როგორც უკვე ვისწავლეთ, ნერვული ქსელების ეფექტურად მომზადება რომ შევძლოთ, ორი რამ უნდა გავაკეთოთ:
- ტენსორებზე საოპერაციოდ, მაგ. ზოგიერთი ფუნქციის გამრავლება, დამატება და გამოთვლა, როგორიცაა sigmoid ან softmax
- ყველა გამონათქვამის გრადიენტების გამოთვლა, გრადიენტული წარმოშობის ოპტიმიზაციის შესასრულებლად
სალექციო ვიქტორინა
მიუხედავად იმისა, რომ numpy ბიბლიოთეკას შეუძლია გააკეთოს პირველი ნაწილი, ჩვენ გვჭირდება გარკვეული მექანიზმი გრადიენტების გამოსათვლელად. ჩვენი ჩარჩო-ში, რომელიც ჩვენ განვავითარეთ წინა განყოფილებაში, ჩვენ ხელით უნდა დაგვეპროგრამებინა ყველა წარმოებული ფუნქცია backward მეთოდის შიგნით, რომელიც აკეთებს უკან გავრცელებას. იდეალურ შემთხვევაში, ჩარჩომ უნდა მოგვცეს შესაძლებლობა გამოვთვალოთ ნებისმიერი გამოხატვის გრადიენტები, რომელთა განსაზღვრაც შეგვიძლია.
კიდევ ერთი მნიშვნელოვანი ის არის, რომ შეძლოთ გამოთვლების შესრულება GPU-ზე ან ნებისმიერ სხვა სპეციალიზებულ გამოთვლით ერთეულზე, როგორიცაა TPU. ღრმა ნერვული ქსელის ტრენინგი მოითხოვს ბევრ გამოთვლას და ამ გამოთვლების პარალელიზება GPU-ზე ძალიან მნიშვნელოვანია.
ტერმინი "პარალელიზაცია" ნიშნავს გამოთვლების განაწილებას მრავალ მოწყობილობაზე.
ამჟამად, ორი ყველაზე პოპულარული ნერვული ჩარჩოა: TensorFlow და PyTorch. ორივე უზრუნველყოფს დაბალი დონის API-ს, რომ იმუშაოს ტენსორებით როგორც CPU-ზე, ასევე GPU-ზე. დაბალი დონის API-ს თავზე, ასევე არის უფრო მაღალი დონის API, სახელწოდებით Keras და PyTorch Lightning შესაბამისად.
დაბალი დონის API | TensorFlow | PyTorch
მაღალი დონის API| Keras | PyTorch Lightning
დაბალი დონის API ორივე ჩარჩოში საშუალებას გაძლევთ შექმნათ ე.წ გამოთვლითი გრაფიკები. ეს გრაფიკი განსაზღვრავს, თუ როგორ უნდა გამოვთვალოთ გამომავალი (ჩვეულებრივ დაკარგვის ფუნქცია) მოცემული შეყვანის პარამეტრებით და შეიძლება გამოითვალოს GPU-ზე, თუ ის ხელმისაწვდომია. არსებობს ფუნქციები ამ გამოთვლითი გრაფიკისა და გრადიენტების გამოსათვლელად, რომლებიც შეიძლება გამოყენებულ იქნას მოდელის პარამეტრების ოპტიმიზაციისთვის.
მაღალი დონის API-ები ძირითადად განიხილავს ნერვულ ქსელებს, როგორც ფენების მიმდევრობას და აადვილებს ნერვული ქსელების უმეტესობის შექმნას. მოდელის ტრენინგი ჩვეულებრივ მოითხოვს მონაცემთა მომზადებას და შემდეგ fit ფუნქციის გამოძახებას სამუშაოს შესასრულებლად.
მაღალი დონის API საშუალებას გაძლევთ ძალიან სწრაფად ააწყოთ ტიპიური ნერვული ქსელები, ბევრი დეტალის შესახებ ფიქრის გარეშე. ამავდროულად, დაბალი დონის API გვთავაზობს გაცილებით მეტ კონტროლს ტრენინგის პროცესზე და, ამრიგად, ის ფართოდ გამოიყენება კვლევებში, როდესაც საქმე გაქვთ ნერვული ქსელის ახალ არქიტექტურასთან.
ასევე მნიშვნელოვანია გვესმოდეს, რომ თქვენ შეგიძლიათ გამოიყენოთ ორივე API ერთად, მაგ. თქვენ შეგიძლიათ განავითაროთ თქვენი საკუთარი ქსელის ფენის არქიტექტურა დაბალი დონის API-ს გამოყენებით და შემდეგ გამოიყენოთ იგი უფრო დიდი ქსელის შიგნით, რომელიც აშენებულია და გაწვრთნილი მაღალი დონის API-ით. ან შეგიძლიათ განსაზღვროთ ქსელი მაღალი დონის API-ის გამოყენებით, როგორც შრეების თანმიმდევრობა, და შემდეგ გამოიყენოთ თქვენი საკუთარი დაბალი დონის სასწავლო ციკლი ოპტიმიზაციის შესასრულებლად. ორივე API იყენებს ერთსა და იმავე ძირითად ცნებებს და ისინი შექმნილია იმისთვის, რომ კარგად იმუშაონ ერთად.
სწავლა
ამ კურსში, ჩვენ ვთავაზობთ შინაარსის უმეტესობას PyTorch-ისთვის და TensorFlow-ისთვის. თქვენ შეგიძლიათ აირჩიოთ თქვენთვის სასურველი ჩარჩო და გაიაროთ მხოლოდ შესაბამისი ნოუთბუქები. თუ არ ხართ დარწმუნებული, რომელი ჩარჩო აირჩიოთ, წაიკითხეთ რამდენიმე დისკუსია ინტერნეტში PyTorch vs. TensorFlow. თქვენ ასევე შეგიძლიათ გადახედოთ ორივე ჩარჩოს, რომ უკეთ გაიგოთ.
სადაც შესაძლებელია, ჩვენ გამოვიყენებთ მაღალი დონის API-ებს სიმარტივისთვის. თუმცა, ჩვენ გვჯერა, რომ მნიშვნელოვანია გვესმოდეს, თუ როგორ მუშაობს ნერვული ქსელები თავიდანვე, ამიტომ დასაწყისში ვიწყებთ დაბალი დონის API-სთან და ტენსორებთან მუშაობას. თუმცა, თუ გსურთ სწრაფად დაიწყოთ მუშაობა და არ გსურთ ამ დეტალების შესწავლაზე დიდი დროის დახარჯვა, შეგიძლიათ გამოტოვოთ ისინი და პირდაპირ გადახვიდეთ მაღალი დონის API ნოუთბუქებში.
სავარჯიშოები: ჩარჩოები
განაგრძეთ სწავლა შემდეგ რვეულებში:
დაბალი დონის API | TensorFlow+Keras Notebook | PyTorch
მაღალი დონის API| კერასი | PyTorch Lightning
ჩარჩოების დაუფლების შემდეგ, გავიმეოროთ ზედმეტად მორგების ცნება.
ზედმეტად მორგება
Overfitting არის ძალიან მნიშვნელოვანი კონცეფცია მანქანათმცოდნეობაში და ძალიან მნიშვნელოვანია მისი სწორად მიღება!
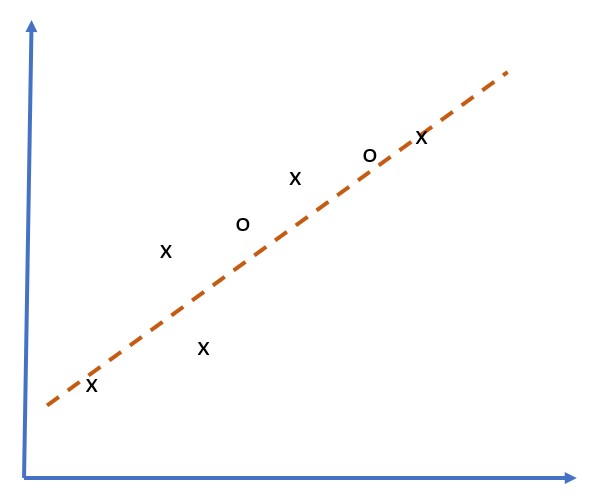
განვიხილოთ 5 წერტილის მიახლოების შემდეგი ამოცანა (გამოსახულია x ქვემოთ გრაფიკებზე):
 |
| 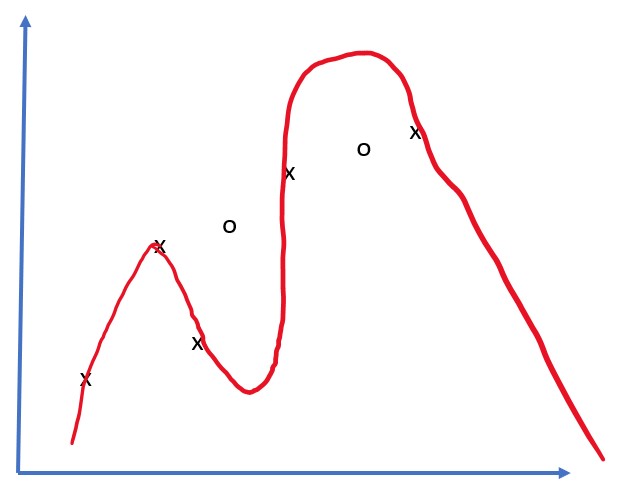
ხაზოვანი მოდელი, 2 პარამეტრი | არაწრფივი მოდელი, 7 პარამეტრი ვარჯიშის შეცდომა = 5.3 | ვარჯიშის შეცდომა = 0 ვალიდაციის შეცდომა = 5.1 | ვალიდაციის შეცდომა = 20
- მარცხნივ, ჩვენ ვხედავთ კარგი სწორი ხაზის მიახლოებას. იმის გამო, რომ პარამეტრების რაოდენობა ადეკვატურია, მოდელი ზუსტად იღებს იდეას წერტილების განაწილების უკან.
- მარჯვნივ, მოდელი ძალიან ძლიერია. იმის გამო, რომ ჩვენ გვაქვს მხოლოდ 5 ქულა და მოდელს აქვს 7 პარამეტრი, მას შეუძლია დაარეგულიროს ისე, რომ გაიაროს ყველა წერტილი, რის შედეგადაც ტრენინგის შეცდომა იქნება 0. თუმცა, ეს ხელს უშლის მოდელს გააცნობიეროს მონაცემების მიღმა სწორი ნიმუში, შესაბამისად, ვალიდაციის შეცდომა ძალიან მაღალია.
ძალიან მნიშვნელოვანია სწორი ბალანსი მოდელის სიმდიდრეს (პარამეტრების რაოდენობა) და სასწავლო ნიმუშების რაოდენობას შორის.
რატომ ხდება ზედმეტი მორგება
- არ არის საკმარისი ტრენინგის მონაცემები
- ძალიან ძლიერი მოდელი
- ძალიან ბევრი ხმაური შეყვანის მონაცემებში
როგორ ამოვიცნოთ ზედმეტი მორგება
როგორც ზემოთ მოყვანილი გრაფიკიდან ხედავთ, ზედმეტი მორგება შეიძლება გამოვლინდეს ვარჯიშის ძალიან დაბალი შეცდომით და მაღალი ვალიდაციის შეცდომით. ჩვეულებრივ ტრენინგის დროს ჩვენ დავინახავთ როგორც ვარჯიშის, ასევე ვალიდაციის შეცდომებს, რომლებიც დაიწყებენ კლებას, შემდეგ კი რაღაც მომენტში ვალიდაციის შეცდომა შეიძლება შეწყვიტოს კლება და დაიწყოს ზრდა. ეს იქნება ზედმეტად მორგების ნიშანი და იმის მაჩვენებელი, რომ ალბათ ამ ეტაპზე უნდა შევწყვიტოთ ვარჯიში (ან თუნდაც მოდელის სნეფშოტი გავაკეთოთ).
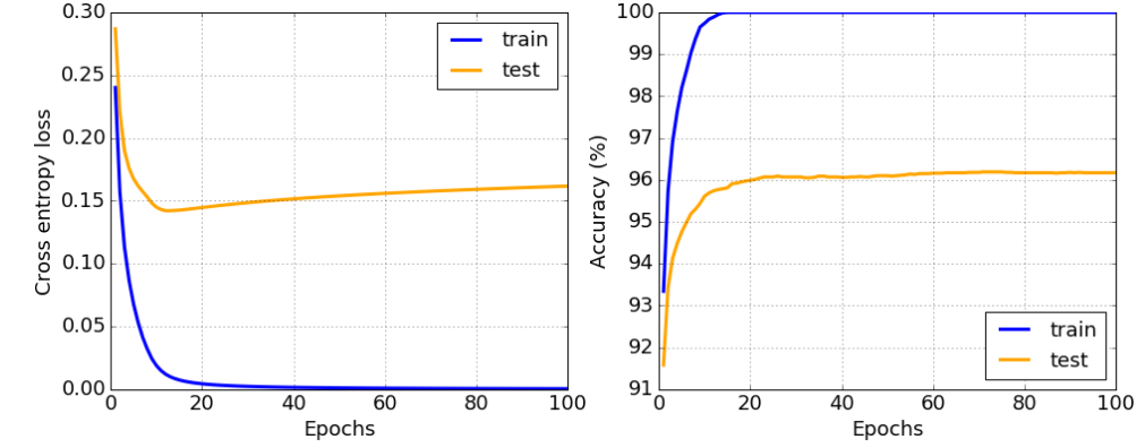
როგორ ავიცილოთ თავიდან მორგება
თუ ხედავთ, რომ ზედმეტი მორგება ხდება, შეგიძლიათ გააკეთოთ შემდეგი:
- გაზარდეთ ტრენინგის მონაცემები
- მოდელის სირთულის შემცირება
- გამოიყენეთ ზოგიერთი რეგულაციის ტექნიკა, როგორიცაა მიტოვება, რომელსაც მოგვიანებით განვიხილავთ.
Overfitting და Bias-Variance Tradeoff
ზედმეტად მორგება რეალურად უფრო ზოგადი პრობლემის შემთხვევაა სტატისტიკაში, სახელწოდებით მიკერძოება-ვარიანტული ვაჭრობა. თუ გავითვალისწინებთ შეცდომის შესაძლო წყაროებს ჩვენს მოდელში, ჩვენ შეგვიძლია დავინახოთ შეცდომების ორი ტიპი:
- მიკერძოებული შეცდომები გამოწვეულია იმით, რომ ჩვენი ალგორითმი ვერ ახერხებს სასწავლო მონაცემებს შორის ურთიერთობის სწორად აღქმას. ეს შეიძლება გამოწვეული იყოს იმით, რომ ჩვენი მოდელი არ არის საკმარისად ძლიერი (underfitting).
- ვარიანტული შეცდომები, რომლებიც გამოწვეულია მოდელის მიახლოებითი ხმაურით შეყვანის მონაცემებში მნიშვნელოვანი ურთიერთობის ნაცვლად (გადაჭარბებული მორგება).
ტრენინგის დროს, მიკერძოების შეცდომა მცირდება (როგორც ჩვენი მოდელი სწავლობს მონაცემების მიახლოებას) და დისპერსიული შეცდომა იზრდება. მნიშვნელოვანია შეწყვიტოთ ვარჯიში - ხელით (როდესაც ჩვენ აღმოვაჩენთ ზედმეტ მორგებას) ან ავტომატურად (რეგულარიზაციის შემოღებით) - ზედმეტი მორგების თავიდან ასაცილებლად.
დასკვნა
ამ გაკვეთილზე თქვენ შეიტყვეთ განსხვავებების შესახებ სხვადასხვა API-ებს შორის ორი ყველაზე პოპულარული AI ჩარჩოსთვის, TensorFlow და PyTorch. გარდა ამისა, თქვენ შეიტყვეთ ძალიან მნიშვნელოვანი თემის, ზედმეტად მორგების შესახებ.
გამოწვევა
თანდართულ რვეულებში ბოლოში ნახავთ „დავალებებს“; იმუშავეთ ნოუთბუქებით და შეასრულეთ დავალებები.
ლექციის შემდგომი ვიქტორინა
მიმოხილვა და თვითშესწავლა
ჩაატარეთ კვლევა შემდეგ თემებზე:
- TensorFlow
- PyTorch
- ზედმეტად მორგება
დაუსვით საკუთარ თავს შემდეგი კითხვები:
- რა განსხვავებაა TensorFlow-სა და PyTorch-ს შორის?
- რა განსხვავებაა ოვერფიტინგსა და უვარგისობას შორის?