ამ განყოფილებაში ჩვენ ყურადღებას გავამახვილებთ ნერვული ქსელების გამოყენებაზე ბუნებრივი ენის დამუშავებასთან (NLP) დავალებების შესასრულებლად. არსებობს მრავალი NLP პრობლემა, რომელთა გადაჭრაც ჩვენ გვინდა, რომ კომპიუტერებმა შეძლონ:
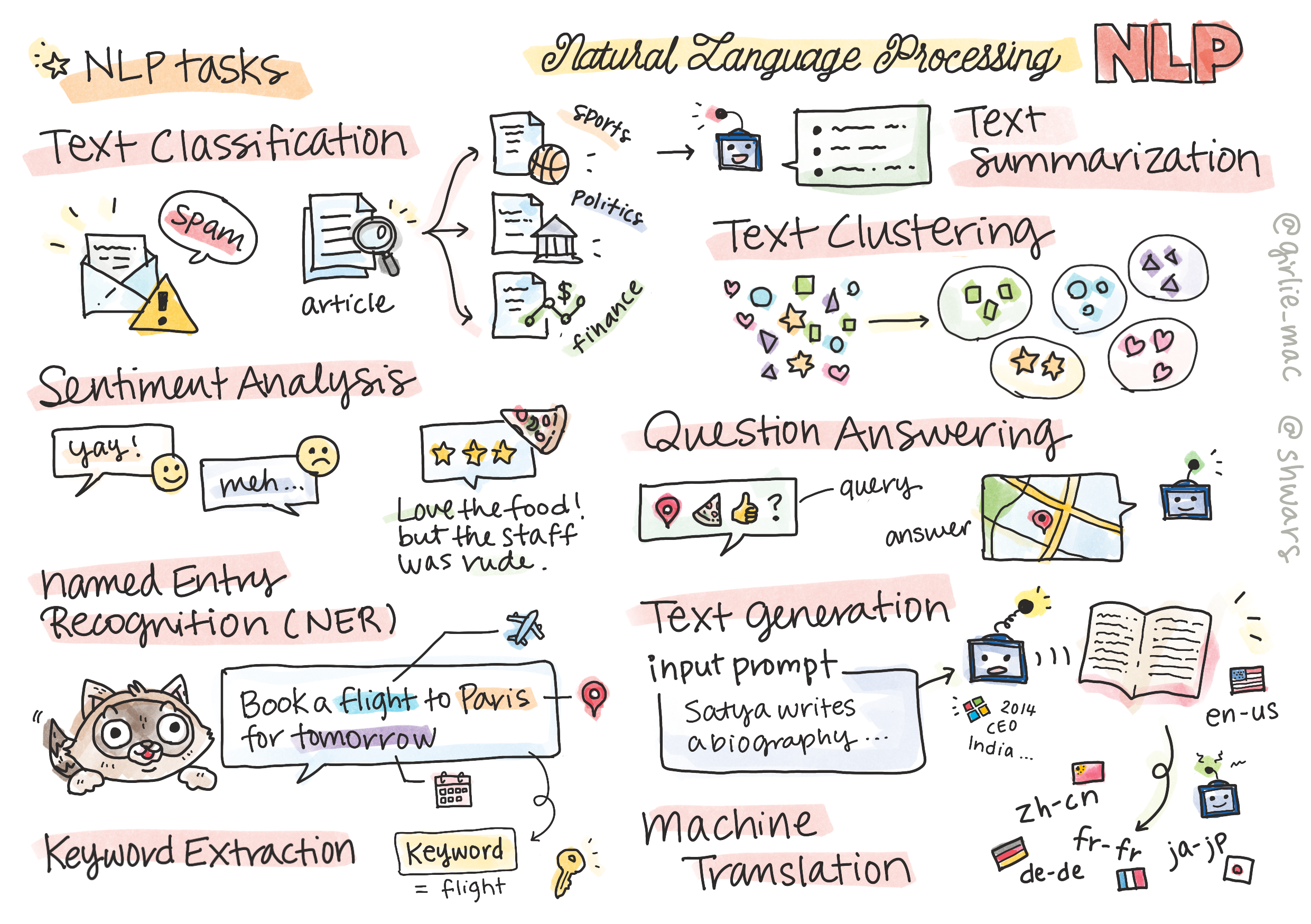
- ტექსტის კლასიფიკაცია არის ტიპიური კლასიფიკაციის პრობლემა, რომელიც ეხება ტექსტის თანმიმდევრობებს. მაგალითები მოიცავს ელ.ფოსტის შეტყობინებების კლასიფიკაციას, როგორც სპამს და არა სპამს, ან სტატიების კატეგორიზაციას, როგორც სპორტს, ბიზნესს, პოლიტიკას და ა.შ. ასევე, ჩეთის ბოტების შემუშავებისას, ხშირად გვჭირდება იმის გაგება, რისი თქმა სურდა მომხმარებელს -- ამ შემთხვევაში საქმე გვაქვს განზრახვის კლასიფიკაციასთან. ხშირად, განზრახვის კლასიფიკაციაში ბევრ კატეგორიასთან გვჭირდება საქმე.
- სენტიმენტის ანალიზი არის ტიპიური რეგრესიის პრობლემა, სადაც უნდა მივწეროთ რიცხვი (სენტიმენტი), რომელიც შეესაბამება თუ რამდენად დადებითი/უარყოფითია წინადადების მნიშვნელობა. სენტიმენტის ანალიზის უფრო მოწინავე ვერსიაა ასპექტზე დაფუძნებული სენტიმენტის ანალიზი (ABSA), სადაც სენტიმენტს მივაკუთვნებთ არა მთელ წინადადებას, არამედ მის სხვადასხვა ნაწილს (ასპექტებს), მაგ. ამ რესტორანში მომეწონა სამზარეულო, მაგრამ საშინელი ატმოსფერო იყო.
- Named Entity Recognition (NER) ეხება ტექსტიდან გარკვეული ერთეულების ამოღების პრობლემას. მაგალითად, შეიძლება დაგვჭირდეს იმის გაგება, რომ ფრაზაში მე უნდა გავფრინდე პარიზში ხვალ სიტყვა ხვალ აღნიშნავს DATE-ს, ხოლო პარიზი არის LOCATION.
- საკვანძო სიტყვების ამოღება NER-ის მსგავსია, მაგრამ ჩვენ გვჭირდება წინადადების მნიშვნელობისთვის მნიშვნელოვანი სიტყვების ამოღება ავტომატურად, კონკრეტული ერთეულის ტიპებისთვის წინასწარი მომზადების გარეშე.
- ტექსტის დაჯგუფება შეიძლება სასარგებლო იყოს, როდესაც გვსურს მსგავსი წინადადებების დაჯგუფება, მაგალითად, მსგავსი მოთხოვნები ტექნიკური დახმარების საუბრებში.
- კითხვაზე პასუხის გაცემა ეხება მოდელის უნარს უპასუხოს კონკრეტულ კითხვას. მოდელი იღებს ტექსტურ პასაჟს და კითხვას, როგორც შეყვანის სახით, და მან უნდა უზრუნველყოს ადგილი ტექსტში, სადაც არის კითხვაზე პასუხი (ან, ზოგჯერ, პასუხის ტექსტის გენერირება).
- ტექსტის გენერაცია არის მოდელის შესაძლებლობა შექმნას ახალი ტექსტი. ის შეიძლება ჩაითვალოს კლასიფიკაციის ამოცანად, რომელიც წინასწარმეტყველებს შემდეგ ასოს/სიტყვას ზოგიერთი ტექსტური მოთხოვნის საფუძველზე. ტექსტის გენერირების გაფართოებულ მოდელებს, როგორიცაა GPT-3, შეუძლიათ სხვა NLP ამოცანების გადაჭრა, როგორიცაა კლასიფიკაცია ტექნიკის გამოყენებით, სახელწოდებით სწრაფი პროგრამირება ან სწრაფი ინჟინერია
- ტექსტის შეჯამება არის ტექნიკა, როდესაც გვინდა კომპიუტერმა „წაიკითხოს“ გრძელი ტექსტი და შეაჯამოს რამდენიმე წინადადებაში.
- მანქანური თარგმანი შეიძლება განიხილებოდეს როგორც ტექსტის გაგების კომბინაცია ერთ ენაზე და ტექსტის გენერირება მეორე ენაზე.
თავდაპირველად, NLP ამოცანების უმეტესობა გადაწყდა ტრადიციული მეთოდების გამოყენებით, როგორიცაა გრამატიკა. მაგალითად, მანქანურ თარგმანში გამოიყენებოდა პარსერები საწყისი წინადადების სინტაქსურ ხედ გადასაქცევად, შემდეგ უფრო მაღალი დონის სემანტიკური სტრუქტურები იქნა ამოღებული წინადადების მნიშვნელობის წარმოსაჩენად და ამ მნიშვნელობისა და სამიზნე ენის გრამატიკის საფუძველზე წარმოიქმნა შედეგი. დღესდღეობით, ბევრი NLP ამოცანა უფრო ეფექტურად წყდება ნერვული ქსელების გამოყენებით.
ბევრი კლასიკური NLP მეთოდი დანერგილია ბუნებრივი ენის დამუშავების ხელსაწყოები (NLTK) Python ბიბლიოთეკაში. არსებობს შესანიშნავი NLTK წიგნი ხელმისაწვდომი ონლაინ, რომელიც მოიცავს, თუ როგორ შეიძლება სხვადასხვა NLP ამოცანების გადაჭრა NLTK-ის გამოყენებით.
ჩვენს კურსში ძირითადად ყურადღებას გავამახვილებთ ნერვული ქსელების გამოყენებაზე NLP-სთვის და გამოვიყენებთ NLTK-ს სადაც საჭიროა.
ჩვენ უკვე ვისწავლეთ ნეირონული ქსელების გამოყენება ტაბულურ მონაცემებთან და სურათებთან მუშაობისთვის. ამ ტიპის მონაცემებსა და ტექსტს შორის მთავარი განსხვავება ისაა, რომ ტექსტი არის ცვლადი სიგრძის თანმიმდევრობა, ხოლო სურათების შეყვანის ზომა წინასწარ არის ცნობილი. მიუხედავად იმისა, რომ კონვოლუციურ ქსელებს შეუძლიათ შაბლონების ამოღება შეყვანის მონაცემებიდან, ტექსტში შაბლონები უფრო რთულია. მაგ., შეიძლება ბევრი სიტყვისთვის სუბიექტისგან განცალკევება თვითნებური იყოს (მაგ. არ მიყვარს ფორთოხალი წინააღმდეგ არ მომწონს ეს დიდი ფერადი გემრიელი ფორთოხალი), და ეს მაინც უნდა იქნას ინტერპრეტირებული როგორც ერთი ნიმუში. ამრიგად, ენის დასამუშავებლად, ჩვენ უნდა შემოვიტანოთ ახალი ნერვული ქსელის ტიპები, როგორიცაა განმეორებადი ქსელები და ტრანსფორმატორები.
დააინსტალირეთ ბიბლიოთეკები
თუ ამ კურსის გასაშვებად იყენებთ ლოკალურ პითონის ინსტალაციას, შეიძლება დაგჭირდეთ NLP-სთვის საჭირო ყველა ბიბლიოთეკის დაყენება შემდეგი ბრძანებების გამოყენებით:
PyTorch-ისთვისbash pip install -r requirements-torch.txt TensorFlow-ისთვის```bash
pip install -r requirements-tf.txt
იტვირთება…თუ გაინტერესებთ NLP-ის შესახებ გაცნობა კლასიკური ML პერსპექტივიდან, ეწვიეთ გაკვეთილების ეს ნაკრები
ამ განყოფილებაში
ამ განყოფილებაში ჩვენ გავეცნობით:
- ტექსტის ტენსორების სახით წარმოდგენა
- სიტყვების ჩასმა
- ენის მოდელირება
- განმეორებადი ნერვული ქსელები
- გენერაციული ქსელები
- ტრანსფორმატორები