ ემოქმედათ როგორც ექსპერტი გარკვეულ პრობლემურ სფეროებში. ისინი ეფუძნებოდა ცოდნის ბაზას, რომელიც ამოღებულ იქნა ერთი ან მეტი ადამიანის ექსპერტისგან, და ისინი შეიცავდნენ დასკვნის ძრავას, რომელიც ასრულებდა გარკვეულ მსჯელობას მის თავზე.
 |
| 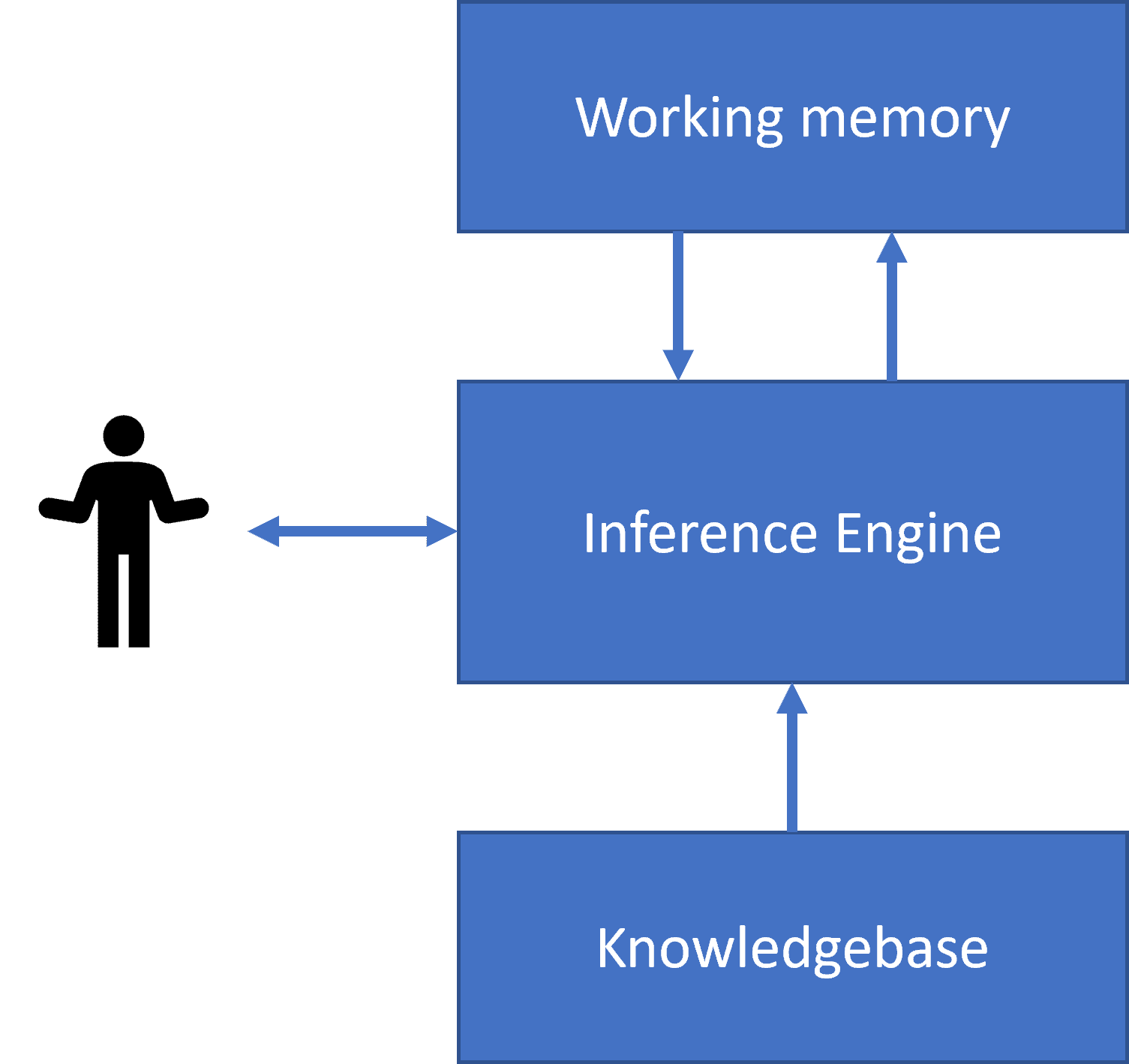
ადამიანის ნერვული სისტემის გამარტივებული სტრუქტურა | ცოდნაზე დაფუძნებული სისტემის არქიტექტურა
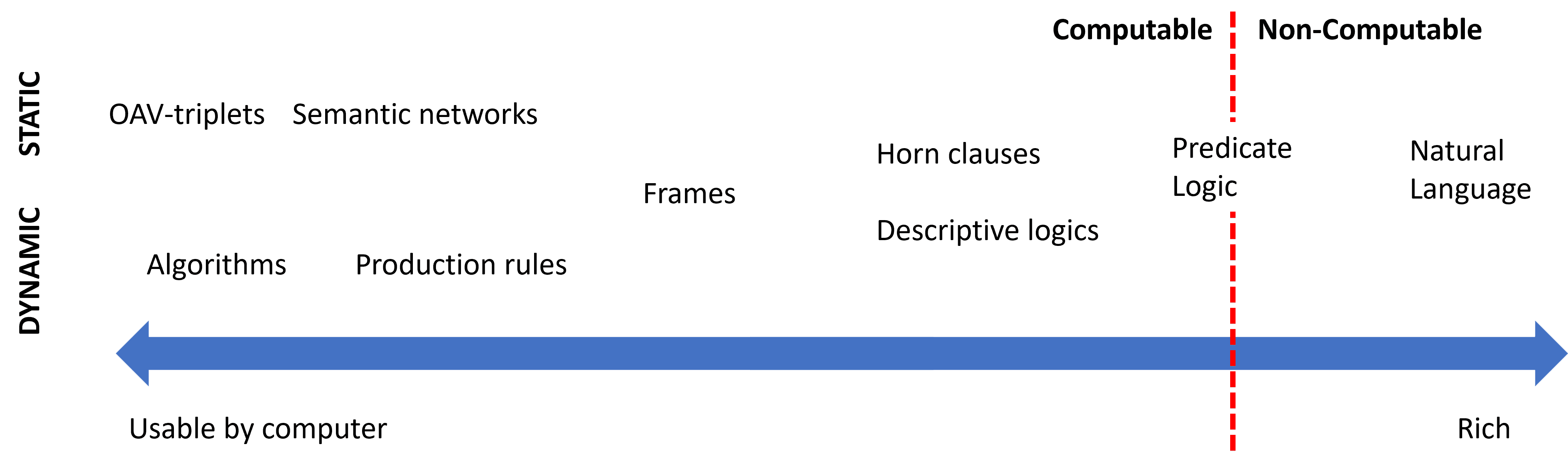
საექსპერტო სისტემები აგებულია ადამიანის მსჯელობის სისტემის მსგავსად, რომელიც შეიცავს მოკლევადიან მეხსიერებას და გრძელვადიან მეხსიერებას. ანალოგიურად, ცოდნაზე დაფუძნებულ სისტემებში ჩვენ გამოვყოფთ შემდეგ კომპონენტებს:
- პრობლემური მეხსიერება: შეიცავს ცოდნას ამჟამად მოგვარებული პრობლემის შესახებ, ანუ პაციენტის ტემპერატურაზე ან არტერიულ წნევაზე, აქვს თუ არა მას ანთება და ა.შ. ამ ცოდნას ასევე უწოდებენ სტატიკური ცოდნა, რადგან ის შეიცავს კადრს, რაც ამჟამად ვიცით პრობლემის შესახებ - ე.წ. პრობლემური მდგომარეობა.
- ცოდნის ბაზა: წარმოადგენს გრძელვადიან ცოდნას პრობლემის დომენის შესახებ. იგი ამოღებულია ხელით ადამიანის ექსპერტებისგან და არ იცვლება კონსულტაციებიდან კონსულტაციამდე. იმის გამო, რომ ის საშუალებას გვაძლევს გადავიდეთ ერთი პრობლემური მდგომარეობიდან მეორეში, მას ასევე უწოდებენ დინამიურ ცოდნას.
- დასკვნის ძრავა: ორკესტრირებს პრობლემის მდგომარეობის სივრცეში ძიების მთელ პროცესს, საჭიროების შემთხვევაში მომხმარებლისთვის კითხვების დასმას. ის ასევე პასუხისმგებელია თითოეული სახელმწიფოსთვის გამოსაყენებელი სწორი წესების პოვნაზე.
მაგალითად, განვიხილოთ ცხოველის ფიზიკური მახასიათებლების მიხედვით განსაზღვრის შემდეგი საექსპერტო სისტემა:
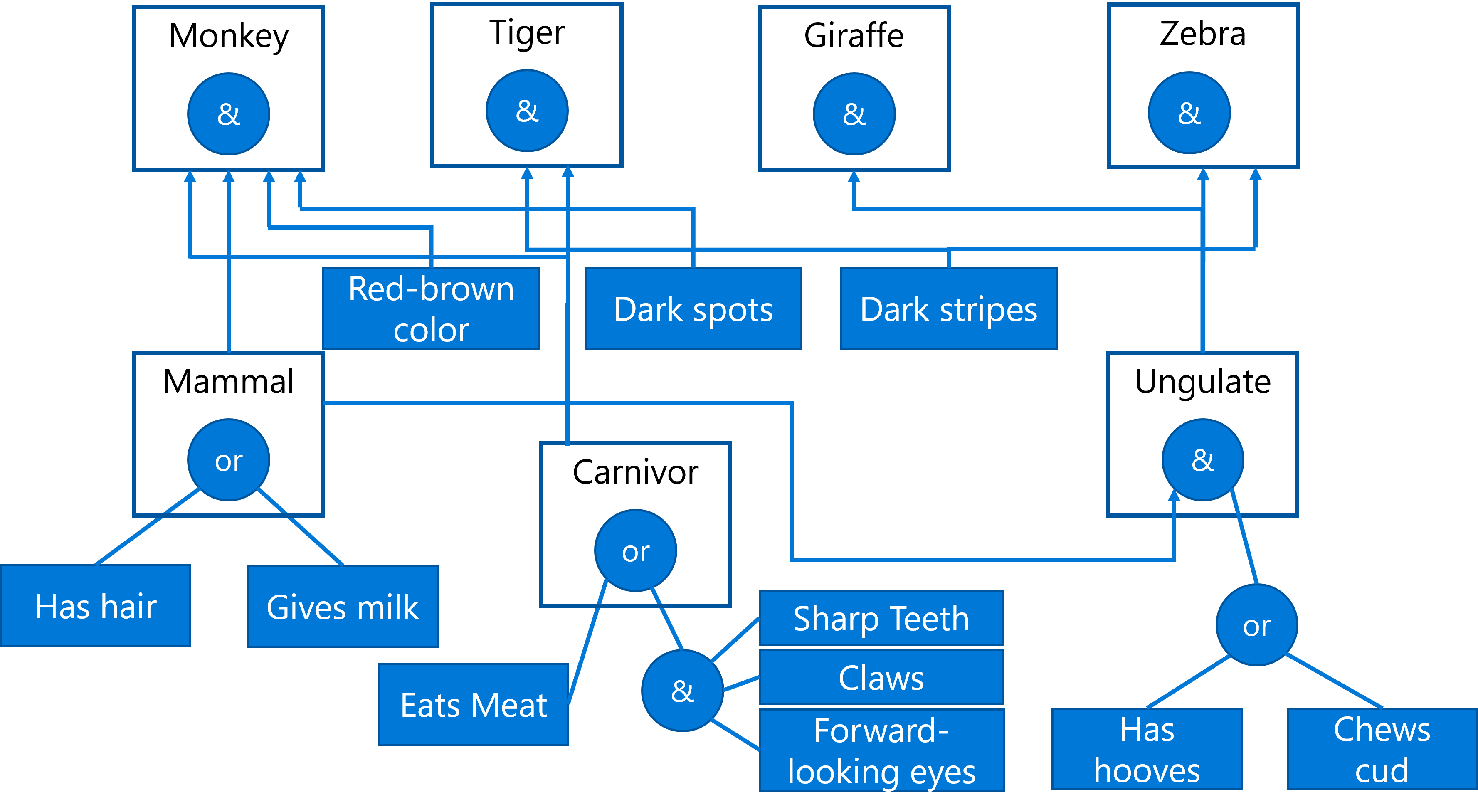
სურათი დიმიტრი სოშნიკოვი-ის მიერ
ამ დიაგრამას ეწოდება AND-OR ხე და ეს არის წარმოების წესების ნაკრების გრაფიკული წარმოდგენა. ხის დახატვა სასარგებლოა ექსპერტისგან ცოდნის მოპოვების დასაწყისში. კომპიუტერის შიგნით ცოდნის წარმოსაჩენად უფრო მოსახერხებელია წესების გამოყენება:
იტვირთება…თქვენ შეგიძლიათ შეამჩნიოთ, რომ წესის მარცხენა მხარეს თითოეული პირობა და მოქმედება არსებითად არის ობიექტი-ატრიბუტი-მნიშვნელობის (OAV) სამეული. სამუშაო მეხსიერება შეიცავს OAV ტრიპლეტების კომპლექტს, რომელიც შეესაბამება ამჟამად მოგვარებულ პრობლემას. წესების ძრავა ეძებს წესებს, რომლებისთვისაც პირობა დაკმაყოფილებულია და იყენებს მათ, ამატებს კიდევ ერთ სამეულს სამუშაო მეხსიერებაში.
დაწერეთ თქვენი საკუთარი AND-OR ხე თქვენთვის მოსაწონ თემაზე!
წინ და უკან დასკვნა
ზემოთ აღწერილ პროცესს ეწოდება წინა დასკვნა. ის იწყება სამუშაო მეხსიერებაში არსებული პრობლემის შესახებ თავდაპირველი მონაცემებით და შემდეგ ახორციელებს შემდეგ მსჯელობას:
- თუ სამიზნე ატრიბუტი იმყოფება მუშა მეხსიერებაში - შეჩერდით და მიეცით შედეგი
- მოძებნეთ ყველა ის წესი, რომლის პირობაც ამჟამად დაკმაყოფილებულია - მიიღეთ კონფლიქტური კომპლექტი წესები.
- შეასრულეთ კონფლიქტის მოგვარება - აირჩიეთ ერთი წესი, რომელიც შესრულდება ამ საფეხურზე. კონფლიქტის მოგვარების სხვადასხვა სტრატეგია შეიძლება იყოს:
- აირჩიეთ პირველი მოქმედი წესი ცოდნის ბაზაში
- აირჩიეთ შემთხვევითი წესი
- აირჩიეთ უფრო კონკრეტული წესი, ანუ ის, ვინც აკმაყოფილებს ყველაზე მეტ პირობებს "მარცხენა მხარეს" (LHS)
- გამოიყენეთ შერჩეული წესი და ჩადეთ ახალი ცოდნის ნაწილი პრობლემის მდგომარეობაში
- გაიმეორეთ ნაბიჯი 1-დან.
თუმცა, ზოგიერთ შემთხვევაში შეიძლება გვსურს დავიწყოთ პრობლემის შესახებ ცარიელი ცოდნით და დავსვათ კითხვები, რომლებიც დაგვეხმარება დასკვნის გაკეთებაში. მაგალითად, სამედიცინო დიაგნოსტიკის კეთებისას, როგორც წესი, პაციენტის დიაგნოსტიკის დაწყებამდე წინასწარ არ ვაკეთებთ ყველა სამედიცინო ანალიზს. ჩვენ უფრო გვსურს ანალიზის გაკეთება, როცა გადაწყვეტილების მიღებაა საჭირო.
ამ პროცესის მოდელირება შესაძლებელია უკან დასკვნის გამოყენებით. მას ამოძრავებს მიზანი - ატრიბუტის მნიშვნელობა, რომელსაც ჩვენ ვეძებთ:
- აირჩიეთ ყველა წესი, რომელსაც შეუძლია მოგვცეს მიზნის მნიშვნელობა (ანუ RHS-ზე მიზნით ("მარჯვნივ")) - კონფლიქტის ნაკრები.
- თუ ამ ატრიბუტის წესები არ არსებობს, ან არსებობს წესი, რომ ჩვენ უნდა მოვითხოვოთ ღირებულება მომხმარებლისგან - მოითხოვეთ იგი, წინააღმდეგ შემთხვევაში:
- გამოიყენეთ კონფლიქტის მოგვარების სტრატეგია, რათა აირჩიოთ ერთი წესი, რომელსაც გამოვიყენებთ როგორც ჰიპოთეზა - შევეცდებით ამის დამტკიცებას
- განმეორებით გაიმეორეთ პროცესი წესების LHS-ში ყველა ატრიბუტისთვის, შეეცადეთ დაამტკიცოთ ისინი, როგორც მიზნები
- თუ ნებისმიერ მომენტში პროცესი ვერ მოხერხდა - გამოიყენეთ სხვა წესი მე-3 საფეხურზე.
რომელ სიტუაციებში უფრო მიზანშეწონილია წინსვლის დასკვნა? რაც შეეხება უკან დასკვნას?
საექსპერტო სისტემების დანერგვა
საექსპერტო სისტემები შეიძლება განხორციელდეს სხვადასხვა ინსტრუმენტების გამოყენებით:
- მათი დაპროგრამება პირდაპირ რომელიმე მაღალი დონის პროგრამირების ენაზე. ეს არ არის საუკეთესო იდეა, რადგან ცოდნაზე დაფუძნებული სისტემის მთავარი უპირატესობა არის ის, რომ ცოდნა განცალკევებულია დასკვნისგან და პოტენციურად პრობლემის სფეროს ექსპერტს უნდა შეეძლოს წესების დაწერა დასკვნის პროცესის დეტალების გააზრების გარეშე.
- ექსპერტი სისტემების ჭურვის გამოყენება, ანუ სისტემა, რომელიც სპეციალურად შექმნილია ცოდნით დაკომპლექტებული ცოდნის გამომსახველი ენის გამოყენებით.
სავარჯიშო: ცხოველთა დასკვნა
იხილეთ ცხოველები.ipynb წინა და უკანა დასკვნის ექსპერტის სისტემის დანერგვის მაგალითი.
შენიშვნა: ეს მაგალითი საკმაოდ მარტივია და მხოლოდ წარმოდგენას იძლევა იმის შესახებ, თუ როგორ გამოიყურება ექსპერტი სისტემა. როდესაც დაიწყებთ ასეთი სისტემის შექმნას, თქვენ შეამჩნევთ მისგან გარკვეულ ინტელექტუალურ ქცევას მას შემდეგ, რაც მიაღწევთ გარკვეულ წესებს, დაახლოებით 200+. რაღაც მომენტში წესები ზედმეტად რთული ხდება ყველა მათგანის გასათვალისწინებლად და ამ მომენტში შეიძლება გაინტერესოთ, რატომ იღებს სისტემა გარკვეულ გადაწყვეტილებებს. თუმცა, ცოდნაზე დაფუძნებული სისტემების მნიშვნელოვანი მახასიათებელია ის, რომ თქვენ ყოველთვის შეგიძლიათ ახსნათ ზუსტად როგორ იქნა მიღებული რომელიმე გადაწყვეტილება.
ონტოლოგია და სემანტიკური ქსელი
მე-20 საუკუნის ბოლოს გაჩნდა ინიციატივა გამოეყენებინათ ცოდნის წარმოდგენა ინტერნეტ რესურსების ანოტაციისთვის, რათა შესაძლებელი ყოფილიყო რესურსების მოძიება, რომლებიც შეესაბამება ძალიან კონკრეტულ შეკითხვებს. ამ მოძრაობას ეწოდა სემანტიკური ვებ და იგი ეყრდნობოდა რამდენიმე კონცეფციას:
- სპეციალური ცოდნის წარმოდგენა აღწერილობის ლოგიკა (DL) საფუძველზე. ის ჰგავს ჩარჩოს ცოდნის წარმოდგენას, რადგან აშენებს ობიექტების იერარქიას თვისებებით, მაგრამ აქვს ფორმალური ლოგიკური სემანტიკა და დასკვნა. არსებობს DL-ების მთელი ოჯახი, რომელიც აბალანსებს ექსპრესიულობასა და დასკვნის ალგორითმულ სირთულეს შორის.
- განაწილებული ცოდნის წარმოდგენა, სადაც ყველა კონცეფცია წარმოდგენილია გლობალური URI იდენტიფიკატორით, რაც შესაძლებელს ხდის შექმნას ცოდნის იერარქია, რომელიც მოიცავს ინტერნეტს.
- XML-ზე დაფუძნებული ენების ოჯახი ცოდნის აღწერისთვის: RDF (Resource Description Framework), RDFS (RDF Schema), OWL (Ontology Web Language).
სემანტიკური ქსელის ძირითადი კონცეფცია არის ონტოლოგიის კონცეფცია. ეს ეხება პრობლემის დომენის მკაფიო დაზუსტებას ცოდნის ფორმალური წარმოდგენის გამოყენებით. უმარტივესი ონტოლოგია შეიძლება იყოს მხოლოდ ობიექტების იერარქია პრობლემის დომენში, მაგრამ უფრო რთული ონტოლოგია მოიცავს წესებს, რომლებიც შეიძლება გამოყენებულ იქნას დასკვნისთვის.
სემანტიკურ ქსელში ყველა წარმოდგენა ეფუძნება სამეულს. თითოეული ობიექტი და თითოეული მიმართება ცალსახად იდენტიფიცირებულია URI-ით. მაგალითად, თუ გვსურს განვაცხადოთ ის ფაქტი, რომ AIს ეს სასწავლო გეგმა შემუშავებულია დიმიტრი სოშნიკოვის მიერ 2022 წლის 1 იანვარს - აქ არის სამეული, რომელიც შეგვიძლია გამოვიყენოთ:
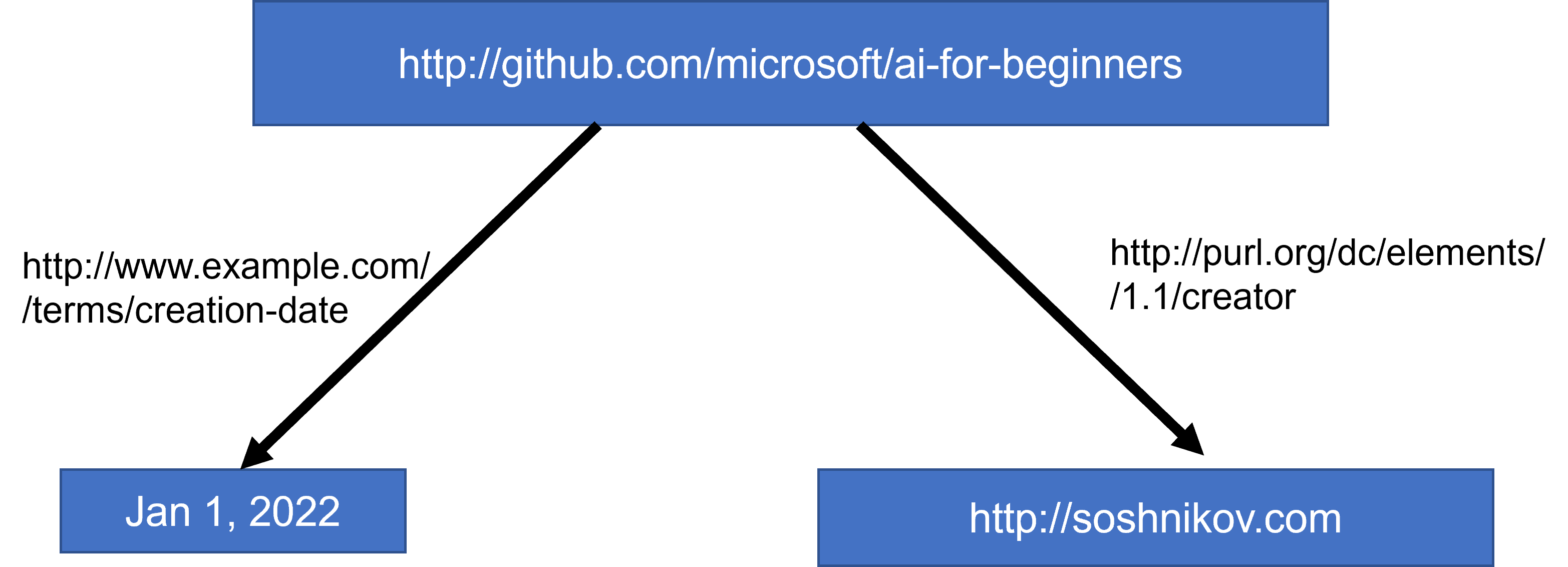
იტვირთება…აქ
http://www.example.com/terms/creation-dateდაhttp://purl.org/dc/elements/1.1/creatorარის რამდენიმე ცნობილი და საყოველთაოდ მიღებული URI, რათა გამოხატონ შემქმნელი და შექმნის თარიღი ცნებები.
უფრო რთულ შემთხვევაში, თუ გვსურს განვსაზღვროთ შემქმნელთა სია, შეგვიძლია გამოვიყენოთ RDF-ში განსაზღვრული მონაცემთა ზოგიერთი სტრუქტურა.
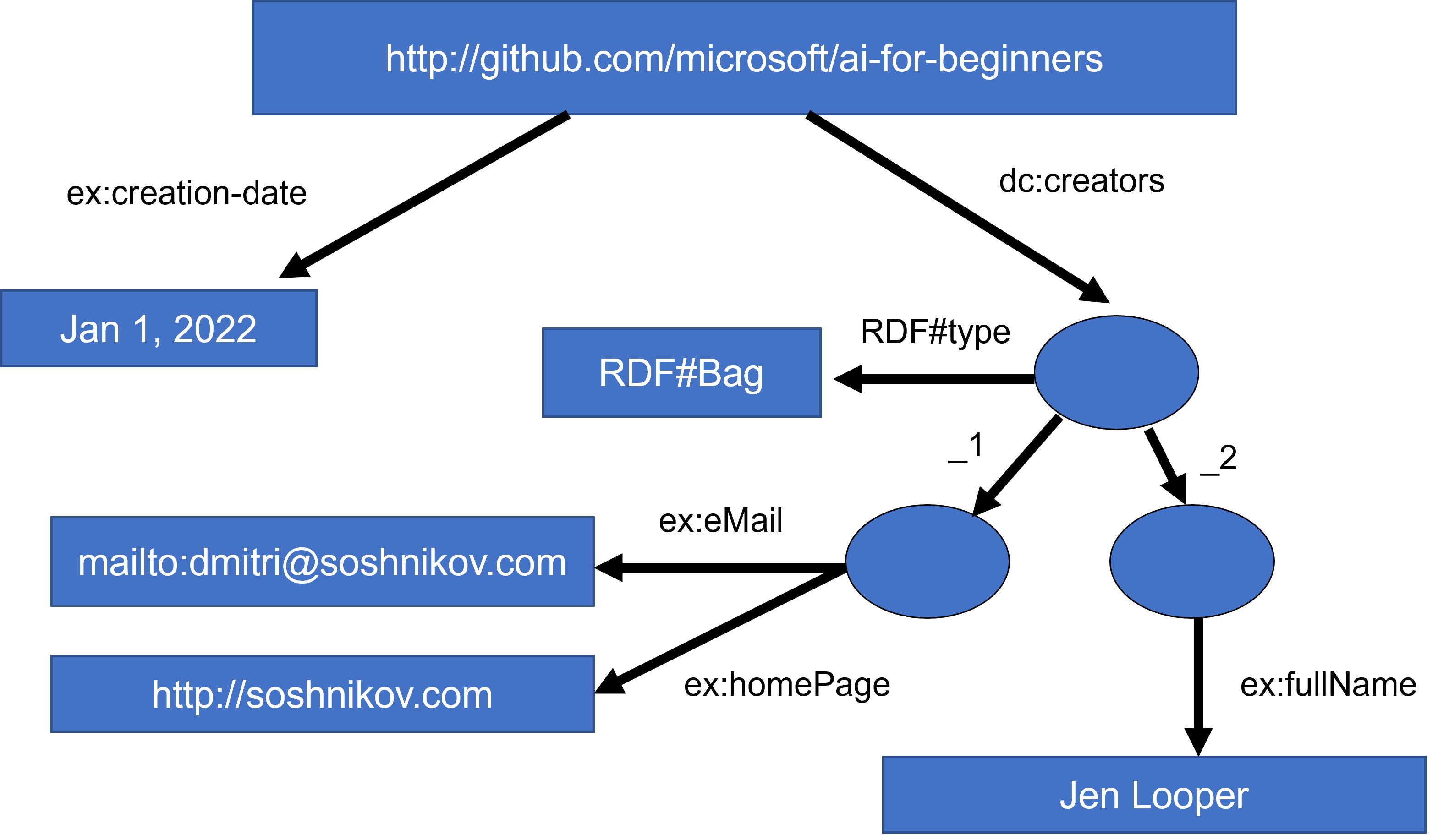
დიაგრამები ზემოთ დიმიტრი სოშნიკოვი-ის მიერ
სემანტიკური ვებსაიტის აგების პროგრესი გარკვეულწილად შეანელა საძიებო სისტემებისა და ბუნებრივი ენის დამუშავების ტექნიკის წარმატებით, რაც საშუალებას იძლევა ტექსტიდან სტრუქტურირებული მონაცემების ამოღება. თუმცა, ზოგიერთ სფეროში ჯერ კიდევ არის მნიშვნელოვანი ძალისხმევა ონტოლოგიებისა და ცოდნის ბაზების შესანარჩუნებლად. აღსანიშნავია რამდენიმე პროექტი:
- ვიკიმონაცემები არის მანქანით წაკითხვადი ცოდნის ბაზების კოლექცია, რომელიც დაკავშირებულია ვიკიპედიასთან. მონაცემების უმეტესობა მოპოვებულია ვიკიპედიიდან Infoboxes, სტრუქტურირებული შინაარსის ნაწილი ვიკიპედიის გვერდებზე. შეგიძლიათ შეკითხვა ვიკიმონაცემები SPARQL-ში, სემანტიკური ვებსაიტის შეკითხვის სპეციალურ ენაზე. აქ არის შეკითხვის ნიმუში, რომელიც აჩვენებს ყველაზე პოპულარულ თვალის ფერებს ადამიანებში:
იტვირთება…- DBpedia არის კიდევ ერთი მცდელობა WikiData-ს მსგავსი.
თუ გსურთ ექსპერიმენტი ჩაატაროთ საკუთარი ონტოლოგიების შექმნაზე, ან გახსნათ არსებული, არსებობს შესანიშნავი ვიზუალური ონტოლოგიის რედაქტორი, სახელწოდებით პროტეჟე. ჩამოტვირთეთ, ან გამოიყენეთ იგი ონლაინ.
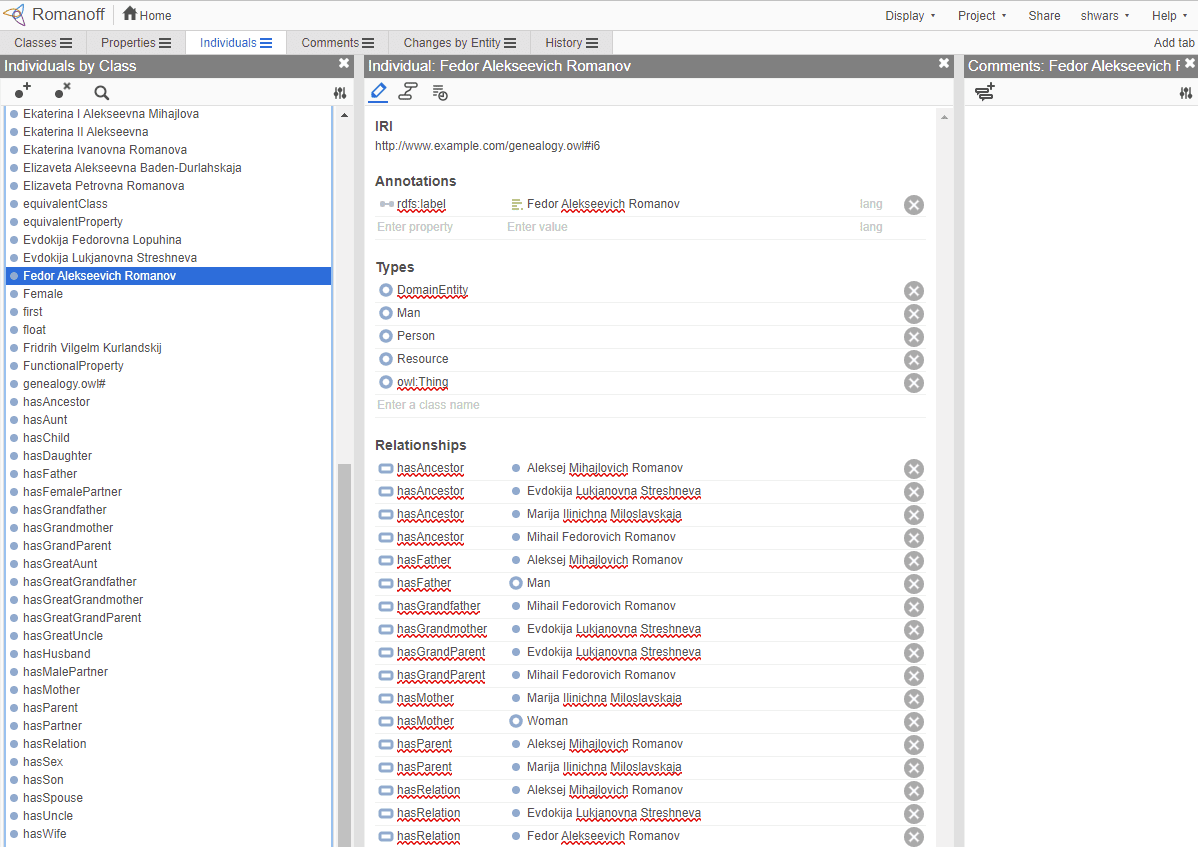
Web Protégé რედაქტორი გახსნილია რომანოვების ოჯახის ონტოლოგიით. სკრინშოტი: დიმიტრი სოშნიკოვი
სავარჯიშო: ოჯახის ონტოლოგია
იხილეთ FamilyOntology.ipynb სემანტიკური ვებ-ტექნიკის გამოყენების მაგალითი ოჯახური ურთიერთობების შესახებ მსჯელობისთვის. ჩვენ ავიღებთ ოჯახის ხეს, რომელიც წარმოდგენილია საერთო GEDCOM ფორმატში და ოჯახური ურთიერთობების ონტოლოგიაში და ავაშენებთ ყველა ოჯახური ურთიერთობის გრაფიკს ინდივიდთა მოცემული ნაკრებისთვის.
Microsoft-ის კონცეფციის გრაფიკი
უმეტეს შემთხვევაში, ონტოლოგიები საგულდაგულოდ იქმნება ხელით. თუმცა, ასევე შესაძლებელია ონტოლოგიების მოპოვება არასტრუქტურირებული მონაცემებიდან, მაგალითად, ბუნებრივი ენის ტექსტებიდან.
ერთი ასეთი მცდელობა განხორციელდა Microsoft Research-ის მიერ და შედეგად Microsoft-ის კონცეფციის გრაფიკი.
ეს არის ერთეულების დიდი კოლექცია, რომლებიც დაჯგუფებულია is-a მემკვიდრეობითი ურთიერთობის გამოყენებით. ის საშუალებას გაძლევთ უპასუხოთ კითხვებს, როგორიცაა "რა არის Microsoft?" - პასუხი არის მსგავსი "კომპანია, რომლის ალბათობაა 0.87 და ბრენდი ალბათობით 0.75".
გრაფიკი ხელმისაწვდომია როგორც REST API, ან როგორც დიდი გადმოსაწერი ტექსტური ფაილი, რომელიც ჩამოთვლის ყველა ერთეულ წყვილს.
სავარჯიშო: კონცეფციის გრაფიკი
სცადეთ MSConceptGraph.ipynb ნოუთბუქი, რათა ნახოთ, როგორ გამოვიყენოთ Microsoft Concept Graph ახალი ამბების სტატიების რამდენიმე კატეგორიად დასაჯგუფებლად.
დასკვნა
დღესდღეობით, AI ხშირად განიხილება მანქანური სწავლების ან ნერვული ქსელების სინონიმად. თუმცა, ადამიანი ასევე ავლენს აშკარა მსჯელობას, რასაც ამჟამად ნერვული ქსელები არ ამუშავებს. რეალური სამყაროს პროექტებში, აშკარა მსჯელობა კვლავ გამოიყენება იმ ამოცანების შესასრულებლად, რომლებიც საჭიროებს ახსნა-განმარტებებს, ან სისტემის ქცევის კონტროლირებადი გზით შეცვლას.
გამოწვევა
ამ გაკვეთილთან დაკავშირებულ საოჯახო ონტოლოგიის რვეულში არის ექსპერიმენტების შესაძლებლობა სხვა ოჯახურ ურთიერთობებზე. შეეცადეთ აღმოაჩინოთ ახალი კავშირები ადამიანებს შორის ოჯახის ხეზე.
ლექციის შემდგომი ვიქტორინა
მიმოხილვა და თვითშესწავლა
ჩაატარეთ კვლევა ინტერნეტში, რათა აღმოაჩინოთ ის სფეროები, სადაც ადამიანები ცდილობდნენ ცოდნის რაოდენობრივ და კოდირებას. გადახედეთ ბლუმის ტაქსონომიას და დაბრუნდით ისტორიაში, რათა გაიგოთ, თუ როგორ ცდილობდნენ ადამიანები თავიანთი სამყაროს გაგებას. გამოიკვლიეთ ლინეუსის ნამუშევარი ორგანიზმების ტაქსონომიის შესაქმნელად და დააკვირდით, როგორ შექმნა დიმიტრი მენდელეევმა ქიმიური ელემენტების აღწერა და დაჯგუფება. კიდევ რა საინტერესო მაგალითები შეგიძლიათ იპოვოთ?