ეს არის პრაქტიკული ნოუთბუქი. წაიკითხე კოდი და შედეგები აქ, ან გაუშვი ინტერაქტიულად Google Colab-ში ან Jupyter-ში.
ვნახოთ, რა გავლენას ახდენს სწავლის მიტოვება ტრენინგზე. ჩვენ გამოვიყენებთ MNIST მონაცემთა ბაზას და მარტივ კონვოლუციურ ქსელს ამისათვის:
[3]
იტვირთება…ჩვენ განვსაზღვრავთ train ფუნქციას, რომელიც იზრუნებს ყველა სასწავლო პროცესზე, მათ შორის:
- ნერვული ქსელის არქიტექტურის განსაზღვრა მიტოვებული სიჩქარით
d - შესაბამისი ტრენინგის პარამეტრების მითითება (ოპტიმიზატორი და დაკარგვის ფუნქცია)
- ტრენინგის ჩატარება და ისტორიის შეგროვება
შემდეგ ჩვენ გავუშვებთ ამ ფუნქციას სხვადასხვა გამოტოვებული მნიშვნელობისთვის:
[7]
იტვირთება…გამოტანა
Training with dropout = 0
Epoch 1/5
938/938 [==============================] - 26s 27ms/step - loss: 0.1949 - acc: 0.9435 - val_loss: 0.0596 - val_acc: 0.9802
Epoch 2/5
938/938 [==============================] - 27s 29ms/step - loss: 0.0592 - acc: 0.9816 - val_loss: 0.0433 - val_acc: 0.9857
Epoch 3/5
938/938 [==============================] - 26s 28ms/step - loss: 0.0438 - acc: 0.9867 - val_loss: 0.0472 - val_acc: 0.9849
Epoch 4/5
938/938 [==============================] - 27s 28ms/step - loss: 0.0355 - acc: 0.9890 - val_loss: 0.0353 - val_acc: 0.9882
Epoch 5/5
938/938 [==============================] - 26s 28ms/step - loss: 0.0294 - acc: 0.9910 - val_loss: 0.0305 - val_acc: 0.9894
Training with dropout = 0.2
Epoch 1/5
938/938 [==============================] - 29s 31ms/step - loss: 0.2097 - acc: 0.9377 - val_loss: 0.0655 - val_acc: 0.9781
Epoch 2/5
938/938 [==============================] - 31s 33ms/step - loss: 0.0676 - acc: 0.9792 - val_loss: 0.0409 - val_acc: 0.9852
Epoch 3/5
938/938 [==============================] - 28s 30ms/step - loss: 0.0514 - acc: 0.9837 - val_loss: 0.0384 - val_acc: 0.9871
Epoch 4/5
938/938 [==============================] - 28s 29ms/step - loss: 0.0424 - acc: 0.9871 - val_loss: 0.0343 - val_acc: 0.9889
Epoch 5/5
938/938 [==============================] - 30s 32ms/step - loss: 0.0356 - acc: 0.9893 - val_loss: 0.0343 - val_acc: 0.9885
Training with dropout = 0.5
Epoch 1/5
938/938 [==============================] - 30s 31ms/step - loss: 0.2586 - acc: 0.9212 - val_loss: 0.0666 - val_acc: 0.9797
Epoch 2/5
938/938 [==============================] - 28s 30ms/step - loss: 0.0860 - acc: 0.9734 - val_loss: 0.0441 - val_acc: 0.9860
Epoch 3/5
938/938 [==============================] - 29s 31ms/step - loss: 0.0674 - acc: 0.9792 - val_loss: 0.0414 - val_acc: 0.9868
Epoch 4/5
938/938 [==============================] - 30s 32ms/step - loss: 0.0564 - acc: 0.9822 - val_loss: 0.0326 - val_acc: 0.9886
Epoch 5/5
938/938 [==============================] - 29s 31ms/step - loss: 0.0511 - acc: 0.9843 - val_loss: 0.0298 - val_acc: 0.9899
Training with dropout = 0.8
Epoch 1/5
938/938 [==============================] - 31s 32ms/step - loss: 0.3832 - acc: 0.8766 - val_loss: 0.0849 - val_acc: 0.9732
Epoch 2/5
938/938 [==============================] - 29s 31ms/step - loss: 0.1563 - acc: 0.9521 - val_loss: 0.0686 - val_acc: 0.9797
Epoch 3/5
938/938 [==============================] - 32s 34ms/step - loss: 0.1253 - acc: 0.9616 - val_loss: 0.0490 - val_acc: 0.9854
Epoch 4/5
938/938 [==============================] - 33s 35ms/step - loss: 0.1105 - acc: 0.9658 - val_loss: 0.0395 - val_acc: 0.9872
Epoch 5/5
938/938 [==============================] - 34s 36ms/step - loss: 0.1022 - acc: 0.9680 - val_loss: 0.0363 - val_acc: 0.9878
ახლა მოდით დავხატოთ ვალიდაციის სიზუსტის გრაფიკები სხვადასხვა გამოტოვების მნიშვნელობებისთვის, რათა დავინახოთ რამდენად სწრაფად მიდის ტრენინგი:
[16]
იტვირთება…გამოტანა
<matplotlib.legend.Legend at 0x235bc70f0d0>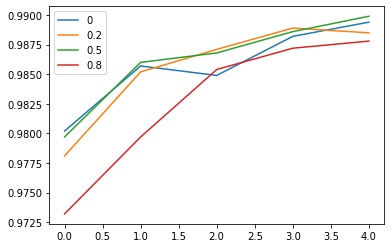
ამ გრაფიკიდან თქვენ ალბათ შეძლებთ იხილოთ შემდეგი:
- მიტოვების მნიშვნელობები 0.2-0.5 დიაპაზონში, თქვენ ნახავთ უსწრაფეს ვარჯიშს საუკეთესო საერთო შედეგებს
- მიტოვების გარეშე ($d=0$), თქვენ სავარაუდოდ დაინახავთ ნაკლებად სტაბილურ და ნელ სასწავლო პროცესს
- მაღალი მიტოვება (0.8) აუარესებს მდგომარეობას