განმეორებადი ქსელების ერთი მთავარი ნაკლი არის ის, რომ ყველა სიტყვას თანმიმდევრობით ერთნაირი გავლენა აქვს შედეგზე. ეს იწვევს არაოპტიმალურ შესრულებას სტანდარტული LSTM შიფრატორ-დეკოდერის მოდელების თანმიმდევრობით მიმდევრობით დავალებებისთვის, როგორიცაა დასახელებული ერთეულის ამოცნობა და მანქანური თარგმანი. სინამდვილეში, შეყვანის თანმიმდევრობის კონკრეტული სიტყვები ხშირად უფრო მეტ გავლენას ახდენს თანმიმდევრულ გამოსავალზე, ვიდრე სხვები.
განვიხილოთ თანმიმდევრობით-მიმდევრობის მოდელი, როგორიცაა მანქანური თარგმანი. იგი ხორციელდება ორი განმეორებადი ქსელით, სადაც ერთი ქსელი (ენკოდერი) აქცევს შეყვანის თანმიმდევრობას დამალულ მდგომარეობაში, ხოლო მეორე, დეკოდერი, ამ ფარულ მდგომარეობას თარგმნის შედეგში. ამ მიდგომის პრობლემა ის არის, რომ ქსელის საბოლოო მდგომარეობას გაუჭირდება წინადადების დასაწყისის დამახსოვრება, რაც იწვევს მოდელის უხარისხობას გრძელ წინადადებებზე.
ყურადღების მექანიზმები უზრუნველყოფს თითოეული შეყვანის ვექტორის კონტექსტური ზემოქმედების შეწონვის საშუალებას RNN-ის თითოეულ გამომავალ პროგნოზზე. მისი განხორციელების გზა არის მალსახმობების შექმნა შეყვანის RNN-ის შუალედურ მდგომარეობასა და გამომავალ RNN-ს შორის. ამ გზით, $y_t$ გამომავალი სიმბოლოს გენერირებისას, ჩვენ გავითვალისწინებთ ყველა შეყვანის დამალულ მდგომარეობას $h_i$, სხვადასხვა წონის კოეფიციენტებით $\alpha_{t,i}$.
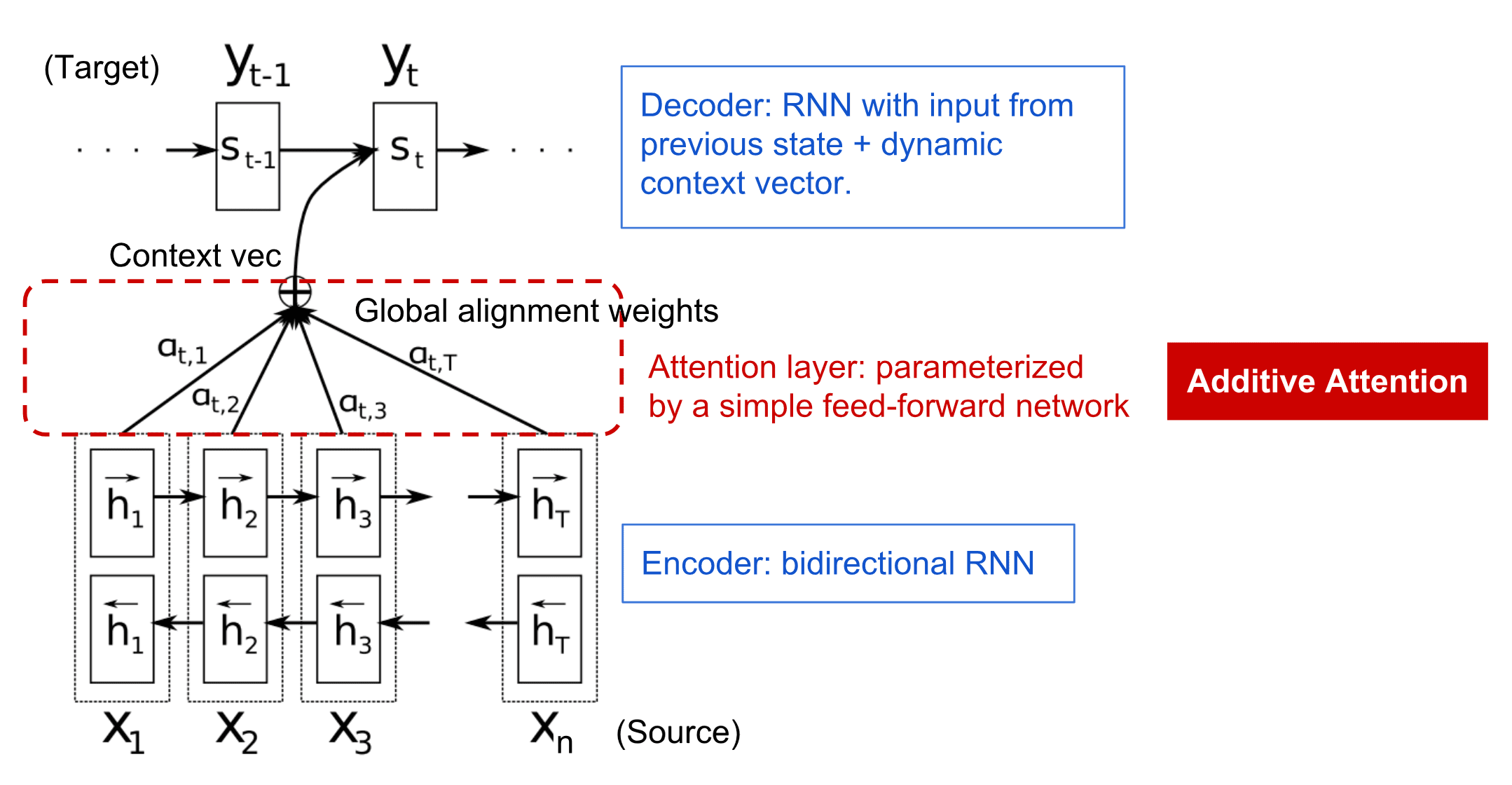 კოდერ-დეკოდერის მოდელი დანამატის ყურადღების მექანიზმით ბაჰდანაუ და სხვები, 2015 წ-ში, ციტირებულია ეს ბლოგის პოსტი-დან
კოდერ-დეკოდერის მოდელი დანამატის ყურადღების მექანიზმით ბაჰდანაუ და სხვები, 2015 წ-ში, ციტირებულია ეს ბლოგის პოსტი-დან
საყურადღებო მატრიცა ${\alpha_{i,j}}$ წარმოადგენს ხარისხს, რომელსაც გარკვეული შემავალი სიტყვები უკრავს მოცემული სიტყვის წარმოქმნისას გამომავალი თანმიმდევრობით. ქვემოთ მოცემულია ასეთი მატრიცის მაგალითი:

სურათი აღებულია ბაჰდანაუ და სხვები, 2015 წ-დან (ნახ.3)
ყურადღების მექანიზმები პასუხისმგებელნი არიან ბუნებრივი ენის დამუშავების თანამედროვე ან თითქმის მიმდინარე მდგომარეობის დიდ ნაწილზე. თუმცა ყურადღების მიქცევა მნიშვნელოვნად ზრდის მოდელის პარამეტრების რაოდენობას, რამაც გამოიწვია სკალირების პრობლემები RNN-ებთან. RNN-ების სკალირების მთავარი შეზღუდვა ის არის, რომ მოდელების განმეორებითი ბუნება რთულს ხდის ტრენინგის ჯგუფურ და პარალელიზებას. RNN-ში, თანმიმდევრობის თითოეული ელემენტი უნდა დამუშავდეს თანმიმდევრული თანმიმდევრობით, რაც ნიშნავს, რომ მისი ადვილად პარალელიზება შეუძლებელია.
ამ შეზღუდვასთან ერთად ყურადღების მექანიზმების გამოყენებამ განაპირობა თანამედროვე ტრანსფორმატორის მოდელების შექმნა, რომლებიც ჩვენ ვიცით და ვიყენებთ დღეს BERT-დან OpenGPT3-მდე.
ტრანსფორმატორის მოდელები
შეფასების საფეხურზე ყოველი წინა პროგნოზის კონტექსტის გადაგზავნის ნაცვლად, ტრანსფორმატორის მოდელები იყენებს პოზიციურ კოდირებას (positional encoding) და ყურადღების მექანიზმს (attention mechanism) მოცემული შეყვანის კონტექსტის აღსაბეჭდად ტექსტის მოწოდებულ ფანჯარაში. ქვემოთ მოყვანილი სურათი გვიჩვენებს, თუ როგორ შეუძლია ყურადღების მქონე პოზიციურ დაშიფვრებს კონტექსტის აღბეჭდვა მოცემულ ფანჯარაში.

იმის გამო, რომ თითოეული შეყვანის პოზიცია დამოუკიდებლად არის შედგენილი თითოეულ გამომავალ პოზიციაზე, ტრანსფორმატორებს შეუძლიათ უკეთესად გაატარონ პარალელიზაცია, ვიდრე RNN, რაც იძლევა ბევრად უფრო დიდ და უფრო გამოხატულ ენობრივ მოდელებს. თითოეული ყურადღების თავი შეიძლება გამოყენებულ იქნას სიტყვებს შორის განსხვავებული ურთიერთობების შესასწავლად, რაც აუმჯობესებს ბუნებრივი ენის დამუშავების ამოცანებს.
მარტივი ტრანსფორმატორის მოდელის აშენება
Keras არ შეიცავს ჩაშენებულ ტრანსფორმატორის ფენას, მაგრამ ჩვენ შეგვიძლია ავაშენოთ საკუთარი. როგორც ადრე, ჩვენ ყურადღებას გავამახვილებთ AG News მონაცემთა ნაკრების ტექსტურ კლასიფიკაციაზე, მაგრამ აღსანიშნავია, რომ ტრანსფორმატორის მოდელები საუკეთესო შედეგს აჩვენებს უფრო რთულ NLP ამოცანებში.
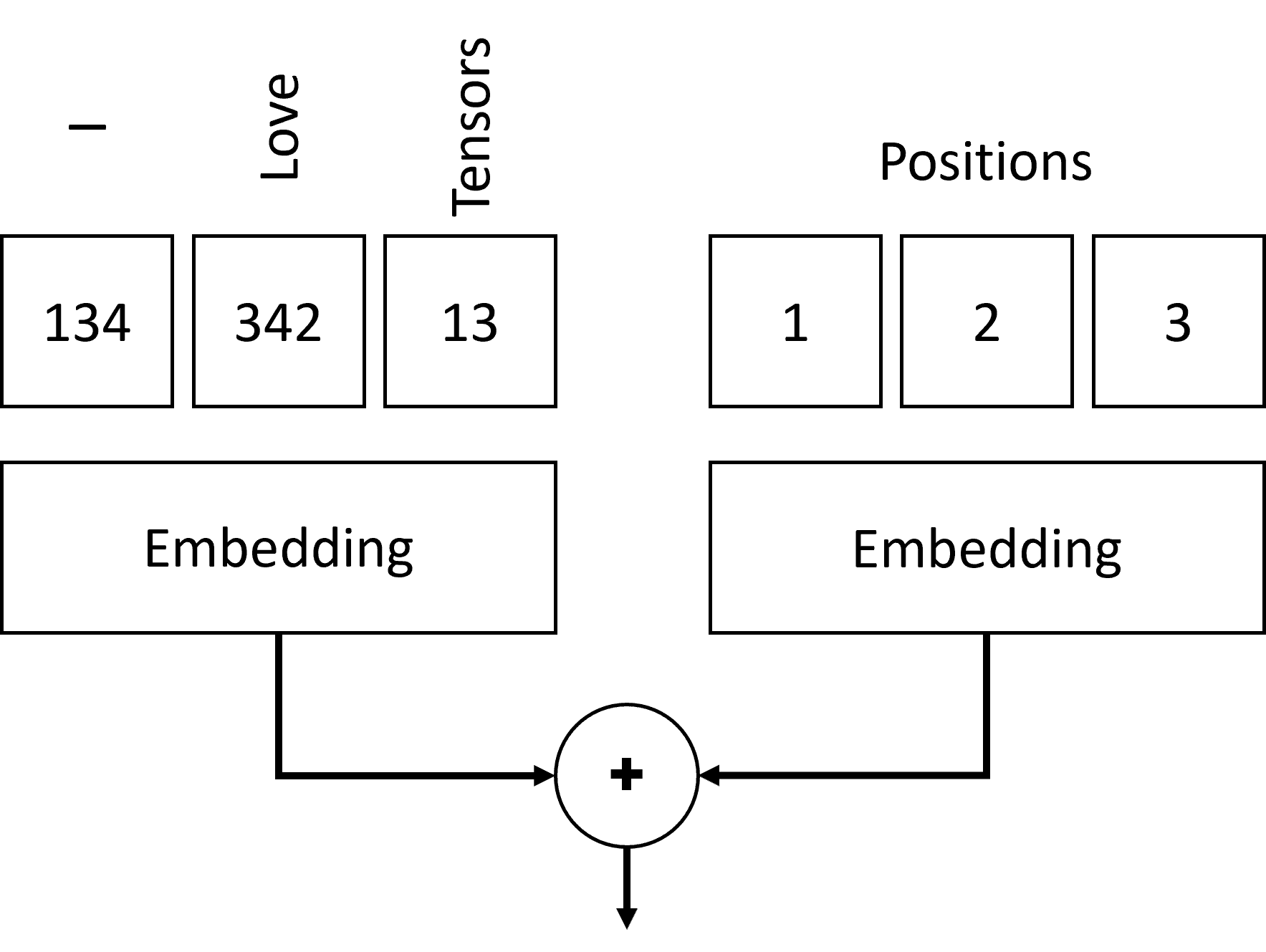
იტვირთება…ახალი შრეები Keras-ში უნდა იყოს ქვეკლასი Layer კლასში და დანერგოს call მეთოდი. დავიწყოთ Positional Embedding ფენით. ჩვენ გამოვიყენებთ ზოგიერთი კოდი Keras-ის ოფიციალური დოკუმენტაციიდან. ჩვენ ვივარაუდებთ, რომ ყველა შეყვანის თანმიმდევრობას ვამაგრებთ maxlen სიგრძით.
იტვირთება…ეს ფენა შედგება ორი Embedding ფენისგან: ტოკენების ჩასართავად (როგორც ჩვენ უკვე განვიხილეთ) და ტოკენის პოზიციები. ტოკენების პოზიციები იქმნება, როგორც ნატურალური რიცხვების თანმიმდევრობა 0-დან maxlen-მდე tf.range-ის გამოყენებით და შემდეგ გადადის ჩაშენების ფენაში. შემდეგ ემატება ორი მიღებული ჩანერგვის ვექტორი, რომლებიც წარმოქმნიან ფორმის შეყვანის პოზიციურად ჩაშენებულ რეპორტაჟს maxlen$\ჯერ$embed_dim.
ახლა მოდით განვახორციელოთ ტრანსფორმატორის ბლოკი. ის მიიღებს ადრე განსაზღვრული ჩაშენების ფენის გამომავალს:
იტვირთება…ტრანსფორმატორი იყენებს MultiHeadAttention-ს პოზიციურად დაშიფრულ შეყვანაზე, რათა წარმოქმნას maxlen$\ჯერ$embed_dim განზომილების ყურადღების ვექტორი, რომელიც შერეულია შეყვანთან და ნორმალიზდება LayerNormalizaton-ის გამოყენებით.
შენიშვნა:
LayerNormalizationმსგავსიაBatchNormalization-ისა, რომელიც განხილულია ამ სასწავლო ბილიკის Computer Vision ნაწილში, მაგრამ ის ახდენს წინა ფენის შედეგების ნორმალიზებას თითოეული სასწავლო ნიმუშისთვის დამოუკიდებლად, რათა მიიყვანოს მათ დიაპაზონში [-1..1].
ამ ფენის გამომავალი შემდეგ გადადის Dense ქსელში (ჩვენს შემთხვევაში - ორფენიანი პერცეტრონი) და შედეგი ემატება საბოლოო გამომავალს (რომელიც ისევ ნორმალიზდება).
![]()
ახლა ჩვენ მზად ვართ განვსაზღვროთ სრული ტრანსფორმატორის მოდელი:
იტვირთება…გამოტანა
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization (TextVect (None, 256) 0
_________________________________________________________________
token_and_position_embedding (None, 256, 32) 648192
_________________________________________________________________
transformer_block (Transform (None, 256, 32) 10656
_________________________________________________________________
global_average_pooling1d (Gl (None, 32) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 32) 0
_________________________________________________________________
dense_2 (Dense) (None, 20) 660
_________________________________________________________________
dropout_3 (Dropout) (None, 20) 0
_________________________________________________________________
dense_3 (Dense) (None, 4) 84
=================================================================
Total params: 659,592
Trainable params: 659,592
Non-trainable params: 0
_________________________________________________________________
იტვირთება…გამოტანა
Training tokenizer
938/938 [==============================] - 45s 39ms/step - loss: 0.4978 - acc: 0.8068 - val_loss: 0.2808 - val_acc: 0.9124
<tensorflow.python.keras.callbacks.History at 0x7f9c2427a0d0>BERT ტრანსფორმატორის მოდელები
BERT (ორმხრივი კოდირების წარმოდგენები ტრანსფორმერებისგან) არის ძალიან დიდი მრავალშრიანი ტრანსფორმატორის ქსელი 12 ფენით BERT-base-ისთვის და 24 BERT-large-ისთვის. მოდელი პირველად წინასწარ ივარჯიშება ტექსტური მონაცემების დიდ კორპუსზე (ვიკიპედია + წიგნები) უკონტროლო ტრენინგის გამოყენებით (წინადადებაში ნიღბიანი სიტყვების პროგნოზირება). წინასწარი ტრენინგის დროს მოდელი შთანთქავს ენის გაგების მნიშვნელოვან დონეს, რომელიც შემდეგ შეიძლება გამოყენებულ იქნას სხვა მონაცემთა ნაკრებებთან ერთად ზუსტი დარეგულირების გამოყენებით. ამ პროცესს ეწოდება ტრანსფერული სწავლა.
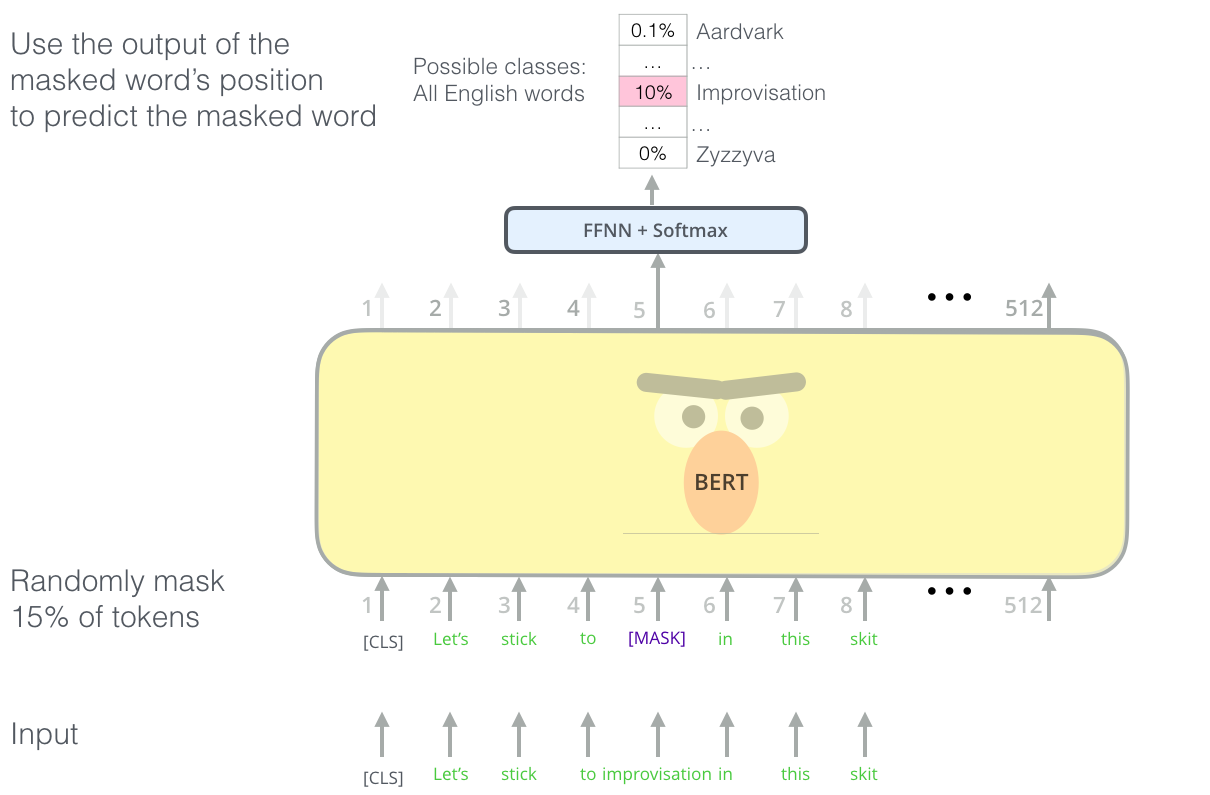
ტრანსფორმატორის არქიტექტურის მრავალი ვარიაციაა, მათ შორის BERT, DistilBERT. BigBird, OpenGPT3 და სხვა, რომელთა დარეგულირება შესაძლებელია.
ვნახოთ, როგორ შეგვიძლია გამოვიყენოთ წინასწარ მომზადებული BERT მოდელი ჩვენი ტრადიციული თანმიმდევრობის კლასიფიკაციის პრობლემის გადასაჭრელად. ჩვენ ვისესხებთ იდეას და კოდს ოფიციალური დოკუმენტაცია-დან.
წინასწარ მომზადებული მოდელების ჩასატვირთად, ჩვენ გამოვიყენებთ Tensorflow hub. პირველი, მოდით ჩატვირთოთ BERT-ის სპეციფიკური ვექტორიზატორი:
იტვირთება…გამოტანა
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_41180/4216669875.py in <module>
----> 1 import tensorflow_text
2 import tensorflow_hub as hub
3 vectorizer = hub.KerasLayer('https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3')
ModuleNotFoundError: No module named 'tensorflow_text'იტვირთება…გამოტანა
{'input_type_ids': <tf.Tensor: shape=(1, 128), dtype=int32, numpy=
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
dtype=int32)>,
'input_word_ids': <tf.Tensor: shape=(1, 128), dtype=int32, numpy=
array([[ 101, 1045, 2293, 19081, 102, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0]], dtype=int32)>,
'input_mask': <tf.Tensor: shape=(1, 128), dtype=int32, numpy=
array([[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
dtype=int32)>}მნიშვნელოვანია, რომ გამოიყენოთ იგივე ვექტორიზატორი, რომელზედაც ივარჯიშეს თავდაპირველი ქსელი. ასევე, BERT ვექტორიზატორი აბრუნებს სამ კომპონენტს:
input_word_ids, რომელიც წარმოადგენს ნიშანთა რიცხვების თანმიმდევრობას შეყვანის წინადადებისთვისinput_mask, რომელიც გვიჩვენებს მიმდევრობის რომელი ნაწილი შეიცავს რეალურ შეყვანას და რომელი ავსებს. ის მსგავსიაMaskingფენით წარმოებული ნიღბისაinput_type_idsგამოიყენება ენის მოდელირების ამოცანებისთვის და საშუალებას გაძლევთ მიუთითოთ ორი შეყვანის წინადადება ერთი თანმიმდევრობით.
შემდეგ, ჩვენ შეგვიძლია გამოვიყენოთ BERT ფუნქციების ამომყვანი:
იტვირთება…იტვირთება…გამოტანა
pooled_output -> (1, 128)
encoder_outputs -> 4
sequence_output -> (1, 128, 128)
default -> (1, 128)
ასე რომ, BERT ფენა აბრუნებს უამრავ სასარგებლო შედეგს:
pooled_outputარის თანმიმდევრობით ყველა ტოკენის საშუალო გამოანგარიშების შედეგი. თქვენ შეგიძლიათ ნახოთ იგი, როგორც მთელი ქსელის ინტელექტუალური სემანტიკური ჩანერგვა. ეს უდრისGlobalAveragePooling1Dფენის გამოსავალს ჩვენს წინა მოდელში.sequence_outputარის ბოლო ტრანსფორმატორის ფენის გამოსავალი (შეესაბამებაTransformerBlock-ის გამომავალს ჩვენს ზემოთ მოდელში)encoder_outputsარის ყველა ტრანსფორმატორის ფენის გამოსავალი. მას შემდეგ, რაც ჩვენ ჩატვირთეთ 4-ფენიანი BERT მოდელი (როგორც ალბათ მიხვდებით სახელიდან, რომელიც შეიცავს4_H), მას აქვს 4 ტენსორი. ბოლო იგივეა, რაცsequence_output.
ახლა ჩვენ განვსაზღვრავთ ბოლოდან ბოლომდე კლასიფიკაციის მოდელს. ჩვენ გამოვიყენებთ ფუნქციური მოდელის განმარტებას, როდესაც განვსაზღვრავთ მოდელის შეყვანას, შემდეგ კი გამოვიყენებთ გამონათქვამების სერიას მისი გამოსავლის გამოსათვლელად. ჩვენ ასევე გავაკეთებთ BERT მოდელის წონებს არასავარჯიშოს და ვავარჯიშებთ მხოლოდ საბოლოო კლასიფიკატორს:
იტვირთება…გამოტანა
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None,)] 0
__________________________________________________________________________________________________
keras_layer (KerasLayer) {'input_type_ids': ( 0 input_1[0][0]
__________________________________________________________________________________________________
keras_layer_1 (KerasLayer) {'pooled_output': (N 4782465 keras_layer[0][0]
keras_layer[0][1]
keras_layer[0][2]
__________________________________________________________________________________________________
dropout_4 (Dropout) (None, 128) 0 keras_layer_1[0][5]
__________________________________________________________________________________________________
dense_4 (Dense) (None, 4) 516 dropout_4[0][0]
==================================================================================================
Total params: 4,782,981
Trainable params: 516
Non-trainable params: 4,782,465
__________________________________________________________________________________________________
იტვირთება…გამოტანა
938/938 [==============================] - 528s 559ms/step - loss: 0.8056 - acc: 0.6983 - val_loss: 0.5953 - val_acc: 0.7888
<tensorflow.python.keras.callbacks.History at 0x7f9bb1e36d00>იმისდა მიუხედავად, რომ რამდენიმე სავარჯიშო პარამეტრია, პროცესი საკმაოდ ნელია, რადგან BERT ფუნქციების ამომყვანი გამოთვლით მძიმეა. როგორც ჩანს, ჩვენ ვერ მივაღწიეთ გონივრულ სიზუსტეს, არც ტრენინგის ან მოდელის პარამეტრების ნაკლებობის გამო.
ვცადოთ BERT-ის წონების გაყინვა და ისიც ვავარჯიშოთ. ეს მოითხოვს ძალიან მცირე სწავლის სიჩქარეს და ასევე უფრო ფრთხილად სასწავლო სტრატეგიას დათბობით, AdamW ოპტიმიზატორის გამოყენებით. ჩვენ გამოვიყენებთ tf-models-official პაკეტს ოპტიმიზატორის შესაქმნელად:
იტვირთება…გამოტანა
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None,)] 0
__________________________________________________________________________________________________
keras_layer (KerasLayer) {'input_type_ids': ( 0 input_1[0][0]
__________________________________________________________________________________________________
keras_layer_1 (KerasLayer) {'pooled_output': (N 4782465 keras_layer[0][0]
keras_layer[0][1]
keras_layer[0][2]
__________________________________________________________________________________________________
dropout_4 (Dropout) (None, 128) 0 keras_layer_1[0][5]
__________________________________________________________________________________________________
dense_4 (Dense) (None, 4) 516 dropout_4[0][0]
==================================================================================================
Total params: 4,782,981
Trainable params: 4,782,980
Non-trainable params: 1
__________________________________________________________________________________________________
938/938 [==============================] - 629s 664ms/step - loss: 0.6344 - acc: 0.7658 - val_loss: 0.4876 - val_acc: 0.8247
<tensorflow.python.keras.callbacks.History at 0x7f9bb0bd0070>როგორც ხედავთ, ტრენინგი საკმაოდ ნელა მიმდინარეობს - მაგრამ შეიძლება დაგჭირდეთ ექსპერიმენტი და მოამზადოთ მოდელი რამდენიმე ეპოქისთვის (5-10) და ნახოთ, შეგიძლიათ თუ არა საუკეთესო შედეგის მიღება იმ მიდგომებთან შედარებით, რომლებიც ადრე ვიყენებდით.
Huggingface Transformers Library
ტრანსფორმატორის მოდელების გამოყენების კიდევ ერთი ძალიან გავრცელებული (და ცოტა უფრო მარტივი) გზაა HuggingFace პაკეტი, რომელიც უზრუნველყოფს მარტივ სამშენებლო ბლოკებს სხვადასხვა NLP ამოცანებისთვის. ის ხელმისაწვდომია როგორც Tensorflow-სთვის, ასევე PyTorch-ისთვის, კიდევ ერთი ძალიან პოპულარული ნერვული ქსელის ჩარჩოსთვის.
შენიშვნა: თუ არ გაინტერესებთ როგორ მუშაობს Transformers ბიბლიოთეკა - შეგიძლიათ გადახვიდეთ ამ ნოუთბუქის ბოლომდე, რადგან ვერაფერს ნახავთ არსებითად განსხვავებულს იმისგან, რაც ზემოთ გავაკეთეთ. ჩვენ ვიმეორებთ BERT მოდელის ტრენინგის იგივე ნაბიჯებს სხვადასხვა ბიბლიოთეკის და არსებითად უფრო დიდი მოდელის გამოყენებით. ამრიგად, პროცესი მოიცავს საკმაოდ ხანგრძლივ ტრენინგს, ასე რომ თქვენ შეგიძლიათ უბრალოდ გადახედოთ კოდს.
ვნახოთ, როგორ შეიძლება ჩვენი პრობლემის გადაჭრა Hugging Face Transformers-ის გამოყენებით.
პირველი რაც უნდა გავაკეთოთ არის მოდელის არჩევა, რომელსაც გამოვიყენებთ. ზოგიერთი ჩაშენებული მოდელის გარდა, Huggingface შეიცავს ონლაინ მოდელის საცავი-ს, სადაც შეგიძლიათ იპოვოთ უფრო მეტი წინასწარ მომზადებული მოდელი საზოგადოების მიერ. ყველა ამ მოდელის ჩატვირთვა და გამოყენება შესაძლებელია მხოლოდ მოდელის სახელის მითითებით. მოდელისთვის საჭირო ყველა ორობითი ფაილი ავტომატურად ჩამოიტვირთება.
გარკვეულ დროს მოგიწევთ საკუთარი მოდელების ჩატვირთვა, ამ შემთხვევაში შეგიძლიათ მიუთითოთ დირექტორია, რომელიც შეიცავს ყველა შესაბამის ფაილს, მათ შორის ტოკენიზატორის პარამეტრებს, config.json ფაილს მოდელის პარამეტრებით, ორობითი წონებით და ა.შ.
მოდელის სახელიდან ჩვენ შეგვიძლია განვსაზღვროთ როგორც მოდელი, ასევე ტოკენიზატორი. დავიწყოთ ტოკენიზატორით:
იტვირთება…tokenizer ობიექტი შეიცავს encode ფუნქციას, რომელიც შეიძლება პირდაპირ იქნას გამოყენებული ტექსტის დაშიფვრისთვის:
იტვირთება…გამოტანა
[101, 23435, 12314, 2003, 1037, 2307, 7705, 2005, 17953, 2361, 102]ჩვენ ასევე შეგვიძლია გამოვიყენოთ ტოკენიზატორი, რათა დაშიფროთ თანმიმდევრობა, რომელიც შესაფერისია მოდელზე გადასასვლელად, ანუ token_ids, input_mask ველების ჩათვლით და ა.შ.
იტვირთება…გამოტანა
{'input_ids': <tf.Tensor: shape=(1, 5), dtype=int32, numpy=array([[ 101, 7592, 1010, 2045, 102]], dtype=int32)>, 'token_type_ids': <tf.Tensor: shape=(1, 5), dtype=int32, numpy=array([[0, 0, 0, 0, 0]], dtype=int32)>, 'attention_mask': <tf.Tensor: shape=(1, 5), dtype=int32, numpy=array([[1, 1, 1, 1, 1]], dtype=int32)>}ჩვენს შემთხვევაში, ჩვენ გამოვიყენებთ წინასწარ გაწვრთნილ BERT მოდელს სახელწოდებით bert-base-uncased. uncased მიუთითებს, რომ მოდელი არ არის რეგისტრირებული.
მოდელის მომზადებისას, ჩვენ უნდა მივაწოდოთ ტოკენიზებული თანმიმდევრობა, როგორც შეყვანა, და ამით ჩვენ შევქმნით მონაცემთა დამუშავების მილს. ვინაიდან tokenizer.encode არის პითონის ფუნქცია, ჩვენ გამოვიყენებთ იგივე მიდგომას, როგორც ბოლო ერთეულში, მისი გამოძახებით py_function-ის გამოყენებით:
იტვირთება…ახლა ჩვენ შეგვიძლია ჩატვირთოთ რეალური მოდელი BertForSequenceClassfication პაკეტის გამოყენებით. ეს უზრუნველყოფს, რომ ჩვენს მოდელს უკვე აქვს საჭირო არქიტექტურა კლასიფიკაციისთვის, საბოლოო კლასიფიკატორის ჩათვლით. თქვენ იხილავთ გამაფრთხილებელ შეტყობინებას, რომელშიც ნათქვამია, რომ საბოლოო კლასიფიკატორის წონა არ არის ინიციალიზებული და მოდელი საჭიროებს წინასწარ მომზადებას - ეს აბსოლუტურად ნორმალურია, რადგან ეს არის ზუსტად ის, რის გაკეთებასაც ჩვენ ვაპირებთ!
იტვირთება…იტვირთება…გამოტანა
Model: "tf_bert_for_sequence_classification_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (TFBertMainLayer) multiple 109482240
_________________________________________________________________
dropout_75 (Dropout) multiple 0
_________________________________________________________________
classifier (Dense) multiple 3076
=================================================================
Total params: 109,485,316
Trainable params: 109,485,316
Non-trainable params: 0
_________________________________________________________________
როგორც ხედავთ summary()-დან, მოდელი შეიცავს თითქმის 110 მილიონ პარამეტრს! სავარაუდოდ, თუ გვსურს მარტივი კლასიფიკაციის დავალება შედარებით მცირე მონაცემთა ბაზაზე, არ გვინდა BERT საბაზისო ფენის მომზადება:
იტვირთება…გამოტანა
Model: "tf_bert_for_sequence_classification_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (TFBertMainLayer) multiple 109482240
_________________________________________________________________
dropout_75 (Dropout) multiple 0
_________________________________________________________________
classifier (Dense) multiple 3076
=================================================================
Total params: 109,485,316
Trainable params: 3,076
Non-trainable params: 109,482,240
_________________________________________________________________
ახლა ჩვენ მზად ვართ ვარჯიშის დასაწყებად!
შენიშვნა: სრულმასშტაბიანი BERT მოდელის ტრენინგი შეიძლება ძალიან შრომატევადი იყოს! ამრიგად, ჩვენ მას მხოლოდ პირველი 32 პარტიისთვის ვავარჯიშებთ. ეს მხოლოდ იმის ჩვენებაა, თუ როგორ არის მოწყობილი მოდელის ტრენინგი. თუ გაინტერესებთ სრულმასშტაბიანი ტრენინგის ცდა - უბრალოდ წაშალეთ
steps_per_epochდაvalidation_stepsპარამეტრები და მოემზადეთ ლოდინისთვის!
იტვირთება…გამოტანა
32/32 [==============================] - 142s 4s/step - loss: 1.3896 - acc: 0.2500 - val_loss: 1.3863 - val_acc: 0.2480
<tensorflow.python.keras.callbacks.History at 0x7f1d40a4b6a0>თუ გაზრდით გამეორებების რაოდენობას და საკმარისად დიდხანს დაელოდებით და ვარჯიშობთ რამდენიმე ეპოქის განმავლობაში, შეგიძლიათ ველით, რომ BERT კლასიფიკაცია გვაძლევს საუკეთესო სიზუსტეს! ეს იმიტომ ხდება, რომ BERT-ს უკვე კარგად ესმის ენის სტრუქტურა და ჩვენ მხოლოდ საბოლოო კლასიფიკატორის დაზუსტება გვჭირდება. თუმცა, იმის გამო, რომ BERT არის დიდი მოდელი, მთელი სასწავლო პროცესი დიდ დროს იღებს და მოითხოვს სერიოზულ გამოთვლით ძალას! (GPU და სასურველია ერთზე მეტი).
შენიშვნა: ჩვენს მაგალითში, ჩვენ ვიყენებდით ერთ-ერთ ყველაზე პატარა წინასწარ მომზადებულ BERT მოდელს. არსებობს უფრო დიდი მოდელები, რომლებიც, სავარაუდოდ, უკეთეს შედეგს მოიტანენ.
Takeaway
ამ ერთეულში ჩვენ ვნახეთ უახლესი მოდელის არქიტექტურები ტრანსფორმატორებზე. ჩვენ გამოვიყენეთ ისინი ჩვენი ტექსტის კლასიფიკაციის ამოცანისთვის, მაგრამ ანალოგიურად, BERT მოდელები შეიძლება გამოყენებულ იქნას ერთეულების ამოღების, კითხვებზე პასუხის გაცემის და სხვა NLP ამოცანებისთვის.
ტრანსფორმატორის მოდელები წარმოადგენს უახლეს მიღწევას (state-of-the-art) NLP-ში და უმეტეს შემთხვევაში ეს უნდა იყოს პირველი გამოსავალი, რომლითაც დაიწყებთ ექსპერიმენტებს პერსონალური NLP გადაწყვეტილებების განხორციელებისას. თუმცა, ამ მოდულში განხილული განმეორებადი ნერვული ქსელების ძირითადი პრინციპების გაგება ძალზე მნიშვნელოვანია, თუ გსურთ შექმნათ მოწინავე ნერვული მოდელები.