ეს ნოუთბუქი AI დამწყებთათვის სასწავლო გეგმები-ის ნაწილია. ეწვიეთ საცავს სასწავლო მასალების სრული ნაკრებისთვის.
ნერვული ჩარჩოები
ჩვენ გავიგეთ, რომ ნერვული ქსელების მოსამზადებლად გჭირდებათ:
- სწრაფად გაამრავლეთ მატრიცები (ტენსორები)
- გამოთვალეთ გრადიენტები გრადიენტული წარმოშობის ოპტიმიზაციის შესასრულებლად
რა საშუალებას გაძლევთ გააკეთოთ ნერვული ქსელის ჩარჩოები:
- იმუშავეთ ტენსორებით ნებისმიერ გამოთვლაზე, CPU ან GPU, ან თუნდაც TPU
- გრადიენტების ავტომატური გამოთვლა (ისინი აშკარად დაპროგრამებულია ყველა ჩაშენებული ტენზორული ფუნქციისთვის)
სურვილისამებრ:
- ნერვული ქსელის კონსტრუქტორი / უმაღლესი დონის API (აღწერეთ ქსელი, როგორც ფენების თანმიმდევრობა)
- მარტივი სასწავლო ფუნქციები (
fit, როგორც Scikit Learn-ში) - ოპტიმიზაციის მთელი რიგი ალგორითმები გრადიენტული წარმოშობის გარდა
- მონაცემთა დამუშავების აბსტრაქციები (რომელიც იდეალურად იმუშავებს GPU-ზეც)
ყველაზე პოპულარული ჩარჩოები
- Tensorflow 1.x - პირველი ფართოდ ხელმისაწვდომი ჩარჩო (Google). ნებადართულია განსაზღვროს სტატიკური გამოთვლითი გრაფიკი, დააყენოს იგი GPU-ზე და მკაფიოდ შეაფასოს იგი
- PyTorch - ფეისბუქის ჩარჩო, რომელიც იზრდება პოპულარობით
- Keras - უფრო მაღალი დონის API Tensorflow/PyTorch-ის თავზე ნერვული ქსელების გაერთიანებისა და გამარტივების მიზნით (Francois Chollet)
- Tensorflow 2.x + Keras - Tensorflow-ის ახალი ვერსია ინტეგრირებული Keras ფუნქციონირებით, რომელიც მხარს უჭერს დინამიური გამოთვლის გრაფიკს, რაც საშუალებას გაძლევთ შეასრულოთ ტენზორული ოპერაციები, რომლებიც ძალიან ჰგავს numpy-ს (და PyTorch)
ამ ნოუთბუქში ჩვენ ვისწავლით PyTorch-ის გამოყენებას. თქვენ უნდა დარწმუნდეთ, რომ დაინსტალირებული გაქვთ PyTorch-ის უახლესი ვერსია - ამისათვის მიჰყევით ინსტრუქციები მათ საიტზე. როგორც წესი, ეს ისეთივე მარტივია, როგორც გაკეთებაpip install torch torchvisionან```
conda install pytorch -c pytorch
იტვირთება…გამოტანა
'1.11.0+cu113'ძირითადი ცნებები: ტენსორი
Tensor არის მრავალგანზომილებიანი მასივი. ძალიან მოსახერხებელია ტენსორების გამოყენება სხვადასხვა ტიპის მონაცემების წარმოსადგენად:
- 400x400 - შავ-თეთრი სურათი
- 400x400x3 - ფერადი სურათი
- 16x400x400x3 - 16 ფერადი სურათის მინი პარტია
- 25x400x400x3 - ერთი წამი 25-fps ვიდეოდან
- 8x25x400x400x3 - 8 1 წამიანი ვიდეოს მინი პარტია
მარტივი ტენსორები
თქვენ შეგიძლიათ მარტივად შექმნათ მარტივი ტენსორები np მასივების სიებიდან, ან შექმნათ შემთხვევითი:
იტვირთება…გამოტანა
tensor([[1, 2],
[3, 4]])
tensor([[ 0.8995, -1.6137, 1.4489],
[-0.2796, -2.1443, -2.4618],
[-0.2358, -0.4249, -0.0716],
[-0.1267, -0.6382, 0.0593],
[-0.4956, 1.7054, 0.3874],
[ 1.3479, -1.6329, 0.2793],
[ 1.1211, -1.5430, 0.7186],
[-1.5197, 0.5559, -1.6421],
[ 0.1900, -0.4175, -0.3922],
[ 1.8994, 0.1497, -0.7039]])
თქვენ შეგიძლიათ გამოიყენოთ არითმეტიკული მოქმედებები ტენსორებზე, რომლებიც შესრულებულია ელემენტების მიხედვით, როგორც numpy-ში. საჭიროების შემთხვევაში ტენზორები ავტომატურად აფართოებენ საჭირო განზომილებას. ტენსორიდან ნუმპი მასივის ამოსაღებად გამოიყენეთ .numpy():
იტვირთება…გამოტანა
tensor([[ 0.0000, 0.0000, 0.0000],
[-2.0583, -0.5631, 1.4932],
[-1.0613, -1.0738, 2.2078],
[-1.5101, 0.5896, 2.4722],
[-2.8219, -2.0846, 1.2405],
[ 0.8706, -0.2485, 2.3679],
[-1.6590, 0.1935, 1.8698],
[-0.3316, 0.8065, 1.6490],
[-1.5788, -1.1844, -0.4816],
[ 0.0680, -1.4526, 1.8159]])
[3.887189 2.1276016 0.17371987]
ადგილზე და გარე ოპერაციები
ტენსორის ოპერაციები, როგორიცაა +/add აბრუნებს ახალ ტენსორებს. თუმცა, ზოგჯერ საჭიროა არსებული ტენზორის ადგილზე შეცვლა. ოპერაციების უმეტესობას აქვს საკუთარი ანალოგები, რომლებიც მთავრდება _-ით:
იტვირთება…გამოტანა
Result when adding out-of-place: tensor(8)
Result after adding in-place: tensor(8)
აი, როგორ შეგვიძლია გამოვთვალოთ ჯამი ან ყველა მწკრივი მატრიცაში გულუბრყვილოდ:
იტვირთება…გამოტანა
tensor([ 3.4945, 2.5325, -2.8684])
მაგრამ მისი გამოყენება ბევრად უკეთესია
იტვირთება…გამოტანა
tensor([ 3.4945, 2.5325, -2.8684])შეგიძლიათ მეტი წაიკითხოთ PyTorch ტენსორების შესახებ ოფიციალური დოკუმენტაცია-ში
გამოთვლითი გრადიენტები
უკანა გამრავლებისთვის საჭიროა გრადიენტების გამოთვლა. ჩვენ შეგვიძლია დავაყენოთ PyTorch Tensor-ის ნებისმიერი ატრიბუტი requires_grad``True-ზე, რაც გამოიწვევს ამ ტენზორის ყველა ოპერაციას გრადიენტის გამოთვლებისთვის. გრადიენტების გამოსათვლელად, თქვენ უნდა გამოიძახოთ backward() მეთოდი, რის შემდეგაც გრადიენტი ხელმისაწვდომი გახდება grad ატრიბუტის გამოყენებით:
იტვირთება…გამოტანა
tensor([[-0.1728, 0.0913],
[-0.1666, -0.1942]])
უფრო ზუსტად რომ ვთქვათ, PyTorch ავტომატურად აგროვებს გრადიენტებს. თუ backward-ის გამოძახებისას მიუთითებთ retain_graph=True-ს, გამოთვლითი გრაფიკი შენარჩუნდება და ახალი გრადიენტი დაემატება grad ველს. იმისათვის, რომ გამოთვლითი გრადიენტები თავიდან დავიწყოთ, ჩვენ გვჭირდება grad ველის გადატვირთვა 0-ზე აშკარად zero_()-ის დარეკვით:
იტვირთება…გამოტანა
tensor([[-0.5185, 0.2739],
[-0.4998, -0.5826]])
tensor([[-0.1728, 0.0913],
[-0.1666, -0.1942]])
გრადიენტების გამოსათვლელად PyTorch ქმნის და ინახავს გამოთვლით გრაფიკს. თითოეული ტენსორისთვის, რომელსაც აქვს requires_grad დროშა დაყენებული True-ზე, PyTorch ინარჩუნებს სპეციალურ ფუნქციას, სახელწოდებით grad_fn, რომელიც გამოთვლის გამოხატვის წარმოებულს ჯაჭვის დიფერენციაციის წესის მიხედვით:
იტვირთება…გამოტანა
tensor(0.9143, grad_fn=<MeanBackward0>)
აქ c გამოითვლება mean ფუნქციის გამოყენებით, შესაბამისად grad_fn მიუთითებს ფუნქციაზე, სახელად MeanBackward.
უმეტეს შემთხვევაში, ჩვენ გვინდა, რომ PyTorch-მა გამოთვალოს სკალარული ფუნქციის გრადიენტი (როგორიცაა დაკარგვის ფუნქცია). თუმცა, თუ ჩვენ გვინდა გამოვთვალოთ ტენზორის გრადიენტი სხვა ტენზორთან მიმართებაში, PyTorch გვაძლევს საშუალებას გამოვთვალოთ იაკობის მატრიცისა და მოცემული ვექტორის ნამრავლი.
დავუშვათ, გვაქვს ვექტორული ფუნქცია $\vec{y}=f(\vec{x})$, სადაც $\vec{x}=\langle x_1,\dots,x_n\rangle$ და $\vec{y}=\langle y_1,\dots,y_m\rangle$, შემდეგ $\vec{y}$-ის გრადიენტი $\vec{x}$-ის მიმართ განისაზღვრება Jacobian-ით:
$$ \begin{align}J=\left(\begin{მასივი}ccc} \frac{\partial y_{1}}{\partial x_{1}} & \cdots & \frac{\partial y_{1}}{\partial x_{n}}\ \vdots & \ddots & \vdots\ \frac{\partial y_{m}}{\partial x_{1}} & \cdots & \frac{\partial y_{m}}{\partial x_{n}} \end{მასივი}\right)\end{გასწორება} $$
იმის ნაცვლად, რომ მოგვცეს წვდომა მთელ Jacobian-ზე, PyTorch გამოთვლის პროდუქტს $v^T\cdot J$ of Jacobian რაღაც ვექტორით.
$v=(v_1 \წერტილები v_m)$. ამისათვის ჩვენ უნდა გამოვიძახოთ backward and pass v as an argument. The size of v უნდა იყოს იგივე, რაც საწყისი ტენზორის ზომა, რომლის მიმართაც ჩვენ გამოვთვალოთ გრადიენტი.
იტვირთება…გამოტანა
tensor([[-0.8642, 0.0913],
[-0.1666, -0.9710]])
მეტი იაკობიანების გამოთვლის შესახებ PyTorch-ში შეგიძლიათ იხილოთ ოფიციალური დოკუმენტაცია-ში
მაგალითი 0: ოპტიმიზაცია გრადიენტური დაღმართის გამოყენებით
შევეცადოთ გამოვიყენოთ ავტომატური დიფერენციაცია, რათა ვიპოვოთ მარტივი ორცვლადიანი ფუნქციის მინიმუმი $f(x_1,x_2)=(x_1-3)^2+(x_2+2)^2$. დაე, ტენსორმა x შეინარჩუნოს წერტილის მიმდინარე კოორდინატები. ჩვენ ვიწყებთ საწყისი წერტილით $x^{(0)}=(0,0)$ და გამოვთვალეთ შემდეგი წერტილი თანმიმდევრობით გრადიენტული წარმოშობის ფორმულის გამოყენებით:
$$
x^{(n+1)} = x^{(n)} - \eta\nabla f
$$
აქ $\eta$ არის ეგრეთ წოდებული სწავლის გაბრაზება (კოდში აღვნიშნავთ lr-ით), ხოლო $\nabla f = (\frac{\partial f}{\partial x_1},\frac{\partial f}{\partial x_2})$ - $f$-ის გრადიენტი.
დასაწყისისთვის, მოდით განვსაზღვროთ x საწყისი მნიშვნელობა და ფუნქცია f:
იტვირთება…ახლა მოდით გავაკეთოთ გრადიენტური დაღმართის 15 გამეორება. თითოეულ გამეორებაში ჩვენ განვაახლებთ x კოორდინატებს და დავბეჭდავთ მათ, რათა დავრწმუნდეთ, რომ ვუახლოვდებით მინიმალურ წერტილს (3,-2):
იტვირთება…გამოტანა
Step 0: x[0]=0.6000000238418579, x[1]=-0.4000000059604645
Step 1: x[0]=1.0800000429153442, x[1]=-0.7200000286102295
Step 2: x[0]=1.4639999866485596, x[1]=-0.9760000705718994
Step 3: x[0]=1.7711999416351318, x[1]=-1.1808000802993774
Step 4: x[0]=2.0169599056243896, x[1]=-1.3446400165557861
Step 5: x[0]=2.2135679721832275, x[1]=-1.4757120609283447
Step 6: x[0]=2.370854377746582, x[1]=-1.5805696249008179
Step 7: x[0]=2.4966835975646973, x[1]=-1.6644556522369385
Step 8: x[0]=2.597346782684326, x[1]=-1.7315645217895508
Step 9: x[0]=2.677877426147461, x[1]=-1.7852516174316406
Step 10: x[0]=2.7423019409179688, x[1]=-1.8282012939453125
Step 11: x[0]=2.793841600418091, x[1]=-1.8625609874725342
Step 12: x[0]=2.835073232650757, x[1]=-1.8900487422943115
Step 13: x[0]=2.868058681488037, x[1]=-1.912039041519165
Step 14: x[0]=2.894446849822998, x[1]=-1.929631233215332
მაგალითი 1: ხაზოვანი რეგრესია
ახლა ჩვენ საკმარისი ვიცით წრფივი რეგრესიის კლასიკური ამოცანის გადასაჭრელად. მოდით შევქმნათ მცირე სინთეზური მონაცემთა ნაკრები:
იტვირთება…იტვირთება…გამოტანა
<matplotlib.collections.PathCollection at 0x20b8e1f1ca0>
წრფივი რეგრესია განისაზღვრება სწორი ხაზით $f_{W,b}(x) = Wx+b$, სადაც $W, b$ არის მოდელის პარამეტრები, რომლებიც უნდა ვიპოვოთ. შეცდომა ჩვენს მონაცემთა ბაზაში ${x_i,y_u}{i=1}^N$ (ასევე უწოდებენ დაკარგვის ფუნქციას) შეიძლება განისაზღვროს, როგორც საშუალო კვადრატული შეცდომა: $$ \mathcal{L}(W,b) = {1\ მეტი N}\sum{i=1}^N (f_{W,b}(x_i)-y_i)^2 $$
მოდით განვსაზღვროთ ჩვენი მოდელი და დაკარგვის ფუნქცია:
იტვირთება…ჩვენ მოვამზადებთ მოდელს მინი პატჩების სერიაზე. ჩვენ გამოვიყენებთ გრადიენტულ დაშვებას, მოდელის პარამეტრების კორექტირებას შემდეგი ფორმულების გამოყენებით: $$ \დაწყება{მასივი}{l} W^{(n+1)}=W^{(n)}-\eta\frac{\partial\mathcal{L}}{\partial W} \ b^{(n+1)}=b^{(n)}-\eta\frac{\partial\mathcal{L}}{\partial b} \ \დასრულება{მასივი} $$
იტვირთება…ჩავატაროთ ტრენინგი. ჩვენ გავაკეთებთ რამდენიმე გავლას მონაცემთა ნაკრებში (ე.წ. ეპოქები), გავყოფთ მას მინიპატჩებად და გამოვიძახებთ ზემოთ განსაზღვრულ ფუნქციას:
იტვირთება…იტვირთება…გამოტანა
Epoch 0: last batch loss = 94.5247
Epoch 1: last batch loss = 9.3428
Epoch 2: last batch loss = 1.4166
Epoch 3: last batch loss = 0.5224
Epoch 4: last batch loss = 0.3807
Epoch 5: last batch loss = 0.3495
Epoch 6: last batch loss = 0.3413
Epoch 7: last batch loss = 0.3390
Epoch 8: last batch loss = 0.3384
Epoch 9: last batch loss = 0.3382
ჩვენ ახლა მივიღეთ ოპტიმიზებული პარამეტრები $W$ და $b$. Note that their values are similar to the original values used when generating the dataset ($W=2, b=1$)
იტვირთება…გამოტანა
(tensor([1.8617], requires_grad=True), tensor([1.0711], requires_grad=True))იტვირთება…გამოტანა
[<matplotlib.lines.Line2D at 0x20b8e30a850>]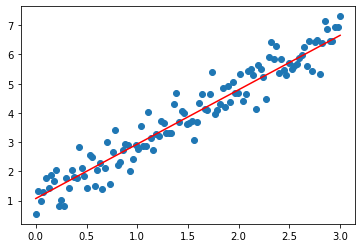
გამოთვლები GPU-ზე
გამოთვლებისთვის GPU-ს გამოსაყენებლად PyTorch მხარს უჭერს ტენსორების გადატანას GPU-ზე და გამოთვლითი გრაფიკის აგებას GPU-სთვის. ტრადიციულად, ჩვენი კოდის დასაწყისში ჩვენ განვსაზღვრავთ ხელმისაწვდომ გამოთვლით მოწყობილობას device (რომელიც არის cpu ან cuda), შემდეგ კი გადავიტანთ ყველა ტენსორს ამ მოწყობილობაზე .to(device) ზარის გამოყენებით. ჩვენ ასევე შეგვიძლია შევქმნათ ტენსორები მითითებულ მოწყობილობაზე წინასწარ, პარამეტრის device=... გადაცემით ტენზორის შექმნის კოდზე. ასეთი კოდი მუშაობს ცვლილებების გარეშე როგორც CPU-ზე, ასევე GPU-ზე:
იტვირთება…გამოტანა
Doing computations on cpu
Epoch 0: last batch loss = 94.5247
Epoch 1: last batch loss = 9.3428
Epoch 2: last batch loss = 1.4166
Epoch 3: last batch loss = 0.5224
Epoch 4: last batch loss = 0.3807
Epoch 5: last batch loss = 0.3495
Epoch 6: last batch loss = 0.3413
Epoch 7: last batch loss = 0.3390
Epoch 8: last batch loss = 0.3384
Epoch 9: last batch loss = 0.3382
მაგალითი 2: კლასიფიკაცია
ახლა განვიხილავთ ორობითი კლასიფიკაციის პრობლემას. ასეთი პრობლემის კარგი მაგალითი იქნება სიმსივნის კლასიფიკაცია ავთვისებიანსა და კეთილთვისებიანს შორის მისი ზომისა და ასაკის მიხედვით.
ძირითადი მოდელი რეგრესიის მსგავსია, მაგრამ ჩვენ უნდა გამოვიყენოთ სხვადასხვა დანაკარგის ფუნქცია. დავიწყოთ ნიმუშის მონაცემების გენერირებით:
იტვირთება…იტვირთება…იტვირთება…გამოტანა
C:\Users\dmitryso\AppData\Local\Temp/ipykernel_89704/2721537645.py:17: UserWarning: Matplotlib is currently using module://matplotlib_inline.backend_inline, which is a non-GUI backend, so cannot show the figure.
fig.show()
ტრენინგი ერთშრიანი პერცეპტრონი
მოდით გამოვიყენოთ PyTorch გრადიენტური გამოთვლითი აპარატურა ერთშრიანი პერცეპტრონის მოსამზადებლად.
ჩვენს ნერვულ ქსელს ექნება 2 შეყვანა და 1 გამომავალი. წონის მატრიცას $W$ ექნება ზომა $2\ჯერ1$ და მიკერძოების ვექტორი $b$ -- $1$.
იმისათვის, რომ ჩვენი კოდი უფრო სტრუქტურირებული გავხადოთ, მოდით დავაჯგუფოთ ყველა პარამეტრი ერთ კლასში:
იტვირთება…გაითვალისწინეთ, რომ ჩვენ ვიყენებთ
W.data.zero_()W.zero_()-ის ნაცვლად. ჩვენ ეს უნდა გავაკეთოთ, რადგან ჩვენ არ შეგვიძლია პირდაპირ შევცვალოთ ტენზორი, რომელსაც აკონტროლებენ Autograd მექანიზმის გამოყენებით.
ძირითადი მოდელი იქნება იგივე, რაც წინა მაგალითში, მაგრამ დაკარგვის ფუნქცია იქნება ლოგისტიკური დანაკარგი. ლოგისტიკური დანაკარგის გამოსაყენებლად, ჩვენ უნდა მივიღოთ ალბათობა, როგორც ჩვენი ქსელის გამოსავალი, ანუ გამომავალი $z$ უნდა მივიყვანოთ დიაპაზონში [0,1] sigmoid აქტივაციის ფუნქციის გამოყენებით: $p=\sigma(z)$.
თუ მივიღებთ ალბათობას $p_i$ i-ის შეყვანის მნიშვნელობისთვის, რომელიც შეესაბამება $y_i\in{0,1}$ ფაქტობრივ კლასს, ჩვენ გამოვთვლით დანაკარგს $\mathcal{L_i}=-(y_i\log p_i + (1-y_i)log(1-p_i))$.
PyTorch-ში ორივე ეს ნაბიჯი (სიგმოიდის გამოყენება და შემდეგ ლოგისტიკური დაკარგვა) შეიძლება განხორციელდეს ერთი ზარის გამოყენებით binary_cross_entropy_with_logits ფუნქციაზე. იმის გამო, რომ ჩვენ ვავარჯიშებთ ჩვენს ქსელს მინი პარტიაში, ჩვენ უნდა გამოვთვალოთ დანაკარგის საშუალო რაოდენობა მინი-სერიების ყველა ელემენტში - და ეს ასევე ავტომატურად ხდება binary_cross_entropy_with_logits ფუნქციით:
ზარი
binary_crossentropy_with_logits-ზე უდრის ზარსsigmoid-ზე, რასაც მოჰყვება ზარიbinary_crossentropy-ზე
იტვირთება…ჩვენი მონაცემების გადასახედად, ჩვენ გამოვიყენებთ ჩაშენებულ PyTorch მექანიზმს მონაცემთა ნაკრების სამართავად. იგი ეფუძნება ორ კონცეფციას:
- Dataset არის მონაცემთა ძირითადი წყარო, ის შეიძლება იყოს Iterable ან Map-style
- Dataloader პასუხისმგებელია მონაცემთა ნაკრებიდან ჩატვირთვაზე და მინი პატჩებად დაყოფაზე.
ჩვენს შემთხვევაში, ჩვენ განვსაზღვრავთ მონაცემთა ბაზას ტენზორის საფუძველზე და დავყოფთ მას 16 ელემენტისგან შემდგარ მინი პარტიებად. თითოეული მინი პარტია შეიცავს ორ ტენსორს, შეყვანის მონაცემებს (ზომა=16x2) და ლეიბლებს (მთლიანი ტიპის 16 სიგრძის ვექტორი - კლასის ნომერი).
იტვირთება…გამოტანა
[tensor([[ 1.5442, 2.5290],
[-1.6284, 0.0772],
[-1.7141, 2.4770],
[-1.4951, 0.7320],
[-1.6899, 0.9243],
[-0.9474, -0.7681],
[ 3.8597, -2.2951],
[-1.3944, 1.4300],
[ 4.3627, 3.1333],
[-1.0973, -1.7011],
[-2.5532, -0.0777],
[-1.2661, -0.3167],
[ 0.3921, 1.8406],
[ 2.2091, -1.6045],
[ 1.8383, -1.4861],
[ 0.7173, -0.9718]]),
tensor([1., 0., 0., 0., 0., 0., 1., 0., 1., 0., 0., 0., 1., 1., 1., 1.])]ახლა ჩვენ შეგვიძლია შევამოწმოთ მთელი მონაცემთა ბაზა, რათა გავავარჯიშოთ ჩვენი ქსელი 15 ეპოქისთვის:
იტვირთება…გამოტანა
Epoch 0: last batch loss = 0.6491
Epoch 1: last batch loss = 0.6064
Epoch 2: last batch loss = 0.5822
Epoch 3: last batch loss = 0.5679
Epoch 4: last batch loss = 0.5592
Epoch 5: last batch loss = 0.5537
Epoch 6: last batch loss = 0.5501
Epoch 7: last batch loss = 0.5478
Epoch 8: last batch loss = 0.5463
Epoch 9: last batch loss = 0.5454
Epoch 10: last batch loss = 0.5447
Epoch 11: last batch loss = 0.5443
Epoch 12: last batch loss = 0.5441
Epoch 13: last batch loss = 0.5439
Epoch 14: last batch loss = 0.5438
მიღებული პარამეტრები:
იტვირთება…გამოტანა
tensor([[ 0.1330],
[-0.2810]], requires_grad=True) tensor([0.], requires_grad=True)
იმისათვის, რომ დავრწმუნდეთ, რომ ჩვენი ტრენინგი მუშაობდა, მოდით დავხატოთ ხაზი, რომელიც ჰყოფს ორ კლასს. გამოყოფის ხაზი განისაზღვრება განტოლებით $W\ჯერ x + b = 0.5$
იტვირთება…გამოტანა
C:\Users\dmitryso\AppData\Local\Temp/ipykernel_89704/2721537645.py:17: UserWarning: Matplotlib is currently using module://matplotlib_inline.backend_inline, which is a non-GUI backend, so cannot show the figure.
fig.show()
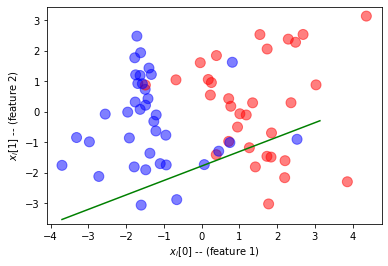
მოდით არ გამოვთვალოთ სიზუსტე ვალიდაციის მონაცემთა ბაზაში:
იტვირთება…გამოტანა
tensor(0.7333)მოდი ავხსნათ რა ხდება აქ:
predარის პროგნოზირებული ალბათობების ვექტორი მთელი ვალიდაციის მონაცემთა ნაკრებისთვის. ჩვენ ვიანგარიშებთ მას ჩვენი ქსელის მეშვეობით ორიგინალური ვალიდაციის მონაცემებისvalid_xგაშვებით და ალბათობების მისაღებადsigmoid-ის გამოყენებით.pred.view(-1)ქმნის ორიგინალური ტენზორის გაბრტყელ ხედს.viewმსგავსიაreshapeფუნქციის numpy-ში.pred.view(-1)>0.5აბრუნებს ლოგიკური ტენსორის ან ჭეშმარიტების მნიშვნელობას, რომელიც აჩვენებს წინასწარმეტყველურ კლასს (False = კლასი 0, True = კლასი 1)- ანალოგიურად,
torch.tensor(valid_labels)>0.5)ქმნის ჭეშმარიტების მნიშვნელობების ლოგიკურ ტენსორს ვალიდაციის ეტიკეტებისთვის - ჩვენ შევადარებთ ამ ორ ტენსორს ელემენტის მიხედვით და მივიღებთ სხვა ლოგიკურ ტენსორს, სადაც
Trueშეესაბამება სწორ პროგნოზს, ხოლოFalse- არასწორს. - ჩვენ ამ ტენსორს ვცვლით მცურავ წერტილად და ვიღებთ მის საშუალო მნიშვნელობას
torch.mean-ის გამოყენებით - ეს არის სასურველი სიზუსტე
ნერვული ქსელები და ოპტიმიზატორები
PyTorch-ში განსაზღვრულია სპეციალური მოდული torch.nn.Module, რომელიც წარმოადგენს ნერვულ ქსელს. თქვენი საკუთარი ნერვული ქსელის განსაზღვრის ორი მეთოდი არსებობს:
- თანმიმდევრული, სადაც თქვენ უბრალოდ მიუთითებთ ფენების სიას, რომლებიც მოიცავს თქვენს ქსელს
- როგორც კლასი მემკვიდრეობით
torch.nn.Module-დან
პირველი მეთოდი საშუალებას გაძლევთ მიუთითოთ სტანდარტული ქსელები ფენების თანმიმდევრული შემადგენლობით, ხოლო მეორე უფრო მოქნილია და იძლევა თვითნებური რთული არქიტექტურის ქსელების გამოხატვის შესაძლებლობას.
მოდულების შიგნით შეგიძლიათ გამოიყენოთ სტანდარტული ფენები, როგორიცაა:
Linear- მკვრივი წრფივი ფენა, ერთშრიანი პერცეპტრონის ტოლფასი. მას აქვს იგივე არქიტექტურა, რაც ზემოთ განვსაზღვრეთ ჩვენი ქსელისთვისSoftmax,Sigmoid,ReLU- ფენები, რომლებიც შეესაბამება აქტივაციის ფუნქციებს- ასევე არსებობს სხვა ფენები ქსელის სპეციალური ტიპებისთვის - კონვოლუცია, განმეორებადი და ა.შ. ბევრ მათგანს მოგვიანებით განვიხილავთ.
PyTorch-ში აქტივაციის ფუნქციისა და დაკარგვის ფუნქციების უმეტესობა ხელმისაწვდომია ორი ფორმით: ფუნქციის (
torch.nn.functionalსახელთა სივრცის შიგნით) და შრის სახით (torch.nnსახელთა სივრცის შიგნით). აქტივაციის ფუნქციებისთვის ხშირად უფრო ადვილია ფუნქციური ელემენტების გამოყენებაtorch.nn.functional-დან, ცალკეული ფენის ობიექტის შექმნის გარეშე.
თუ გვსურს ვავარჯიშოთ ერთშრიანი პერცეტრონი, შეგვიძლია გამოვიყენოთ ერთი ჩაშენებული Linear ფენა:
იტვირთება…გამოტანა
[Parameter containing:
tensor([[-0.0422, 0.1821]], requires_grad=True), Parameter containing:
tensor([0.6582], requires_grad=True)]
როგორც ხედავთ, parameters() მეთოდი აბრუნებს ყველა იმ პარამეტრს, რომელიც უნდა დარეგულირდეს ტრენინგის დროს. ისინი შეესაბამება წონის მატრიცას $W$ და მიკერძოებას $b$. თქვენ შეგიძლიათ შენიშნოთ, რომ მათ აქვთ requires_grad დაყენებული True, რადგან ჩვენ გვჭირდება გრადიენტების გამოთვლა პარამეტრების მიმართ.
PyTorch ასევე შეიცავს ჩაშენებულ ოპტიმიზატორებს, რომლებიც ახორციელებენ ოპტიმიზაციის მეთოდებს, როგორიცაა გრადიენტული წარმოშობა. აი, როგორ შეგვიძლია განვსაზღვროთ სტოქასტური გრადიენტული დაღმართის ოპტიმიზატორი:
იტვირთება…ოპტიმიზატორის გამოყენებით, ჩვენი სასწავლო ციკლი ასე გამოიყურება:
იტვირთება…გამოტანა
Epoch 0: last batch loss = 0.7596041560173035, val acc = 0.5333333611488342
Epoch 1: last batch loss = 0.6602361798286438, val acc = 0.6000000238418579
Epoch 2: last batch loss = 0.5847358107566833, val acc = 0.6666666865348816
Epoch 3: last batch loss = 0.5263020992279053, val acc = 0.7333333492279053
Epoch 4: last batch loss = 0.48015740513801575, val acc = 0.800000011920929
Epoch 5: last batch loss = 0.4430023431777954, val acc = 0.8666666746139526
Epoch 6: last batch loss = 0.41254672408103943, val acc = 0.8666666746139526
Epoch 7: last batch loss = 0.3871781527996063, val acc = 0.800000011920929
Epoch 8: last batch loss = 0.3657420873641968, val acc = 0.800000011920929
Epoch 9: last batch loss = 0.34739670157432556, val acc = 0.800000011920929
თქვენ შეიძლება შეამჩნიოთ, რომ ჩვენი ქსელის მონაცემების შესატანად გამოსაყენებლად, ჩვენ შეგვიძლია გამოვიყენოთ
net(x)net.forward(x)-ის ნაცვლად, რადგანnn.Moduleახორციელებს Python__call__()ფუნქციას
ამის გათვალისწინებით, ჩვენ შეგვიძლია განვსაზღვროთ ზოგადი train ფუნქცია:
იტვირთება…გამოტანა
Epoch 0: last batch loss = 0.48486900329589844, val acc = 0.7333333492279053
Epoch 1: last batch loss = 0.41338109970092773, val acc = 0.800000011920929
Epoch 2: last batch loss = 0.35756850242614746, val acc = 0.800000011920929
Epoch 3: last batch loss = 0.31495171785354614, val acc = 0.800000011920929
Epoch 4: last batch loss = 0.2824164032936096, val acc = 0.800000011920929
Epoch 5: last batch loss = 0.2572754919528961, val acc = 0.800000011920929
Epoch 6: last batch loss = 0.23751722276210785, val acc = 0.800000011920929
Epoch 7: last batch loss = 0.2217157930135727, val acc = 0.800000011920929
Epoch 8: last batch loss = 0.2088666558265686, val acc = 0.800000011920929
Epoch 9: last batch loss = 0.19824868440628052, val acc = 0.800000011920929
ქსელის, როგორც ფენების თანმიმდევრობის განსაზღვრა
ახლა მოდით ვავარჯიშოთ მრავალშრიანი პერცეტრონი. ის შეიძლება განისაზღვროს მხოლოდ ფენების თანმიმდევრობის მითითებით. შედეგად მიღებული ობიექტი ავტომატურად მიიღებს მემკვიდრეობას Module-დან, მაგ. მას ასევე ექნება parameters მეთოდი, რომელიც დააბრუნებს მთელი ქსელის ყველა პარამეტრს.
იტვირთება…გამოტანა
Sequential(
(0): Linear(in_features=2, out_features=5, bias=True)
(1): Sigmoid()
(2): Linear(in_features=5, out_features=1, bias=True)
)
ჩვენ შეგვიძლია მოვამზადოთ ეს მრავალშრიანი ქსელი ფუნქციის train გამოყენებით, რომელიც ზემოთ განვსაზღვრეთ:
იტვირთება…გამოტანა
Epoch 0: last batch loss = 0.5835739970207214, val acc = 0.800000011920929
Epoch 1: last batch loss = 0.4642275869846344, val acc = 0.800000011920929
Epoch 2: last batch loss = 0.35158076882362366, val acc = 0.800000011920929
Epoch 3: last batch loss = 0.26132312417030334, val acc = 0.800000011920929
Epoch 4: last batch loss = 0.19465585052967072, val acc = 0.800000011920929
Epoch 5: last batch loss = 0.14735405147075653, val acc = 0.800000011920929
Epoch 6: last batch loss = 0.11454981565475464, val acc = 0.800000011920929
Epoch 7: last batch loss = 0.09244414418935776, val acc = 0.800000011920929
Epoch 8: last batch loss = 0.07805468142032623, val acc = 0.800000011920929
Epoch 9: last batch loss = 0.06894762068986893, val acc = 0.800000011920929
ქსელის კლასის განსაზღვრა
torch.nn.Module-დან მემკვიდრეობით მიღებული კლასის გამოყენება უფრო მოქნილი მეთოდია, რადგან ჩვენ შეგვიძლია განვსაზღვროთ ნებისმიერი გამოთვლა მის შიგნით. Module ავტომატიზირებს ბევრ რამეს, მაგ. ის ავტომატურად იგებს ყველა შიდა ცვლადს, რომელიც არის PyTorch ფენა და აგროვებს მათ პარამეტრებს ოპტიმიზაციისთვის. თქვენ უბრალოდ უნდა განსაზღვროთ ქსელის ყველა ფენა, როგორც კლასის წევრები:
იტვირთება…გამოტანა
MyNet(
(fc1): Linear(in_features=2, out_features=10, bias=True)
(func): ReLU()
(fc2): Linear(in_features=10, out_features=1, bias=True)
)
იტვირთება…გამოტანა
Epoch 0: last batch loss = 0.7821246981620789, val acc = 0.46666666865348816
Epoch 1: last batch loss = 0.7457502484321594, val acc = 0.5333333611488342
Epoch 2: last batch loss = 0.7120334506034851, val acc = 0.5333333611488342
Epoch 3: last batch loss = 0.6811249256134033, val acc = 0.6666666865348816
Epoch 4: last batch loss = 0.6533011794090271, val acc = 0.7333333492279053
Epoch 5: last batch loss = 0.627849280834198, val acc = 0.7333333492279053
Epoch 6: last batch loss = 0.6030643582344055, val acc = 0.800000011920929
Epoch 7: last batch loss = 0.5775002837181091, val acc = 0.800000011920929
Epoch 8: last batch loss = 0.5522137880325317, val acc = 0.8666666746139526
Epoch 9: last batch loss = 0.5250465869903564, val acc = 0.8666666746139526
ამოცანა 1: დახაზეთ ზარალის ფუნქციისა და სიზუსტის გრაფიკები ტრენინგის დროს და დამოწმების მონაცემები
ამოცანა 2: სცადეთ გადაჭრათ MNIST კლასიფიკაციის პრობლემა ამ კოდის გამოყენებით. მინიშნება: გამოიყენეთ crossentropy_with_logits როგორც დაკარგვის ფუნქცია.
ქსელის განსაზღვრა, როგორც PyTorch Lightning მოდული
მოდით ჩავაკრათ დაწერილი PyTorch მოდელის კოდი PyTorch Lightining მოდულში. ეს საშუალებას გაძლევთ იმუშაოთ თქვენს მოდელთან უფრო მოხერხებულად და მოქნილად, სხვადასხვა Lightining მეთოდების გამოყენებით ვარჯიშისა და სიზუსტის ტესტირებისთვის.
ჯერ PyTorch Lightining-ის ინსტალაცია და იმპორტი გვჭირდება. ეს შეიძლება გაკეთდეს ბრძანებით
იტვირთება…იტვირთება…იმისათვის, რომ ჩვენმა კოდმა იმუშაოს Lightning-ში, ჩვენ უნდა გავაკეთოთ შემდეგი:
- შექმენით
pl.LightningModule-ის ქვეკლასი და დაამატეთ მას მოდელის არქიტექტურა__init__მეთოდით დაforwardpass მეთოდით. - გამოყენებული ოპტიმიზატორი გადაიტანეთ
configure_optimizers()მეთოდზე. - განსაზღვრეთ ტრენინგის და ვალიდაციის პროცესი შესაბამისად
training_stepდაvalidation_stepმეთოდებში. - (სურვილისამებრ) განახორციელეთ ტესტირების (
test_stepმეთოდი) და პროგნოზირების პროცესი (predict_stepმეთოდი).
ასევე უნდა გვესმოდეს, რომ PyTorch Lightning-ს აქვს მოდელების ჩაშენებული თარგმანი სხვადასხვა მოწყობილობებზე, იმისდა მიხედვით, თუ სად მდებარეობს DataLoaders შემომავალი მონაცემები. ამიტომ, ყველა ზარი .cuda() ან .to(device) უნდა წაიშალოს კოდიდან.
იტვირთება…მოდით ასევე დავამატოთ ვალიდაცია Dataset და DataLoader:
იტვირთება…ახლა ჩვენი მოდელი მზად არის ტრენინგისთვის. Pytorch Lightning-ში ეს პროცესი ხორციელდება Trainer კლასის ობიექტის მეშვეობით, რომელიც არსებითად "არევს" მოდელს ნებისმიერ მონაცემთა ნაკრებთან.
იტვირთება…გამოტანა
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
--------------------------------
0 | fc1 | Linear | 30
1 | func | ReLU | 0
2 | fc2 | Linear | 11
--------------------------------
41 Trainable params
0 Non-trainable params
41 Total params
0.000 Total estimated model params size (MB)
Sanity Checking: 0it [00:00, ?it/s]Epoch 0: val loss = 0.7213451266288757 val acc = 0.3333333432674408
Training: 0it [00:00, ?it/s]Validation: 0it [00:00, ?it/s]Epoch 1: val loss = 0.7164624333381653 val acc = 0.3333333432674408
Validation: 0it [00:00, ?it/s]Epoch 2: val loss = 0.7117107510566711 val acc = 0.3333333432674408
Takeaways
- PyTorch გაძლევთ საშუალებას იმუშაოთ ტენსორებზე დაბალ დონეზე, თქვენ გაქვთ ყველაზე მეტი მოქნილობა.
- არსებობს მოსახერხებელი ხელსაწყოები მონაცემებთან მუშაობისთვის, როგორიცაა Datasets და Dataloaders.
- თქვენ შეგიძლიათ განსაზღვროთ ნერვული ქსელის არქიტექტურა
Sequentialსინტაქსის გამოყენებით, ან კლასის მემკვიდრეობითtorch.nn.Module-დან - ქსელის განსაზღვრისა და ტრენინგის კიდევ უფრო მარტივი მიდგომისთვის - გადახედეთ PyTorch Lightning-ს