ეს ნოუთბუქი AI დამწყებთათვის სასწავლო პროგრამა-ის ნაწილია.
იტვირთება…ზოგიერთი თეორია
გენეტიკური ალგორითმები (GA) ეფუძნება ევოლუციური მიდგომას AI-ს მიმართ, რომელშიც გამოყენებულია მოსახლეობის ევოლუციის მეთოდები მოცემული პრობლემის ოპტიმალური გადაწყვეტის მისაღებად. ისინი შემოგვთავაზეს 1975 წელს ჯონ ჰენრი ჰოლანდი-ის მიერ.
გენეტიკური ალგორითმები ეფუძნება შემდეგ იდეებს:
- პრობლემის სწორი გადაწყვეტილებები შეიძლება წარმოდგენილი იყოს როგორც გენები
- Crossover საშუალებას გვაძლევს გავაერთიანოთ ორი გამოსავალი, რათა მივიღოთ ახალი მოქმედი გადაწყვეტა
- Selection გამოიყენება უფრო ოპტიმალური გადაწყვეტილებების შესარჩევად ზოგიერთი ფიტნეს ფუნქციის გამოყენებით
- მუტაციები დანერგილია ოპტიმიზაციის დესტაბილიზაციისა და ლოკალური მინიმალურიდან გამოსაყვანად
თუ გსურთ გენეტიკური ალგორითმის დანერგვა, დაგჭირდებათ შემდეგი:
- ვიპოვოთ ჩვენი პრობლემის გადაწყვეტის კოდირების მეთოდი გენების $g\in\Gamma$-ის გამოყენებით
- $\Gamma$ გენების ნაკრებზე უნდა განვსაზღვროთ fitness ფუნქცია $\mathrm{fit}: \Gamma\to\mathbb{R}$. ფუნქციის უფრო მცირე მნიშვნელობები შეესაბამება უკეთეს გადაწყვეტილებებს.
- განვსაზღვროთ ჯვარედინი მექანიზმი, რომ დააკავშიროთ ორი გენი ერთად ახალი მოქმედი გადაწყვეტის მისაღებად $\mathrm{crossover}: \Gamma^2\to\Gamma$.
- მუტაციის მექანიზმის განსაზღვრა $\mathrm{mutate}: \Gamma\to\Gamma$. ხშირ შემთხვევაში, კროსოვერი და მუტაცია საკმაოდ მარტივი ალგორითმებია გენების მანიპულირებისთვის, როგორც რიცხვითი თანმიმდევრობების ან ბიტების ვექტორების სახით.
გენეტიკური ალგორითმის სპეციფიკური განხორციელება შეიძლება განსხვავდებოდეს შემთხვევიდან კონკრეტულ შემთხვევაში, მაგრამ საერთო სტრუქტურა შემდეგია:
- აირჩიეთ საწყისი პოპულაცია $G\subset\Gamma$
- შემთხვევით აირჩიეთ ერთ-ერთი ოპერაცია, რომელიც შესრულდება ამ ეტაპზე: კროსოვერი ან მუტაცია
- კროსოვერი:
- შემთხვევით აირჩიეთ ორი გენი $g_1, g_2 \G$-ში
- გამოთვალეთ კროსოვერი $g=\mathrm{კროსოვერი}(g_1,g_2)$
- თუ $\mathrm{fit}(g)<\mathrm{fit}(g_1)$ ან $\mathrm{fit}(g)<\mathrm{fit}(g_2)$ - შეცვალეთ შესაბამისი გენი პოპულაციაში $g$-ით.
- მუტაცია - აირჩიეთ შემთხვევითი გენი $g\G$-ში და შეცვალეთ იგი $\mathrm{mutate}(g)$-ით
- გაიმეორეთ მე-2 საფეხურიდან, სანამ არ მივიღებთ საკმარისად მცირე მნიშვნელობას $\mathrm{fit}$, ან სანამ არ მიიღწევა ნაბიჯების რაოდენობის ლიმიტი.
ამოცანები, როგორც წესი, წყვეტს GA:
- განრიგის ოპტიმიზაცია
- ოპტიმალური შეფუთვა
- ოპტიმალური ჭრა
- ამომწურავი ძიების დაჩქარება
პრობლემა 1: სამართლიანი განძის გაყოფა
ამოცანა: ორმა ადამიანმა იპოვა საგანძური, რომელიც შეიცავს სხვადასხვა ზომის (და, შესაბამისად, განსხვავებული ფასის) ბრილიანტებს. მათ უნდა გაანაწილონ საგანძური ორ ნაწილად ისე, რომ ფასში სხვაობა იყოს 0 (ან მინიმალური).
ფორმალური განმარტება: ჩვენ გვაქვს რიცხვების ნაკრები $S$. ჩვენ უნდა გავყოთ ის ორ ქვეჯგუფად $S_1$ და $S_2$, ისე, რომ $$\left|\sum_{i\in S_1}i - \sum_{j\in S_2}j\right|\to\min$$ და $S_1\cup S_2=S$, $S_1\cap S_2=\emptyset$.
პირველ რიგში, მოდით განვსაზღვროთ ნაკრები $S$:
იტვირთება…გამოტანა
[8344 2197 9335 3131 5863 9429 3818 9791 15 5455 1396 9538 4872 6549
8587 5986 6021 9764 8102 5083 5739 7684 8498 3007 6599 820 7490 2372
9370 5235 3525 3154 859 1906 8159 3950 2173 2988 2050 349 8713 2284
4177 6033 1651 9176 5049 8201 171 5081 1216 3756 4711 2757 7738 1272
5650 6584 5395 9004 7797 969 8104 1283 1392 4001 5768 445 274 256
8239 8015 4381 9021 1189 8879 1411 3539 6526 8011 136 7230 2332 451
5702 2989 4320 2446 9578 8486 4027 2410 9588 8981 2177 1493 3232 9151
4835 5594 6859 8394 369 3200 126 4259 2283 7755 2014 2458 8327 8082
7413 7622 1206 5533 8751 3495 5868 8472 6850 3958 3149 4672 4810 6274
4700 6134 4627 4616 6656 9949 884 2256 7419 1926 7973 5319 5967 9158
3823 7697 9466 5675 5412 9784 5426 8209 3421 1136 6047 4429 8001 4417
1381 722 7350 6018 6235 7860 5853 7660 5937 6242 1 9552 3971 8302
2633 9227 7283 154 8599 4269 9392 8539 1630 368 2409 9351 3838 9814
6186 5743 5083 1325 1610 779 3643 3262 5768 8725 961 4611 6310 4788
1648 5951 8118 7779]
მოდით დავაშიფროთ პრობლემის ყოველი შესაძლო გადაწყვეტა ორობითი ვექტორით $B\in{0,1}^N$, სადაც რიცხვი $i$-th პოზიციაზე გვიჩვენებს, რომელ კომპლექტს ($S_1$ ან $S_2$) ეკუთვნის $i$-th რიცხვი თავდაპირველ კომპლექტში $S$. generate ფუნქცია გამოიმუშავებს იმ შემთხვევით ორობით ვექტორებს.
იტვირთება…გამოტანა
[1 0 0 1 1 1 1 1 0 1 1 1 0 0 1 0 1 1 1 0 0 1 1 0 1 1 0 0 1 0 1 0 1 0 1 1 1
0 1 1 1 0 1 0 0 1 0 0 1 1 0 1 0 1 1 0 0 1 0 0 0 1 1 0 1 1 0 0 0 0 1 0 1 0
1 0 0 0 0 0 1 1 0 1 0 0 1 0 1 0 0 1 1 0 0 1 1 1 0 0 1 1 0 1 1 0 0 0 0 1 1
1 0 1 0 0 1 1 1 1 1 1 1 1 0 1 0 1 1 1 1 1 1 0 1 0 1 0 1 0 0 1 1 1 0 0 1 1
0 1 1 0 1 1 0 0 0 1 1 0 0 0 0 0 0 0 0 1 1 0 1 1 1 0 0 1 1 0 1 1 0 0 1 1 0
0 0 0 1 0 1 1 0 1 1 0 1 0 0 0]
მოდით განვსაზღვროთ fit ფუნქცია, რომელიც ითვლის გადაწყვეტის "ფასს". ეს იქნება სხვაობა ჯამს ან ორ კომპლექტს შორის, $S_1$ და $S_2$:
იტვირთება…გამოტანა
133784ახლა ჩვენ უნდა განვსაზღვროთ ფუნქციები მუტაციისა და გადაკვეთისთვის:
- მუტაციისთვის ჩვენ ავირჩევთ ერთ შემთხვევით ბიტს და უარვყოფთ მას (0-დან 1-მდე შეცვლა და პირიქით)
- კროსოვერისთვის, ჩვენ ავიღებთ რამდენიმე ბიტს ერთი ვექტორიდან, ხოლო ზოგ ბიტს მეორე ვექტორიდან. ჩვენ გამოვიყენებთ იგივე
generateფუნქციას, რათა შემთხვევით ავირჩიოთ, რომელი ბიტი ავიღოთ შეყვანის ნიღბებიდან.
იტვირთება…მოდით შევქმნათ გადაწყვეტილებების საწყისი პოპულაცია $P$ ზომის pop_size:
იტვირთება…ახლა მთავარი ფუნქციაა ევოლუციის შესრულება. n არის ევოლუციის საფეხურების რაოდენობა, რომელიც უნდა გაიარო. ყოველ ნაბიჯზე:
- 30%-იანი ალბათობით ვასრულებთ მუტაციას და ელემენტს ყველაზე ცუდი
fitფუნქციით ვანაცვლებთ მუტაციური ელემენტით - 70%-იანი ალბათობით ვასრულებთ კროსოვერს
ფუნქცია აბრუნებს საუკეთესო გამოსავალს (გენი, რომელიც შეესაბამება საუკეთესო ხსნარს) და პოპულაციაში მინიმალური მორგების ფუნქციის ისტორიას თითოეულ გამეორებაზე.
იტვირთება…გამოტანა
[0 0 0 1 1 0 0 0 0 1 1 1 0 1 0 0 0 1 0 1 0 1 0 1 0 1 1 0 0 0 0 0 1 0 1 1 0
0 0 0 1 1 0 0 1 0 0 0 0 0 1 0 0 1 1 1 1 1 1 1 0 1 1 0 1 1 1 1 1 0 1 0 0 0
0 1 1 1 0 1 0 1 1 1 1 1 0 0 0 1 1 0 1 0 0 1 0 0 1 1 1 1 1 1 1 1 0 1 0 1 1
0 1 1 0 0 0 0 1 1 1 1 0 1 0 0 1 0 1 1 1 0 1 0 0 0 0 0 0 1 1 0 0 0 1 1 0 0
1 0 1 1 1 1 1 0 1 0 1 0 1 1 1 0 0 0 1 1 0 0 0 0 0 0 1 1 1 0 1 0 0 0 1 0 1
0 1 0 1 0 0 1 1 1 0 1 1 0 0 1] 4
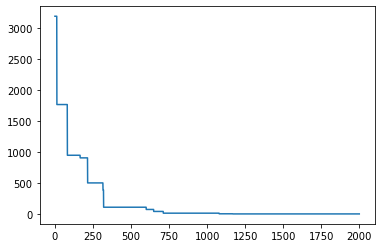
თქვენ ხედავთ, რომ ჩვენ მოვახერხეთ fit ფუნქციის საკმაოდ მინიმიზაცია! აქ არის გრაფიკი, რომელიც გვიჩვენებს, თუ როგორ იქცევა fit ფუნქცია მთელი პოპულაციისთვის პროცესის განმავლობაში.
იტვირთება…გამოტანა
პრობლემა 2: N Queens პრობლემა
ამოცანა: თქვენ უნდა მოათავსოთ $N$-ის დედოფალები $N\ჯერ N$ ზომის ჭადრაკის დაფაზე ისე, რომ ისინი ერთმანეთს არ შეუტიონ.
უპირველეს ყოვლისა, მოვაგვაროთ პრობლემა გენეტიკური ალგორითმების გარეშე, სრული ძიების გამოყენებით. ჩვენ შეგვიძლია წარმოვადგინოთ დაფის მდგომარეობა $L$ სიით, სადაც $i$-th რიცხვი სიაში არის დედოფლის ჰორიზონტალური პოზიცია $i$-ე მწკრივში. სავსებით აშკარაა, რომ თითოეულ ხსნარს ექნება მხოლოდ ერთი დედოფალი რიგზე და თითოეულ მწკრივს ექნება დედოფალი.
ჩვენი მიზანი იქნება პრობლემის პირველი გამოსავლის პოვნა, რის შემდეგაც შევწყვეტთ ძიებას. თქვენ შეგიძლიათ მარტივად გააფართოვოთ ეს ფუნქცია დედოფლებისთვის ყველა შესაძლო პოზიციის შესაქმნელად.
იტვირთება…გამოტანა
[1, 5, 8, 6, 3, 7, 2, 4]
Trueახლა მოდით გავზომოთ რამდენი ხანი სჭირდება 20 დედოფლის პრობლემის გადაწყვეტას:
იტვირთება…გამოტანა
10.6 s ± 2.17 s per loop (mean ± std. dev. of 7 runs, 1 loop each)
ახლა მოდით გადავჭრათ იგივე პრობლემა გენეტიკური ალგორითმის გამოყენებით. ეს გამოსავალი შთაგონებულია ეს ბლოგის პოსტი-ით.
ჩვენ წარმოვადგენთ თითოეულ ამოხსნას $N$ სიგრძის ერთი და იგივე სიით და fit ფუნქციის სახით ავიღებთ დედოფლების რაოდენობას, რომლებიც თავს ესხმიან ერთმანეთს:
იტვირთება…ვინაიდან ფიტნესის ფუნქციის გამოთვლა შრომატევადია, მოდით შევინახოთ თითოეული გამოსავალი პოპულაციაში ფიტნეს ფუნქციის მნიშვნელობასთან ერთად. მოდით შევქმნათ საწყისი პოპულაცია:
იტვირთება…გამოტანა
[(array([2, 3, 8, 7, 5, 4, 1, 6]), 4),
(array([3, 4, 5, 1, 2, 8, 6, 7]), 8),
(array([1, 3, 7, 4, 5, 8, 6, 2]), 6),
(array([1, 5, 4, 6, 8, 3, 7, 2]), 4),
(array([3, 5, 7, 1, 8, 6, 4, 2]), 3)]ახლა ჩვენ უნდა განვსაზღვროთ მუტაციის და გადაკვეთის ფუნქციები. კროსვორდი აერთიანებს ორ გენს, არღვევს მათ რაღაც შემთხვევით წერტილში და აერთიანებს სხვადასხვა გენის ორ ნაწილს.
იტვირთება…გამოტანა
array([1, 2, 7, 8])ჩვენ გავაძლიერებთ გენის შერჩევის პროცესს მეტი გენის შერჩევით უკეთესი ფიტნეს ფუნქციით. გენის შერჩევის ალბათობა დამოკიდებული იქნება ფიტნეს ფუნქციაზე:
იტვირთება…ახლა განვსაზღვროთ მთავარი ევოლუციური მარყუჟი. ჩვენ ლოგიკას ოდნავ განსხვავებულად გავაკეთებთ წინა მაგალითისგან, რათა დავანახოთ, რომ შეიძლება შემოქმედებითი იყოს. ჩვენ გავაციკლებთ მანამ, სანამ არ მივიღებთ სრულყოფილ გადაწყვეტას (ფიტნეს ფუნქცია=0) და ყოველ ნაბიჯზე ვიღებთ მიმდინარე თაობას და ვაწარმოებთ იმავე ზომის ახალ თაობას. ეს კეთდება nxgeneration ფუნქციის გამოყენებით, შემდეგი ნაბიჯების გამოყენებით:
- გააუქმეთ ყველაზე უვარგისი გადაწყვეტილებები - არის
discard_unfitფუნქცია, რომელიც ამას აკეთებს - დაამატეთ კიდევ რამდენიმე შემთხვევითი გადაწყვეტა თაობას
- შეავსეთ ახალი თაობის
gen_sizeზომის ახალი თაობა თითოეული ახალი გენისთვის შემდეგი ნაბიჯების გამოყენებით:- აირჩიეთ ორი შემთხვევითი გენი, ფიტნეს ფუნქციის პროპორციული ალბათობით
- გამოთვალეთ კროსვორდი
- გამოიყენეთ მუტაცია
mutation_probალბათობით
იტვირთება…გამოტანა
(array([4, 7, 5, 3, 1, 6, 8, 2]), 0)საინტერესოა, რომ უმეტეს შემთხვევაში ჩვენ საკმაოდ სწრაფად ვახერხებთ გამოსავლის მიღებას, მაგრამ იშვიათ შემთხვევებში ოპტიმიზაცია აღწევს ადგილობრივ მინიმუმს და პროცესი დიდხანს ჩერდება. მნიშვნელოვანია ამის გათვალისწინება საშუალო დროის გაზომვისას: მიუხედავად იმისა, რომ უმეტეს შემთხვევაში გენეტიკური ალგორითმი უფრო სწრაფი იქნება, ვიდრე სრული ძებნა, ზოგიერთ შემთხვევაში ამას შეიძლება მეტი დრო დასჭირდეს. ამ პრობლემის დასაძლევად ხშირად აზრი აქვს განსახილველი თაობების რაოდენობის შეზღუდვას და თუ გამოსავალი ვერ ვიპოვეთ, შეგვიძლია დავიწყოთ ნულიდან.
იტვირთება…გამოტანა
The slowest run took 18.71 times longer than the fastest. This could mean that an intermediate result is being cached.
26.4 s ± 28.7 s per loop (mean ± std. dev. of 7 runs, 1 loop each)