CNN-ების მომზადებისას, ერთ-ერთი პრობლემა ის არის, რომ ჩვენ გვჭირდება ბევრი ეტიკეტირებული მონაცემები. გამოსახულების კლასიფიკაციის შემთხვევაში, ჩვენ გვჭირდება სურათების გამოყოფა სხვადასხვა კლასებად, რაც არის ხელით ძალისხმევა.
თუმცა, ჩვენ შეიძლება გვსურს გამოვიყენოთ ნედლეული (არა მარკირებული) მონაცემები CNN-ის ფუნქციების ამომყვანების ტრენინგისთვის, რასაც თვით ზედამხედველობითი სწავლება ეწოდება. ეტიკეტების ნაცვლად, ჩვენ გამოვიყენებთ ტრენინგ სურათებს როგორც ქსელის შეყვანის, ასევე გამოსავლის სახით. autoencoder-ის მთავარი იდეა არის ის, რომ ჩვენ გვექნება კოდერის ქსელი, რომელიც გარდაქმნის შეყვანის სურათს რაღაც ლატენტურ სივრცეში (ჩვეულებრივ, ეს არის მხოლოდ მცირე ზომის ვექტორი), შემდეგ დეკოდერის ქსელი, რომლის მიზანი იქნება ორიგინალური სურათის რეკონსტრუქცია.
იმის გამო, რომ ჩვენ ვამზადებთ ავტოენკოდერს, რათა აღბეჭდოს რაც შეიძლება მეტი ინფორმაცია ორიგინალური სურათიდან ზუსტი რეკონსტრუქციისთვის, ქსელი ცდილობს მოიძიოს შეყვანის სურათების საუკეთესო ემბედინგი მნიშვნელობის დასაფიქსირებლად.
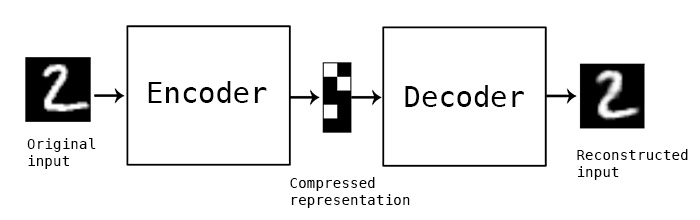
სურათი კერას ბლოგი-დან
ქვემოთ მოყვანილი მაგალითების უმეტესობა შთაგონებულია ამ სტატიას-ით.
მოდით შევქმნათ უმარტივესი ავტოკოდერი MNIST-ისთვის:
იტვირთება…იტვირთება…გამოტანა
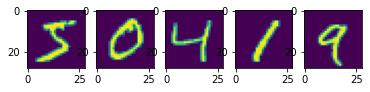
იტვირთება…იტვირთება…იტვირთება…გამოტანა
Train on 60000 samples, validate on 10000 samples
Epoch 1/25
59648/60000 [============================>.] - ETA: 0s - loss: 0.2134/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/training.py:2325: UserWarning: `Model.state_updates` will be removed in a future version. This property should not be used in TensorFlow 2.0, as `updates` are applied automatically.
warnings.warn('`Model.state_updates` will be removed in a future version. '
60000/60000 [==============================] - 6s 99us/sample - loss: 0.2130 - val_loss: 0.1454
Epoch 2/25
60000/60000 [==============================] - 5s 86us/sample - loss: 0.1353 - val_loss: 0.1258
Epoch 3/25
60000/60000 [==============================] - 5s 87us/sample - loss: 0.1225 - val_loss: 0.1177
Epoch 4/25
60000/60000 [==============================] - 5s 85us/sample - loss: 0.1163 - val_loss: 0.1126
Epoch 5/25
60000/60000 [==============================] - 5s 87us/sample - loss: 0.1120 - val_loss: 0.1091
Epoch 6/25
60000/60000 [==============================] - 5s 86us/sample - loss: 0.1093 - val_loss: 0.1070
Epoch 7/25
60000/60000 [==============================] - 5s 87us/sample - loss: 0.1072 - val_loss: 0.1055
Epoch 8/25
60000/60000 [==============================] - 5s 87us/sample - loss: 0.1057 - val_loss: 0.1041
Epoch 9/25
60000/60000 [==============================] - 5s 85us/sample - loss: 0.1045 - val_loss: 0.1028
Epoch 10/25
60000/60000 [==============================] - 5s 84us/sample - loss: 0.1035 - val_loss: 0.1022
Epoch 11/25
60000/60000 [==============================] - 5s 84us/sample - loss: 0.1026 - val_loss: 0.1011
Epoch 12/25
60000/60000 [==============================] - 5s 83us/sample - loss: 0.1018 - val_loss: 0.1003
Epoch 13/25
60000/60000 [==============================] - 5s 83us/sample - loss: 0.1012 - val_loss: 0.0996
Epoch 14/25
60000/60000 [==============================] - 5s 83us/sample - loss: 0.1005 - val_loss: 0.0991
Epoch 15/25
60000/60000 [==============================] - 5s 83us/sample - loss: 0.1000 - val_loss: 0.0988
Epoch 16/25
60000/60000 [==============================] - 5s 82us/sample - loss: 0.0995 - val_loss: 0.0981
Epoch 17/25
60000/60000 [==============================] - 5s 83us/sample - loss: 0.0990 - val_loss: 0.0976
Epoch 18/25
60000/60000 [==============================] - 5s 83us/sample - loss: 0.0986 - val_loss: 0.0974
Epoch 19/25
60000/60000 [==============================] - 5s 84us/sample - loss: 0.0982 - val_loss: 0.0969
Epoch 20/25
60000/60000 [==============================] - 5s 85us/sample - loss: 0.0978 - val_loss: 0.0970
Epoch 21/25
60000/60000 [==============================] - 5s 84us/sample - loss: 0.0975 - val_loss: 0.0962
Epoch 22/25
60000/60000 [==============================] - 5s 84us/sample - loss: 0.0971 - val_loss: 0.0960
Epoch 23/25
60000/60000 [==============================] - 5s 83us/sample - loss: 0.0968 - val_loss: 0.0958
Epoch 24/25
60000/60000 [==============================] - 5s 84us/sample - loss: 0.0966 - val_loss: 0.0953
Epoch 25/25
60000/60000 [==============================] - 5s 83us/sample - loss: 0.0963 - val_loss: 0.0953
<tensorflow.python.keras.callbacks.History at 0x7f3fa179b690>იტვირთება…გამოტანა
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/training.py:2325: UserWarning: `Model.state_updates` will be removed in a future version. This property should not be used in TensorFlow 2.0, as `updates` are applied automatically.
warnings.warn('`Model.state_updates` will be removed in a future version. '
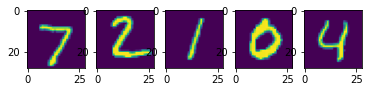
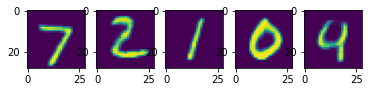
იტვირთება…გამოტანა
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/training.py:2325: UserWarning: `Model.state_updates` will be removed in a future version. This property should not be used in TensorFlow 2.0, as `updates` are applied automatically.
warnings.warn('`Model.state_updates` will be removed in a future version. '
იტვირთება…გამოტანა
იტვირთება…გამოტანა
6.3110805 0.0

ამოცანა 1: შეეცადეთ მოამზადოთ ავტოენკოდერი ძალიან მცირე ფარული ვექტორის ზომით, მაგ. 2 და დახაზეთ წერტილები, რომლებიც შეესაბამება სხვადასხვა ციფრს. მინიშნება: გამოიყენეთ სრულად დაკავშირებული მკვრივი ფენა კონვოლუტონური ნაწილის შემდეგ, რათა შეამციროთ ვექტორის ზომა საჭირო მნიშვნელობამდე.
ამოცანა 2: დაწყებული სხვადასხვა ციფრიდან, მიიღეთ მათი ფარული სივრცის წარმოდგენები და ნახეთ, რა გავლენას ახდენს ლატენტურ სივრცეში გარკვეული ხმაურის დამატება მიღებულ ციფრებზე.
დენოიზირება
ავტოინკოდერები შეიძლება ეფექტურად იქნას გამოყენებული სურათებიდან ხმაურის მოსაშორებლად. დენოიზერის მომზადების მიზნით, ჩვენ დავიწყებთ ხმაურის გარეშე გამოსახულებებით და დავამატებთ მათ ხელოვნურ ხმაურს. შემდეგ, ჩვენ გამოვკვებავთ ავტოინკოდერს ხმაურიანი სურათებით, როგორც შეყვანის სახით, და ხმაურის გარეშე გამოსახულებით, როგორც გამომავალი.
ვნახოთ, როგორ მუშაობს ეს MNIST-ისთვის:
იტვირთება…გამოტანა
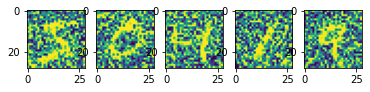
იტვირთება…გამოტანა
Train on 60000 samples, validate on 10000 samples
Epoch 1/25
60000/60000 [==============================] - 6s 101us/sample - loss: 0.1576 - val_loss: 0.1566
Epoch 2/25
60000/60000 [==============================] - 6s 95us/sample - loss: 0.1564 - val_loss: 0.1553
Epoch 3/25
60000/60000 [==============================] - 6s 94us/sample - loss: 0.1555 - val_loss: 0.1539
Epoch 4/25
60000/60000 [==============================] - 6s 95us/sample - loss: 0.1545 - val_loss: 0.1530
Epoch 5/25
60000/60000 [==============================] - 6s 95us/sample - loss: 0.1538 - val_loss: 0.1517
Epoch 6/25
60000/60000 [==============================] - 6s 93us/sample - loss: 0.1528 - val_loss: 0.1506
Epoch 7/25
60000/60000 [==============================] - 6s 93us/sample - loss: 0.1521 - val_loss: 0.1499
Epoch 8/25
60000/60000 [==============================] - 5s 92us/sample - loss: 0.1514 - val_loss: 0.1495
Epoch 9/25
60000/60000 [==============================] - 6s 92us/sample - loss: 0.1508 - val_loss: 0.1487
Epoch 10/25
60000/60000 [==============================] - 6s 93us/sample - loss: 0.1500 - val_loss: 0.1483
Epoch 11/25
60000/60000 [==============================] - 6s 92us/sample - loss: 0.1495 - val_loss: 0.1484
Epoch 12/25
60000/60000 [==============================] - 6s 94us/sample - loss: 0.1487 - val_loss: 0.1468
Epoch 13/25
60000/60000 [==============================] - 6s 92us/sample - loss: 0.1482 - val_loss: 0.1467
Epoch 14/25
60000/60000 [==============================] - 6s 92us/sample - loss: 0.1476 - val_loss: 0.1459
Epoch 15/25
60000/60000 [==============================] - 6s 92us/sample - loss: 0.1469 - val_loss: 0.1450
Epoch 16/25
60000/60000 [==============================] - 6s 92us/sample - loss: 0.1463 - val_loss: 0.1442
Epoch 17/25
60000/60000 [==============================] - 6s 92us/sample - loss: 0.1457 - val_loss: 0.1441
Epoch 18/25
60000/60000 [==============================] - 6s 92us/sample - loss: 0.1451 - val_loss: 0.1429
Epoch 19/25
60000/60000 [==============================] - 6s 92us/sample - loss: 0.1445 - val_loss: 0.1425
Epoch 20/25
60000/60000 [==============================] - 6s 94us/sample - loss: 0.1440 - val_loss: 0.1418
Epoch 21/25
60000/60000 [==============================] - 6s 93us/sample - loss: 0.1435 - val_loss: 0.1423
Epoch 22/25
60000/60000 [==============================] - 6s 93us/sample - loss: 0.1430 - val_loss: 0.1409
Epoch 23/25
60000/60000 [==============================] - 6s 94us/sample - loss: 0.1426 - val_loss: 0.1405
Epoch 24/25
60000/60000 [==============================] - 6s 93us/sample - loss: 0.1422 - val_loss: 0.1409
Epoch 25/25
60000/60000 [==============================] - 6s 93us/sample - loss: 0.1418 - val_loss: 0.1398
<tensorflow.python.keras.callbacks.History at 0x7f3fa612c4d0>იტვირთება…გამოტანა
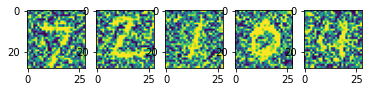
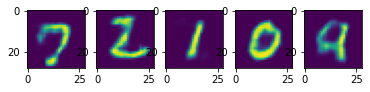
სავარჯიშო: ნახეთ, როგორ მუშაობს MNIST ციფრებზე მომზადებული დენოიზერი სხვადასხვა სურათზე. მაგალითად, შეგიძლიათ აიღოთ მოდის MNIST მონაცემთა ნაკრები, რომელსაც აქვს სურათის იგივე ზომა. გაითვალისწინეთ, რომ დენოიზერი კარგად მუშაობს მხოლოდ იმავე ტიპის გამოსახულებაზე, რომელზედაც ივარჯიშეს (ანუ შეყვანის მონაცემების იგივე ალბათობის განაწილებისთვის).
სუპერ გარჩევადობა
დენოიზერის მსგავსად, ჩვენ შეგვიძლია მოვამზადოთ ავტოენკოდერები გამოსახულების გარჩევადობის გაზრდის მიზნით. სუპერ გარჩევადობის ქსელის მოსამზადებლად, ჩვენ დავიწყებთ მაღალი გარჩევადობის სურათებით და ავტომატურად შევამცირებთ მათ მასშტაბებს ქსელის შეყვანის შესაქმნელად. შემდეგ ჩვენ გამოვკვებავთ ავტოინკოდერს მცირე სურათებით, როგორც შეყვანის სახით და მაღალი რეზოლუციის გამოსახულებებს, როგორც გამოსავალს.
მოდით შევამციროთ MNIST 14x14-მდე:
იტვირთება…გამოტანა
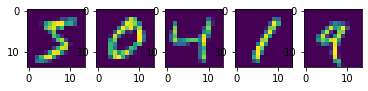
იტვირთება…იტვირთება…გამოტანა
Epoch 1/25
469/469 [==============================] - 6s 10ms/step - loss: 0.3413 - val_loss: 0.1519
Epoch 2/25
469/469 [==============================] - 4s 9ms/step - loss: 0.1457 - val_loss: 0.1292
Epoch 3/25
469/469 [==============================] - 4s 9ms/step - loss: 0.1273 - val_loss: 0.1202
Epoch 4/25
469/469 [==============================] - 4s 9ms/step - loss: 0.1189 - val_loss: 0.1142
Epoch 5/25
469/469 [==============================] - 4s 9ms/step - loss: 0.1148 - val_loss: 0.1107
Epoch 6/25
469/469 [==============================] - 4s 9ms/step - loss: 0.1115 - val_loss: 0.1083
Epoch 7/25
469/469 [==============================] - 4s 9ms/step - loss: 0.1093 - val_loss: 0.1063
Epoch 8/25
469/469 [==============================] - 4s 9ms/step - loss: 0.1071 - val_loss: 0.1046
Epoch 9/25
469/469 [==============================] - 4s 9ms/step - loss: 0.1060 - val_loss: 0.1037
Epoch 10/25
469/469 [==============================] - 4s 9ms/step - loss: 0.1048 - val_loss: 0.1026
Epoch 11/25
469/469 [==============================] - 4s 9ms/step - loss: 0.1039 - val_loss: 0.1019
Epoch 12/25
469/469 [==============================] - 4s 9ms/step - loss: 0.1030 - val_loss: 0.1012
Epoch 13/25
469/469 [==============================] - 4s 9ms/step - loss: 0.1024 - val_loss: 0.1004
Epoch 14/25
469/469 [==============================] - 4s 9ms/step - loss: 0.1017 - val_loss: 0.0999
Epoch 15/25
469/469 [==============================] - 4s 9ms/step - loss: 0.1010 - val_loss: 0.0993
Epoch 16/25
469/469 [==============================] - 4s 9ms/step - loss: 0.1005 - val_loss: 0.0989
Epoch 17/25
469/469 [==============================] - 4s 9ms/step - loss: 0.0999 - val_loss: 0.0983
Epoch 18/25
469/469 [==============================] - 4s 9ms/step - loss: 0.0995 - val_loss: 0.0982
Epoch 19/25
469/469 [==============================] - 4s 9ms/step - loss: 0.0990 - val_loss: 0.0975
Epoch 20/25
469/469 [==============================] - 4s 9ms/step - loss: 0.0987 - val_loss: 0.0971
Epoch 21/25
469/469 [==============================] - 4s 9ms/step - loss: 0.0981 - val_loss: 0.0971
Epoch 22/25
469/469 [==============================] - 4s 9ms/step - loss: 0.0979 - val_loss: 0.0965
Epoch 23/25
469/469 [==============================] - 4s 9ms/step - loss: 0.0977 - val_loss: 0.0959
Epoch 24/25
469/469 [==============================] - 4s 9ms/step - loss: 0.0972 - val_loss: 0.0957
Epoch 25/25
469/469 [==============================] - 4s 9ms/step - loss: 0.0972 - val_loss: 0.0955
<tensorflow.python.keras.callbacks.History at 0x7f66790ada90>იტვირთება…გამოტანა
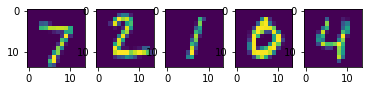
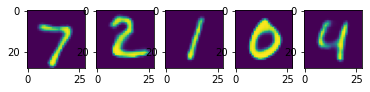
სავარჯიშო: სცადეთ ავარჯიშოთ სუპერ გარჩევადობის ქსელი CIFAR-10-ზე 2x და 4x გაფართოებისთვის. გამოიყენეთ ხმაური, როგორც შემავალი 4x გაფართოების მოდელი და დააკვირდით შედეგს.
ვარიაციული ავტომატური შიფრები (VAE)
ტრადიციული ავტოკოდერები გარკვეულწილად ამცირებენ შეყვანის მონაცემების განზომილებას, აცნობიერებენ შეყვანის სურათების მნიშვნელოვან მახასიათებლებს. თუმცა, ლატენტურ ვექტორებს ხშირად დიდი აზრი არ აქვს. სხვა სიტყვებით რომ ვთქვათ, MNIST მონაცემთა ნაკრების მაგალითზე აყვანა, იმის გარკვევა, თუ რომელი ციფრები შეესაბამება სხვადასხვა ლატენტურ ვექტორებს, არ არის ადვილი ამოცანა, რადგან ახლო ფარული ვექტორები აუცილებლად არ შეესაბამება იმავე ციფრებს.
მეორეს მხრივ, გენერაციული მოდელების მოსამზადებლად უმჯობესია ლატენტური სივრცის გარკვეული გაგება. ეს იდეა მიგვიყვანს ვარიაციული ავტომატური კოდირებით (VAE).
VAE არის ავტოკოდერი, რომელიც სწავლობს ფარული პარამეტრების სტატისტიკური განაწილების წინასწარმეტყველებას, ე.წ. ლატენტური განაწილების. მაგალითად, შეგვიძლია ვივარაუდოთ, რომ ლატენტური ვექტორები განაწილებული იქნება $N(\mathrm{z_mean},e^{\mathrm{z_log_sigma}})$, სადაც $\mathrm{z_mean}, \mathrm{z_log_sigma} \in\mathbb${R}^d. Encoder in VAE სწავლობს ამ პარამეტრების პროგნოზირებას, შემდეგ კი დეკოდერი იღებს შემთხვევით ვექტორს ამ განაწილებიდან ობიექტის რეკონსტრუქციისთვის.
შეჯამება:
- შეყვანის ვექტორიდან ჩვენ ვიწინასწარმეტყველებთ
z_meanდაz_log_sigma-ს (თვითონ სტანდარტული გადახრის პროგნოზირების ნაცვლად, ჩვენ ვიწინასწარმეტყველებთ მის ლოგარითმს) - ჩვენ ვატარებთ ვექტორს
sampleგანაწილებიდან $N(\mathrm{z_mean},e^{\mathrm{z_log_sigma}})$ - დეკოდერი ცდილობს ორიგინალური სურათის გაშიფვრას
sampleშეყვანის ვექტორის გამოყენებით
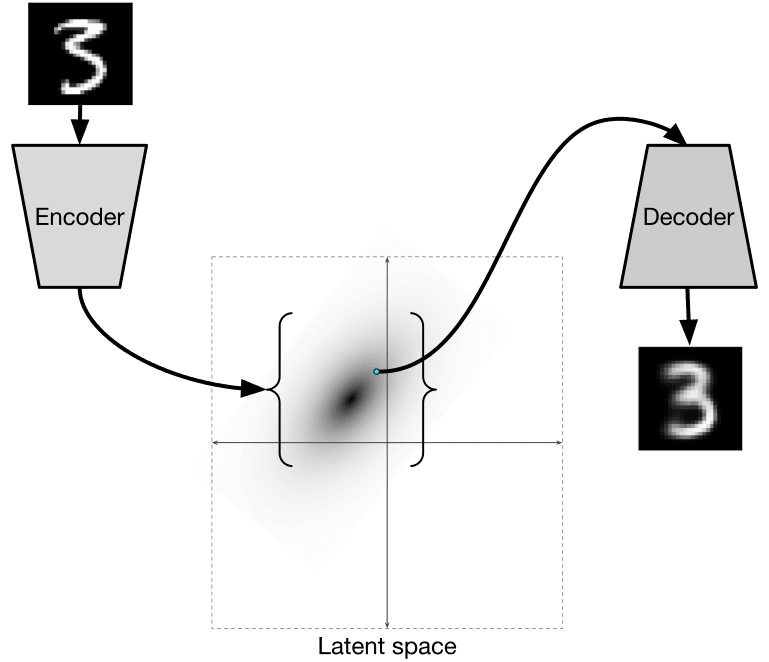
იტვირთება…იტვირთება…იტვირთება…ვარიაციური ავტომატური შიფრები იყენებენ კომპლექსურ დაკარგვის ფუნქციას, რომელიც შედგება ორი ნაწილისგან:
- რეკონსტრუქციის დაკარგვა არის დაკარგვის ფუნქცია, რომელიც გვიჩვენებს, რამდენად ახლოს არის რეკონსტრუქციული სურათი მიზანთან (შეიძლება იყოს MSE). ეს არის იგივე დაკარგვის ფუნქცია, როგორც ჩვეულებრივ ავტოენკოდერებში.
- KL დაკარგვა, რაც უზრუნველყოფს ფარული ცვლადი განაწილების ნორმალურ განაწილებასთან ახლოს ყოფნას. იგი ეფუძნება კულბეკ-ლეიბლერის დივერგენცია ცნებას - მეტრიკა, რათა შეფასდეს, რამდენად მსგავსია ორი სტატისტიკური განაწილება.
იტვირთება…იტვირთება…გამოტანა
Train on 60000 samples, validate on 10000 samples
Epoch 1/25
59520/60000 [============================>.] - ETA: 0s - loss: 48.6396/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/training.py:2325: UserWarning: `Model.state_updates` will be removed in a future version. This property should not be used in TensorFlow 2.0, as `updates` are applied automatically.
warnings.warn('`Model.state_updates` will be removed in a future version. '
60000/60000 [==============================] - 4s 64us/sample - loss: 48.5874 - val_loss: 41.8877
Epoch 2/25
60000/60000 [==============================] - 3s 57us/sample - loss: 41.1296 - val_loss: 40.2556
Epoch 3/25
60000/60000 [==============================] - 3s 56us/sample - loss: 40.0063 - val_loss: 39.3692
Epoch 4/25
60000/60000 [==============================] - 3s 56us/sample - loss: 39.2531 - val_loss: 38.7666
Epoch 5/25
60000/60000 [==============================] - 3s 57us/sample - loss: 38.7147 - val_loss: 38.6124
Epoch 6/25
60000/60000 [==============================] - 3s 57us/sample - loss: 38.2962 - val_loss: 38.1867
Epoch 7/25
60000/60000 [==============================] - 3s 56us/sample - loss: 37.9756 - val_loss: 37.9831
Epoch 8/25
60000/60000 [==============================] - 3s 57us/sample - loss: 37.6933 - val_loss: 37.5475
Epoch 9/25
60000/60000 [==============================] - 3s 57us/sample - loss: 37.4323 - val_loss: 37.2913
Epoch 10/25
60000/60000 [==============================] - 3s 56us/sample - loss: 37.2133 - val_loss: 37.1992
Epoch 11/25
60000/60000 [==============================] - 3s 57us/sample - loss: 36.9966 - val_loss: 36.9521
Epoch 12/25
60000/60000 [==============================] - 3s 57us/sample - loss: 36.8204 - val_loss: 36.8431
Epoch 13/25
60000/60000 [==============================] - 3s 57us/sample - loss: 36.6490 - val_loss: 36.6979
Epoch 14/25
60000/60000 [==============================] - 3s 57us/sample - loss: 36.5023 - val_loss: 36.6661
Epoch 15/25
60000/60000 [==============================] - 3s 57us/sample - loss: 36.3456 - val_loss: 36.4957
Epoch 16/25
60000/60000 [==============================] - 3s 56us/sample - loss: 36.2266 - val_loss: 36.6669
Epoch 17/25
60000/60000 [==============================] - 3s 57us/sample - loss: 36.1045 - val_loss: 36.4855
Epoch 18/25
60000/60000 [==============================] - 3s 57us/sample - loss: 35.9922 - val_loss: 36.4150
Epoch 19/25
60000/60000 [==============================] - 3s 56us/sample - loss: 35.8968 - val_loss: 36.1196
Epoch 20/25
60000/60000 [==============================] - 3s 57us/sample - loss: 35.7991 - val_loss: 36.0708
Epoch 21/25
60000/60000 [==============================] - 3s 56us/sample - loss: 35.7129 - val_loss: 36.1686
Epoch 22/25
60000/60000 [==============================] - 3s 57us/sample - loss: 35.6214 - val_loss: 36.1080
Epoch 23/25
60000/60000 [==============================] - 3s 57us/sample - loss: 35.5357 - val_loss: 36.2309
Epoch 24/25
60000/60000 [==============================] - 3s 56us/sample - loss: 35.4528 - val_loss: 36.1416
Epoch 25/25
60000/60000 [==============================] - 3s 56us/sample - loss: 35.3650 - val_loss: 35.7258
<tensorflow.python.keras.callbacks.History at 0x7f0e00233890>იტვირთება…გამოტანა
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/training.py:2325: UserWarning: `Model.state_updates` will be removed in a future version. This property should not be used in TensorFlow 2.0, as `updates` are applied automatically.
warnings.warn('`Model.state_updates` will be removed in a future version. '
იტვირთება…გამოტანა
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/training.py:2325: UserWarning: `Model.state_updates` will be removed in a future version. This property should not be used in TensorFlow 2.0, as `updates` are applied automatically.
warnings.warn('`Model.state_updates` will be removed in a future version. '
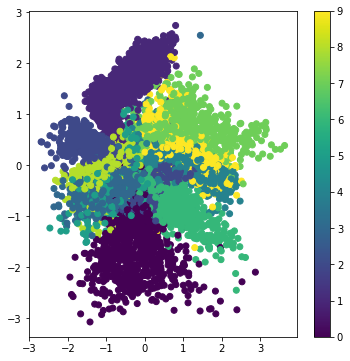
იტვირთება…გამოტანა
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/training.py:2325: UserWarning: `Model.state_updates` will be removed in a future version. This property should not be used in TensorFlow 2.0, as `updates` are applied automatically.
warnings.warn('`Model.state_updates` will be removed in a future version. '

ამოცანა: ჩვენს ნიმუშში ჩვენ მოვამზადეთ სრულად დაკავშირებული VAE. ახლა აიღეთ CNN ზემოთ არსებული ტრადიციული ავტომატური კოდირებიდან და შექმენით CNN-ზე დაფუძნებული VAE.
დამატებითი მასალები
- ბლოგის პოსტი NeuroHive-ზე
- ვარიაციური ავტოენკოდერები განმარტებულია