სალექციო ვიქტორინა
NLP დომენის ერთ-ერთი ყველაზე მნიშვნელოვანი პრობლემაა მანქანური თარგმანი, არსებითი ამოცანა, რომელიც ემყარება ისეთ ინსტრუმენტებს, როგორიცაა Google Translate. ამ განყოფილებაში ჩვენ ყურადღებას გავამახვილებთ მანქანურ თარგმანზე, ან, ზოგადად, ნებისმიერ მიმდევრობა-მიმდევრობით ამოცანაზე (რომელსაც ასევე უწოდებენ წინადადების ტრანსდუქციას).
RNN-ებით, მიმდევრობა-მიმდევრობა ხორციელდება ორი განმეორებადი ქსელით, სადაც ერთი ქსელი, კოდერი, აქცევს შეყვანის თანმიმდევრობას ფარულ მდგომარეობაში, ხოლო მეორე ქსელი, დეკოდერი, ამ ფარულ მდგომარეობას გადააქვს თარგმნილ შედეგში. ამ მიდგომასთან დაკავშირებით რამდენიმე პრობლემაა:
- კოდირების ქსელის საბოლოო მდგომარეობას უჭირს წინადადების დასაწყისის დამახსოვრება, რაც იწვევს მოდელის უხარისხობას გრძელი წინადადებებისთვის
- თანმიმდევრობით ყველა სიტყვა ერთნაირად მოქმედებს შედეგზე. თუმცა, სინამდვილეში, შეყვანის თანმიმდევრობის კონკრეტული სიტყვები ხშირად უფრო მეტ გავლენას ახდენს თანმიმდევრულ გამოსავალზე, ვიდრე სხვები.
ყურადღების მექანიზმები უზრუნველყოფს თითოეული შეყვანის ვექტორის კონტექსტური ზემოქმედების შეწონვის საშუალებას RNN-ის თითოეულ გამომავალ პროგნოზზე. მისი განხორციელების გზა არის მალსახმობების შექმნა შეყვანის RNN-სა და გამომავალ RNN-ის შუალედურ მდგომარეობას შორის. ამ გზით, გამომავალი სიმბოლო yt გენერირებით, ჩვენ გავითვალისწინებთ ყველა შეყვანის დამალულ მდგომარეობას hi, სხვადასხვა წონის კოეფიციენტებით αt,i____.
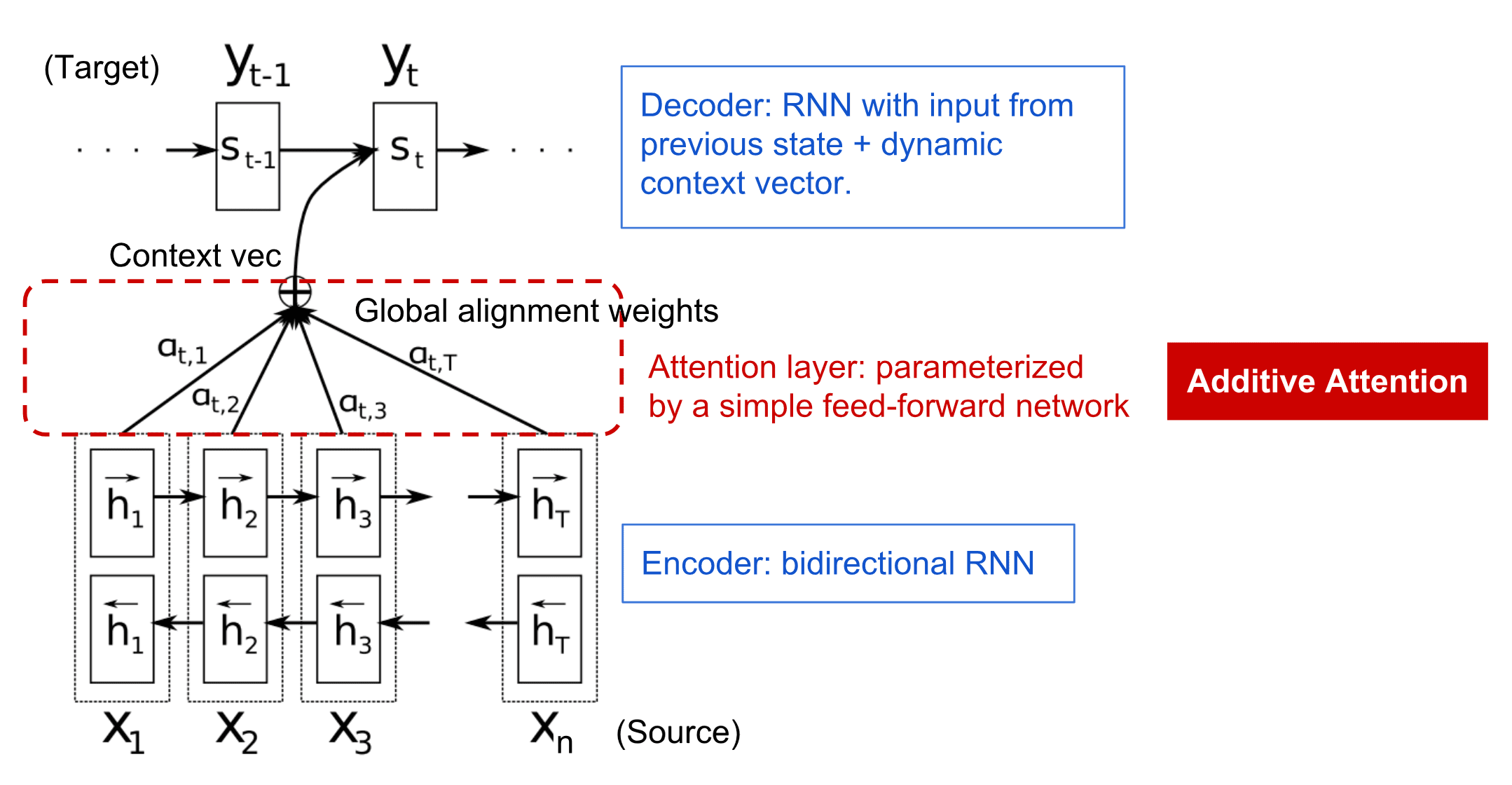
კოდირ-დეკოდერის მოდელი დანამატის ყურადღების მექანიზმით ბაჰდანაუ და სხვები, 2015 წ-ში, ციტირებულია ეს ბლოგის პოსტი-დან
ყურადღების მატრიცა {αi,j} წარმოადგენს იმ ხარისხს, რომელსაც გარკვეული შემავალი სიტყვები თამაშობენ მოცემული სიტყვის წარმოქმნაში გამომავალი თანმიმდევრობით. ქვემოთ მოცემულია ასეთი მატრიცის მაგალითი:

სურათი ბაჰდანაუ და სხვები, 2015 წ-დან (ნახ.3)
ყურადღების მექანიზმები პასუხისმგებელნი არიან NLP-ის თანამედროვე ან თითქმის მიმდინარე მდგომარეობის დიდ ნაწილზე. თუმცა ყურადღების მიქცევა მნიშვნელოვნად ზრდის მოდელის პარამეტრების რაოდენობას, რამაც გამოიწვია სკალირების პრობლემები RNN-ებთან. RNN-ების სკალირების მთავარი შეზღუდვა ის არის, რომ მოდელების განმეორებითი ბუნება რთულს ხდის ტრენინგის ჯგუფურ და პარალელიზებას. RNN-ში, თანმიმდევრობის თითოეული ელემენტი უნდა დამუშავდეს თანმიმდევრული თანმიმდევრობით, რაც ნიშნავს, რომ მისი ადვილად პარალელიზება შეუძლებელია.
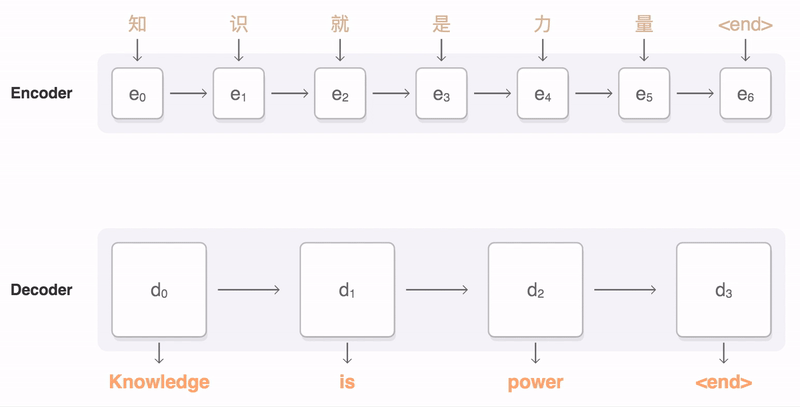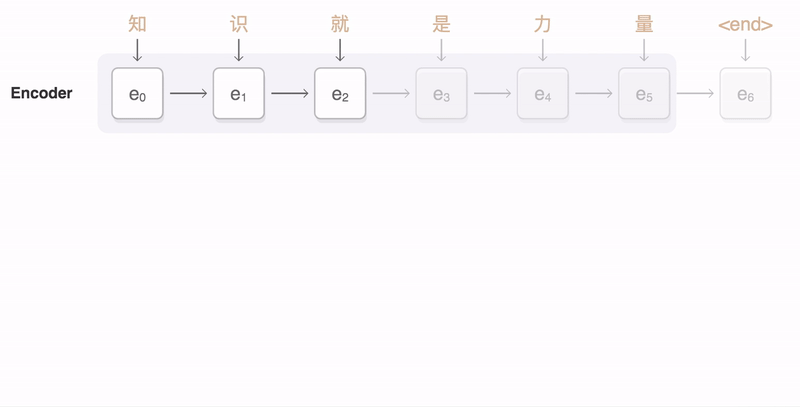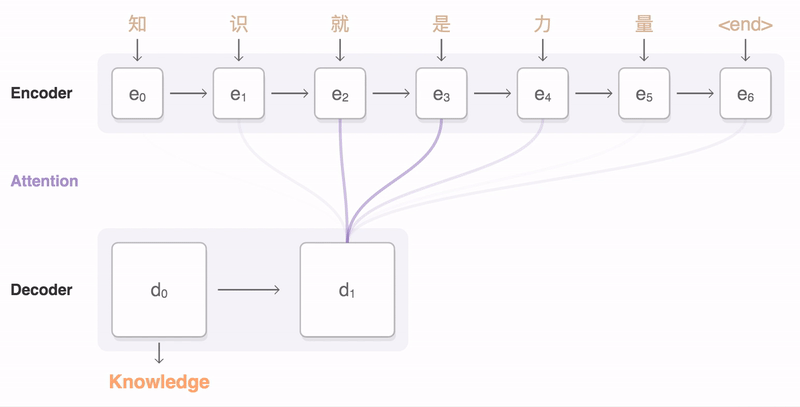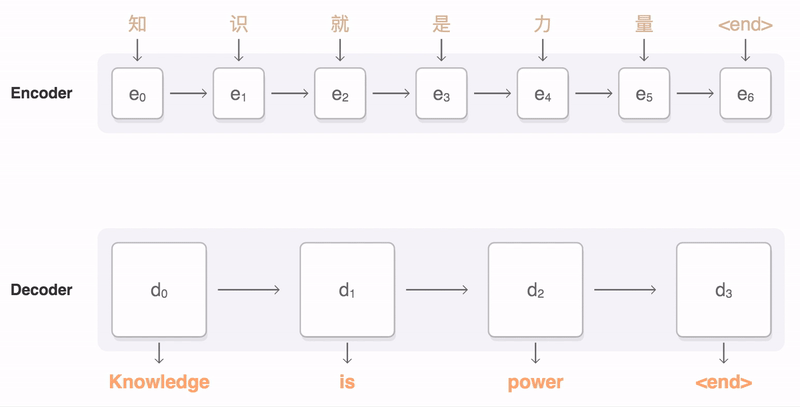
ფიგურა Google-ის ბლოგი-დან
ამ შეზღუდვასთან ერთად ყურადღების მექანიზმების მიღებამ განაპირობა თანამედროვე ტრანსფორმატორის მოდელების შექმნა, რომლებიც ჩვენ ვიცით და ვიყენებთ დღეს, როგორიცაა BERT to Open-GPT3.
ტრანსფორმატორის მოდელები
ტრანსფორმატორების ერთ-ერთი მთავარი იდეა არის RNN-ების თანმიმდევრული ბუნების თავიდან აცილება და ტრენინგის დროს პარალელიზებული მოდელის შექმნა. ეს მიიღწევა ორი იდეის განხორციელებით:
- პოზიციური კოდირება
- RNN-ების (ან CNN-ების) ნაცვლად შაბლონების გადასაღებად თვითყურადღების მექანიზმის გამოყენება (ამიტომ ქაღალდს, რომელიც შემოაქვს ტრანსფორმატორებს, ეწოდება ყურადღება არის ყველაფერი რაც თქვენ გჭირდებათ
პოზიციური კოდირება/ემბედინგი
პოზიციური კოდირების იდეა შემდეგია.
- RNN-ების გამოყენებისას, ნიშნების ფარდობითი პოზიცია წარმოდგენილია ნაბიჯების რაოდენობით და, შესაბამისად, არ საჭიროებს ცალსახად წარმოდგენას.
- თუმცა, როგორც კი ყურადღებაზე გადავალთ, უნდა ვიცოდეთ ტოკენების შედარებითი პოზიციები მიმდევრობის ფარგლებში.
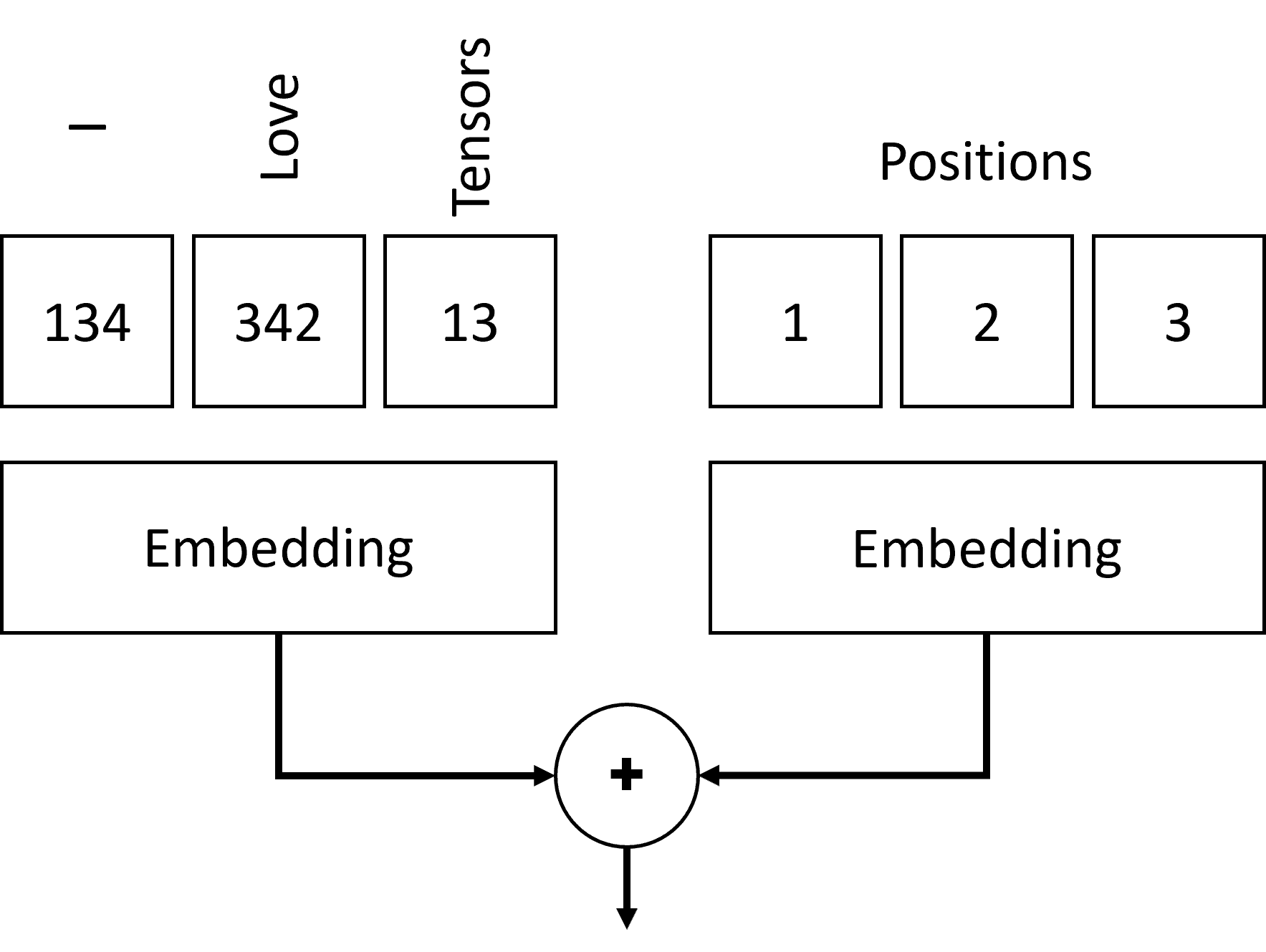
- პოზიციური კოდირების მისაღებად, ჩვენ ვამატებთ ტოკენების ჩვენს თანმიმდევრობას თანმიმდევრობით (ანუ 0,1, ... რიცხვების თანმიმდევრობით).
- ამის შემდეგ ჩვენ ვაზავებთ ტოკენის პოზიციას ტოკენის ჩანერგვის ვექტორთან. პოზიციის (მთლიანი) ვექტორად გადასაყვანად, შეგვიძლია გამოვიყენოთ სხვადასხვა მიდგომები:
- Trainable embedding, სიმბოლური ჩაშენების მსგავსი. ეს არის მიდგომა, რომელსაც აქ განვიხილავთ. ჩვენ ვაყენებთ ჩაშენების ფენებს ორივე ჟეტონზე და მათ პოზიციებზე, რის შედეგადაც ვათავსებთ იმავე განზომილების ვექტორებს, რომლებსაც შემდეგ ვამატებთ.
- ფიქსირებული პოზიციის კოდირების ფუნქცია, როგორც შემოთავაზებულია ორიგინალურ ნაშრომში.
ავტორის სურათი
შედეგი, რომელსაც ვიღებთ პოზიციური ჩაშენებით, აერთიანებს როგორც თავდაპირველ ჟეტონს, ასევე მის პოზიციას თანმიმდევრობით.
მრავალთავიანი თვითყურადღება
შემდეგი, ჩვენ უნდა გადავიღოთ რამდენიმე ნიმუში ჩვენი თანმიმდევრობით. ამისთვის, ტრანსფორმატორები იყენებენ თვითყურადღებას მექანიზმს, რომელიც არსებითად აქცევს ყურადღებას იმავე თანმიმდევრობას, როგორც შეყვანა და გამომავალი. საკუთარი თავის ყურადღების გამოყენება საშუალებას გვაძლევს გავითვალისწინოთ კონტექსტი წინადადებაში და ვნახოთ რომელი სიტყვებია ურთიერთდაკავშირებული. მაგალითად, ის საშუალებას გვაძლევს დავინახოთ, რომელ სიტყვებს მოიხსენიებენ კორეფერენციებით, როგორიცაა it და ასევე გავითვალისწინოთ კონტექსტი:
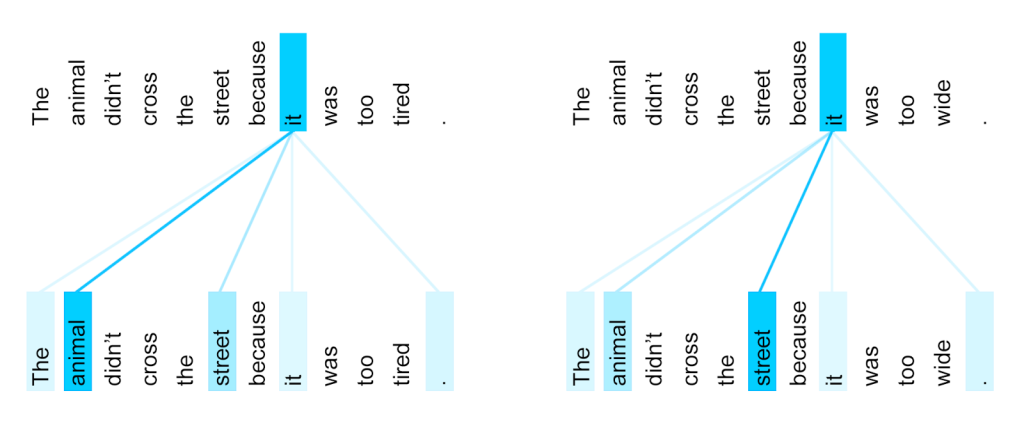
სურათი Google ბლოგი-დან
ტრანსფორმატორებში ჩვენ ვიყენებთ Multi-Head Attention, რათა ქსელს მივცეთ ძალა, დაიჭიროს რამდენიმე სხვადასხვა ტიპის დამოკიდებულება, მაგ. გრძელვადიანი წინააღმდეგ მოკლევადიანი სიტყვის მიმართება, თანამინიშნება სხვა რაღაცის წინააღმდეგ და ა.შ.
TensorFlow ნოუთბუქი შეიცავს მეტ დაკავებას ტრანსფორმატორის ფენების განხორციელების შესახებ.
Encoder-Decoder ყურადღება
ტრანსფორმატორებში ყურადღება გამოიყენება ორ ადგილას:
- შეყვანის ტექსტის შაბლონების გადაღება თვითყურადღების გამოყენებით
- თანმიმდევრული თარგმანის შესასრულებლად - ეს არის ყურადღების ფენა ენკოდერსა და დეკოდერს შორის.
ენკოდერ-დეკოდერის ყურადღება ძალიან ჰგავს RNN-ებში გამოყენებულ ყურადღების მექანიზმს, როგორც ეს აღწერილია ამ განყოფილების დასაწყისში. ეს ანიმაციური დიაგრამა ხსნის ენკოდერ-დეკოდერის ყურადღების როლს.

იმის გამო, რომ თითოეული შეყვანის პოზიცია დამოუკიდებლად არის შედგენილი თითოეულ გამომავალ პოზიციაზე, ტრანსფორმატორებს შეუძლიათ უკეთესად გაატარონ პარალელიზაცია, ვიდრე RNN, რაც იძლევა ბევრად უფრო დიდ და უფრო გამოხატულ ენობრივ მოდელებს. თითოეული ყურადღების თავი შეიძლება გამოყენებულ იქნას სიტყვებს შორის განსხვავებული ურთიერთობების შესასწავლად, რაც აუმჯობესებს ბუნებრივი ენის დამუშავების ამოცანებს.
ბერტი
BERT (ორმხრივი კოდირების წარმოდგენები ტრანსფორმერებისგან) არის ძალიან დიდი მრავალშრიანი ტრანსფორმატორის ქსელი 12 ფენით BERT-base-ისთვის და 24 BERT-large-ისთვის. მოდელი პირველად წინასწარ ივარჯიშება ტექსტური მონაცემების დიდ კორპუსზე (ვიკიპედია + წიგნები) უკონტროლო ტრენინგის გამოყენებით (წინადადებაში ნიღბიანი სიტყვების პროგნოზირება). წინასწარი ტრენინგის დროს მოდელი შთანთქავს ენის გაგების მნიშვნელოვან დონეს, რომელიც შემდგომ შეიძლება გამოყენებულ იქნას სხვა მონაცემთა ნაკრებებთან ერთად ზუსტი დარეგულირების გამოყენებით. ამ პროცესს ეწოდება ტრანსფერული სწავლა.
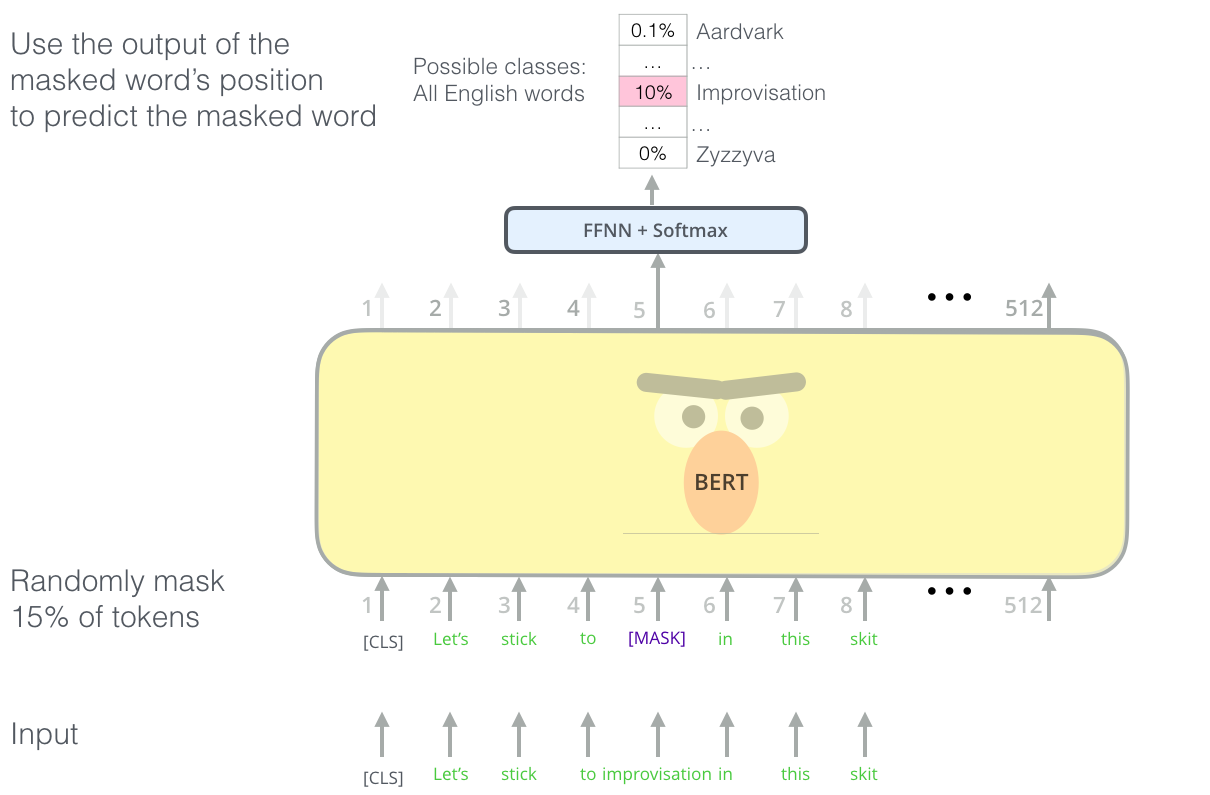
სურათი წყარო
სავარჯიშოები: ტრანსფორმატორები
განაგრძეთ სწავლა შემდეგ რვეულებში:
- ტრანსფორმატორები PyTorch-ში
- ტრანსფორმატორები TensorFlow-ში
დასკვნა
ამ გაკვეთილზე თქვენ შეიტყვეთ ტრანსფორმატორებისა და ყურადღების მექანიზმების შესახებ, NLP ხელსაწყოთა ყუთში არსებული ყველა აუცილებელი ინსტრუმენტი. ტრანსფორმატორის არქიტექტურის მრავალი ვარიაციაა, მათ შორის BERT, DistilBERT. BigBird, OpenGPT3 და სხვა, რომელთა დარეგულირება შესაძლებელია. HuggingFace პაკეტი უზრუნველყოფს საცავს ამ მრავალი არქიტექტურის ტრენინგისთვის როგორც PyTorch-ით, ასევე TensorFlow-ით.
გამოწვევა
ლექციის შემდგომი ვიქტორინა
მიმოხილვა და თვითშესწავლა
- ბლოგის პოსტი, ახსნის კლასიკურ ყურადღება არის ყველაფერი რაც თქვენ გჭირდებათ ქაღალდს ტრანსფორმატორებზე.
- ბლოგის პოსტების სერია ტრანსფორმატორებზე, დეტალურად ხსნის არქიტექტურას.