საკუთარი ნერვული ჩარჩოს აგება
ეს ნოუთბუქი AI დამწყებთათვის სასწავლო გეგმები-ის ნაწილია. ეწვიეთ საცავს სასწავლო მასალების სრული ნაკრებისთვის.
ამ ნოუთბუქში ჩვენ თანდათან ავაშენებთ საკუთარ ნერვულ ჩარჩოს, რომელსაც შეუძლია გადაჭრას მრავალკლასიანი კლასიფიკაციის ამოცანები, ასევე რეგრესია მრავალშრიანი პრეცეპტრონებით.
პირველი, მოდით შემოვიტანოთ რამდენიმე საჭირო ბიბლიოთეკა.
იტვირთება…მონაცემთა ნაკრების ნიმუში
როგორც ადრე, ჩვენ დავიწყებთ მარტივი ნიმუშის ნაკრებით ორი პარამეტრით.
იტვირთება…იტვირთება…იტვირთება…გამოტანა
<IPython.core.display.Javascript object><IPython.core.display.HTML object>იტვირთება…გამოტანა
[[ 1.3382818 -0.98613256]
[ 0.5128146 0.43299454]
[-0.4473693 -0.2680512 ]
[-0.9865851 -0.28692 ]
[-1.0693829 0.41718036]]
[1 1 0 0 0]
მანქანათმცოდნეობის პრობლემა
დავუშვათ, ჩვენ გვაქვს შეყვანილი მონაცემთა ნაკრები $\langle X,Y\rangle$, სადაც $X$ არის ფუნქციების ნაკრები და $Y$ - შესაბამისი ლეიბლები. რეგრესიის პრობლემისთვის $y_i\in\mathbb{R}$, ხოლო კლასიფიკაციისთვის იგი წარმოდგენილია კლასის ნომრით $y_i\in{0,\dots,n}$.
მანქანათმცოდნეობის ნებისმიერი მოდელი შეიძლება წარმოდგენილი იყოს $f_\theta(x)$ ფუნქციით, სადაც $\theta$ არის პარამეტრების ნაკრები. ჩვენი მიზანია ვიპოვოთ ისეთი პარამეტრები $\theta$, რომ ჩვენი მოდელი საუკეთესოდ მოერგოს მონაცემთა ბაზას. კრიტერიუმი განისაზღვრება დაკარგვის ფუნქციით $\mathcal{L}$ და ჩვენ უნდა ვიპოვოთ ოპტიმალური მნიშვნელობა
$$ \theta = \mathrm{argmin}\theta \mathcal{L}(f\theta(X),Y) $$
დაკარგვის ფუნქცია დამოკიდებულია მოგვარებულ პრობლემაზე.
დაკარგვის ფუნქციები რეგრესიისთვის
რეგრესიისთვის ჩვენ ხშირად ვიყენებთ აბსოლუტურ შეცდომას $\mathcal{L}{abs}(\theta) = \sum{i=1}^n |y_i - f_{\theta}(x_i)|$, ან საშუალო კვადრატულ შეცდომას: $\mathcal{L}{sq}(\theta) = ^} f_{\theta}(x_i))^2$
იტვირთება…იტვირთება…გამოტანა
<IPython.core.display.Javascript object><IPython.core.display.HTML object>დაკარგვის ფუნქციები კლასიფიკაციისთვის
მოდით განვიხილოთ ბინარული კლასიფიკაცია ერთი წუთით. ამ შემთხვევაში გვაქვს ორი კლასი, დანომრილი 0 და 1. ქსელის გამომავალი $f_\theta(x_i)\in [0,1]$ არსებითად განსაზღვრავს 1 კლასის არჩევის ალბათობას.
0-1 წაგება
0-1 ზარალი იგივეა, რაც მოდელის სიზუსტის გამოთვლა - ჩვენ ვიანგარიშებთ სწორი კლასიფიკაციის რაოდენობას:
$$\mathcal{L}{0-1} = \sum{i=1}^n l_i \quad l_i = \დაწყება{შემთხვევები} 0 & (f(x_i)<0.5 \მიწა y_i=0) \lor (f(x_i)<0.5 \მიწა y_i=1) \ 1 & \mathrm{ სხვაგვარად} \დასასრული{შემთხვევები} \ $$
თუმცა, სიზუსტე თავისთავად არ აჩვენებს, რამდენად შორს ვართ სწორი კლასიფიკაციისგან. შესაძლოა, ჩვენ ცოტათი გამოვტოვეთ სწორი კლასი და ეს გარკვეულწილად "უკეთესი" (იმ გაგებით, რომ ჩვენ გვჭირდება წონების გამოსწორება ბევრად ნაკლები), ვიდრე მნიშვნელოვნად გამოტოვებული. ამრიგად, უფრო ხშირად გამოიყენება ლოგისტიკური დანაკარგი, რაც ამას ითვალისწინებს.
ლოგისტიკური დანაკარგი
$$\mathcal{L}{log} = \sum{i=1}^n -y\log(f_{\theta}(x_i)) - (1-y)\log(1-f_\theta(x_i))$$
იტვირთება…იტვირთება…გამოტანა
C:\Users\dmitryso\AppData\Local\Temp/ipykernel_55820/331859503.py:10: RuntimeWarning: divide by zero encountered in log
return -np.log(fx)
<IPython.core.display.Javascript object><IPython.core.display.HTML object>ლოჯისტიკური დანაკარგის გასაგებად, განიხილეთ მოსალოდნელი გამომავალი ორი შემთხვევა:
- თუ ჩვენ ველოდებით, რომ გამომავალი იქნება 1 ($y=1$), მაშინ დანაკარგი არის $-log f_\theta(x_i)$. დანაკარგი არის 0, რაც ქსელი პროგნოზირებს 1-ს 1-ის ალბათობით და იზრდება მაშინ, როდესაც 1-ის ალბათობა მცირდება.
- თუ ჩვენ ველოდებით, რომ გამომავალი იქნება 0 ($y=0$), დანაკარგი არის $-log(1-f_\theta(x_i))$. აქ, $1-f_\theta(x_i)$ არის 0-ის ალბათობა, რომელიც პროგნოზირებულია ქსელის მიერ და ჟურნალის დაკარგვის მნიშვნელობა იგივეა, რაც აღწერილია წინა შემთხვევაში.
ნერვული ქსელის არქიტექტურა
ჩვენ შევქმენით მონაცემთა ბაზა ბინარული კლასიფიკაციის პრობლემისთვის. თუმცა, მოდი თავიდანვე მივიჩნიოთ მრავალკლასიან კლასიფიკაციად, რათა შემდეგ ადვილად გადავიტანოთ ჩვენი კოდი მრავალკლასიან კლასიფიკაციაზე. ამ შემთხვევაში, ჩვენს ერთ ფენიან პერცეპტრონს ექნება შემდეგი არქიტექტურა:
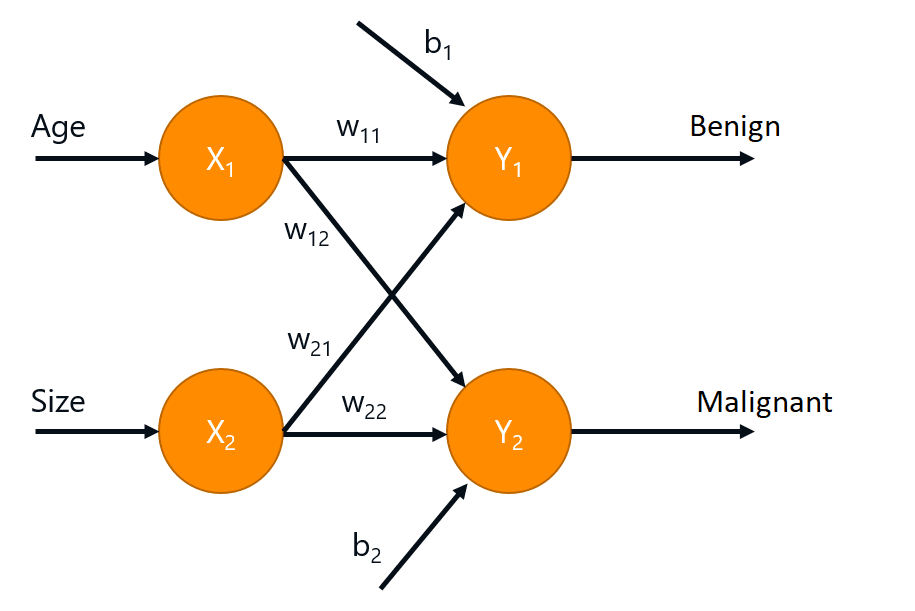
ქსელის ორი გამომავალი შეესაბამება ორ კლასს, ხოლო კლასი, რომელსაც აქვს უმაღლესი მნიშვნელობა ორ გამოსავალს შორის, შეესაბამება სწორ გადაწყვეტას.
მოდელი განისაზღვრება როგორც $$ f_\theta(x) = W\ჯერ x + b $$ სადაც $$\theta = \langle W,b\rangle$$ არის პარამეტრები.
ჩვენ განვსაზღვრავთ ამ ხაზოვან ფენას, როგორც პითონის კლასს forward ფუნქციით, რომელიც ასრულებს გამოთვლას. ის იღებს შეყვანის მნიშვნელობას $x$ და აწარმოებს ფენის გამომავალს. პარამეტრები W და b ინახება ფენის კლასში და ინიციალიზებულია შექმნისას შემთხვევითი მნიშვნელობებით და ნულებით შესაბამისად.
იტვირთება…გამოტანა
array([[ 1.77202116, -0.25384488],
[ 0.28370828, -0.39610552],
[-0.30097433, 0.30513182],
[-0.8120485 , 0.56079421],
[-1.23519653, 0.3394973 ]])ხშირ შემთხვევაში, უფრო ეფექტურია მუშაობა არა ერთ შეყვანის მნიშვნელობაზე, არამედ შეყვანის მნიშვნელობების ვექტორზე. იმის გამო, რომ ჩვენ ვიყენებთ Numpy ოპერაციებს, შეგვიძლია გადავიტანოთ შეყვანის მნიშვნელობების ვექტორი ჩვენს ქსელში და ის მოგვცემს გამომავალი მნიშვნელობების ვექტორს.
Softmax: შედეგების გადაქცევა ალბათობებად
როგორც ხედავთ, ჩვენი შედეგები არ არის ალბათობა - მათ შეუძლიათ მიიღონ ნებისმიერი მნიშვნელობა. იმისათვის, რომ გადავიტანოთ ისინი ალბათებად, ჩვენ გვჭირდება მნიშვნელობების ნორმალიზება ყველა კლასში. ეს კეთდება softmax ფუნქციის გამოყენებით: $$\sigma(\mathbf{z}c) = \frac{e^{z_c}}{\sum{j} e^{z_j}}, \quad\mathrm{for}\quad c\in 1 .. |C|$$
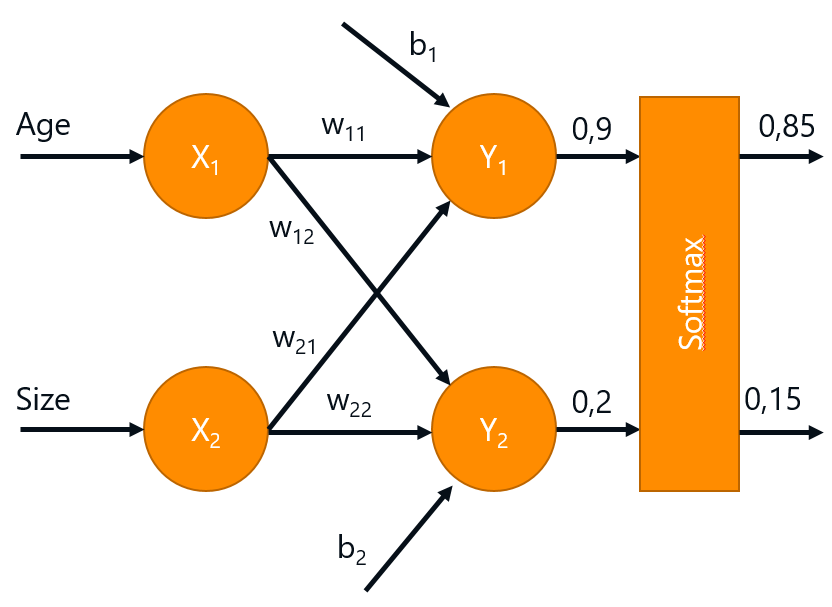
ქსელის გამომავალი $\sigma(\mathbf{z})$ შეიძლება განიმარტოს, როგორც ალბათობის განაწილება $C$ კლასების სიმრავლეზე: $q = \sigma(\mathbf{z}_c) = \hat{p}(c | x)$
ჩვენ განვსაზღვრავთ Softmax ფენას იმავე წესით, როგორც კლასი forward ფუნქციით:
იტვირთება…გამოტანა
array([[0.88348621, 0.11651379],
[0.66369714, 0.33630286],
[0.35294795, 0.64705205],
[0.20216095, 0.79783905],
[0.17154828, 0.82845172],
[0.24279153, 0.75720847],
[0.18915732, 0.81084268],
[0.17282951, 0.82717049],
[0.13897531, 0.86102469],
[0.72746882, 0.27253118]])თქვენ ხედავთ, რომ ჩვენ ახლა ვიღებთ ალბათობას, როგორც გამოსავალს, ანუ თითოეული გამომავალი ვექტორის ჯამი არის ზუსტად 1.
თუ 2 კლასზე მეტი გვაქვს, softmax ნორმალიზებს ალბათობას ყველა მათგანში. აქ არის ქსელის არქიტექტურის დიაგრამა, რომელიც ასრულებს MNIST ციფრული კლასიფიკაციას:
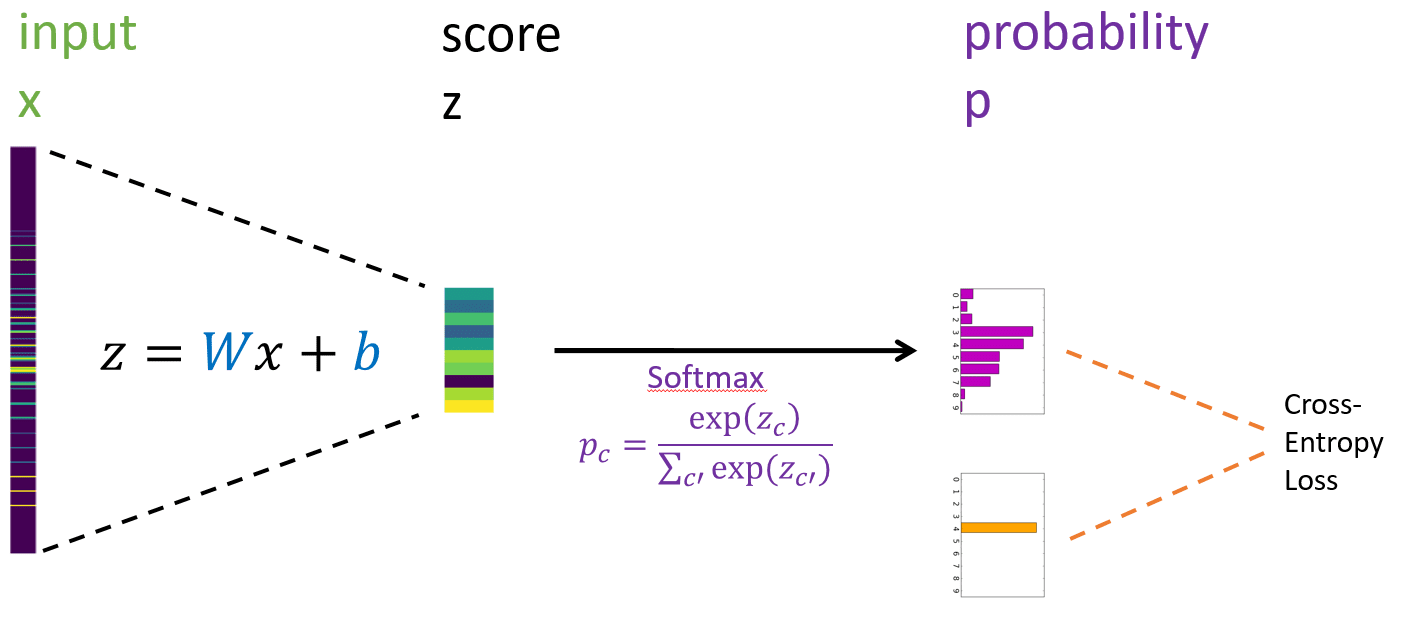
ჯვარედინი ენტროპიის დაკარგვა
დანაკარგის ფუნქცია კლასიფიკაციაში, როგორც წესი, არის ლოგისტიკური ფუნქცია, რომელიც შეიძლება განზოგადდეს როგორც ჯვარედინი ენტროპიის დანაკარგი. ჯვარედინი ენტროპიის დაკარგვა არის ფუნქცია, რომელსაც შეუძლია გამოთვალოს მსგავსება ორ თვითნებურ განაწილებას შორის. თქვენ შეგიძლიათ იპოვოთ უფრო დეტალური განხილვა ამის შესახებ ვიკიპედიაზე.
ჩვენს შემთხვევაში, პირველი განაწილება არის ჩვენი ქსელის სავარაუდო გამომავალი, ხოლო მეორე არის ეგრეთ წოდებული one-hot განაწილება, რომელიც განსაზღვრავს, რომ მოცემულ $c$ კლასს აქვს შესაბამისი ალბათობა 1 (ყველა დანარჩენი არის 0). ასეთ შემთხვევაში ჯვარედინი ენტროპიის დანაკარგი შეიძლება გამოითვალოს $-\log p_c$, სადაც $c$ არის მოსალოდნელი კლასი და $p_c$ არის ამ კლასის შესაბამისი ალბათობა, რომელიც მოცემულია ჩვენი ნერვული ქსელის მიერ.
თუ ქსელის დაბრუნების ალბათობა 1 მოსალოდნელი კლასისთვის, ჯვარედინი ენტროპიის დანაკარგი იქნება 0. რაც უფრო უახლოვდება რეალური კლასის ალბათობა 0-ს, მით მეტია ჯვარედინი ენტროპიის დანაკარგი (და ის შეიძლება აწიოს უსასრულობამდე!).
იტვირთება…იტვირთება…გამოტანა
<IPython.core.display.Javascript object><IPython.core.display.HTML object>ჯვარედინი ენტროპიის დაკარგვა კვლავ განისაზღვროს, როგორც ცალკე ფენა, მაგრამ forward ფუნქციას ექნება ორი შეყვანის მნიშვნელობა: ქსელის წინა ფენების გამომავალი p და მოსალოდნელი კლასი y:
იტვირთება…გამოტანა
1.429664938969559მნიშვნელოვანი: Loss ფუნქცია აბრუნებს რიცხვს, რომელიც აჩვენებს რამდენად კარგი (ან ცუდი) მუშაობს ჩვენი ქსელი. მან უნდა დაგვიბრუნოს ერთი რიცხვი მთელი მონაცემთა ნაკრებისთვის, ან მონაცემთა ნაკრების ნაწილისთვის (მინი პარტია). ამრიგად, ჯვარედინი ენტროპიის დანაკარგის გამოთვლის შემდეგ შეყვანის ვექტორის თითოეული ცალკეული კომპონენტისთვის, ჩვენ უნდა შევაფასოთ (ან დავამატოთ) ყველა კომპონენტი ერთად - რაც ხდება
.mean()-ზე გამოძახებით.
გამოთვლითი გრაფიკი
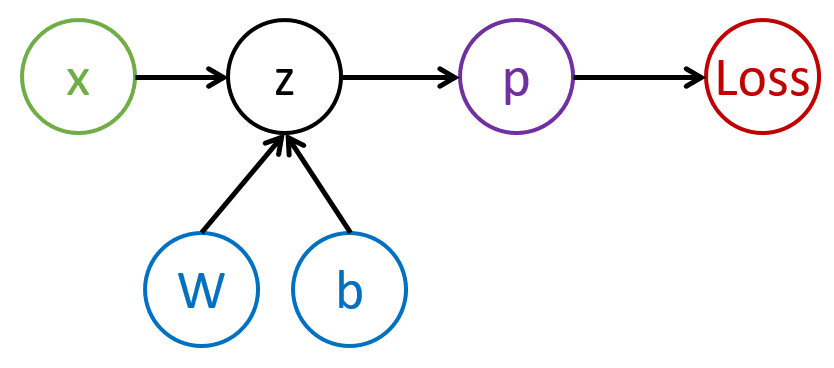
ამ მომენტამდე ჩვენ განვსაზღვრეთ სხვადასხვა კლასი ქსელის სხვადასხვა ფენისთვის. ამ ფენების შემადგენლობა შეიძლება წარმოდგენილი იყოს როგორც გამოთვლითი გრაფიკი. ახლა ჩვენ შეგვიძლია გამოვთვალოთ დანაკარგი მოცემული სასწავლო მონაცემთა ნაკრებისთვის (ან მისი ნაწილისთვის) შემდეგი გზით:
იტვირთება…გამოტანა
1.429664938969559
ზარალის მინიმიზაციის პრობლემა და ქსელის ტრენინგი
მას შემდეგ, რაც ჩვენ განვსაზღვრავთ ქსელს, როგორც $f_\theta$ და მივცემთ დაკარგვის ფუნქციას $\mathcal{L}(Y,f_\theta(X))$, ჩვენ შეგვიძლია განვიხილოთ $\mathcal{L}$, როგორც $\theta$-ის ფუნქცია ჩვენი ფიქსირებული სასწავლო მონაცემთა ნაკრების მიხედვით: $\mathcal{L}(\theta) = \mathcal{L}(Y,f)_
ამ შემთხვევაში, ქსელის ტრენინგი იქნება $\mathcal{L}$-ის მინიმიზაციის პრობლემა $\theta$ არგუმენტით: $$ \theta = \mathrm{argmin}{\theta} \mathcal{L}(Y,f\theta(X)) $$
არსებობს ფუნქციების ოპტიმიზაციის ცნობილი მეთოდი, რომელსაც ეწოდება გრადიენტული წარმოშობა. იდეა იმაში მდგომარეობს, რომ ჩვენ შეგვიძლია გამოვთვალოთ დაკარგვის ფუნქციის წარმოებული (მრავალგანზომილებიან შემთხვევაში მოვუწოდებთ გრადიენტს) პარამეტრებთან მიმართებაში და შევცვალოთ პარამეტრები ისე, რომ შეცდომა შემცირდეს.
გრადიენტური დაღმართი მუშაობს შემდეგნაირად:
- პარამეტრების ინიცირება რამდენიმე შემთხვევითი მნიშვნელობებით $w^{(0)}$, $b^{(0)}$
- რამდენჯერმე გაიმეორეთ შემდეგი ნაბიჯი:
$$\ დასაწყისი{გასწორება} W^{(i+1)}&=W^{(i)}-\eta\frac{\partial\mathcal{L}}{\partial W}\ b^{(i+1)}&=b^{(i)}-\eta\frac{\partial\mathcal{L}}{\partial b} \ბოლო{გასწორება} $$
ტრენინგის დროს, ოპტიმიზაციის საფეხურები უნდა გამოითვალოს მთელი მონაცემთა ნაკრების გათვალისწინებით (გახსოვდეთ, რომ დანაკარგი გამოითვლება როგორც ჯამი/საშუალო ყველა სასწავლო ნიმუშში). თუმცა, რეალურ ცხოვრებაში ჩვენ ვიღებთ მონაცემთა ნაკრების მცირე ნაწილს, რომელსაც ეწოდება მინი პარტიები და ვიანგარიშებთ გრადიენტებს მონაცემთა ქვეჯგუფის საფუძველზე. იმის გამო, რომ ქვესიმრავლე ყოველ ჯერზე შემთხვევით მიიღება, ასეთ მეთოდს ეწოდება სტოქასტური გრადიენტული დაღმართი (SGD).
უკან გამრავლება
$$\def\L{\mathcal{L}}\def\zz#1#2{\frac{\partial#1}{\partial#2}} \დაწყება{გასწორება} \zz{\L}{W} =& \zz{\L}{p}\zz{p}{z}\zz{z}{W}\cr \zz{\L}{b} =& \zz{\L}{p}\zz{p}{z}\zz{z}{b} \ბოლო{გასწორება} $$
$\partial\mathcal{L}/\partial W$-ის გამოსათვლელად ჩვენ შეგვიძლია გამოვიყენოთ ჯაჭვის წესი კომპოზიტური ფუნქციის წარმოებულების გამოსათვლელად, როგორც ხედავთ ზემოთ მოცემულ ფორმულებში. იგი შეესაბამება შემდეგ იდეას:
- დავუშვათ, მოცემული შეყვანისას გვაქვს $\Delta\mathcal{L}$-ის დანაკარგი
- მისი მინიმიზაციისთვის, ჩვენ უნდა დავარეგულიროთ softmax გამომავალი $p$ მნიშვნელობით $\Delta p = (\partial\mathcal{L}/\partial p)\Delta\mathcal{L}$
- ეს შეესაბამება $z$ კვანძის ცვლილებებს $\Delta z = (\partial\mathcal{p}/\partial z)\Delta p$-ით
- ამ შეცდომის შესამცირებლად, ჩვენ უნდა დავარეგულიროთ პარამეტრები: $\Delta W = (\partial\mathcal{z}/\partial W)\Delta z$ (და იგივე $b$-ისთვის)
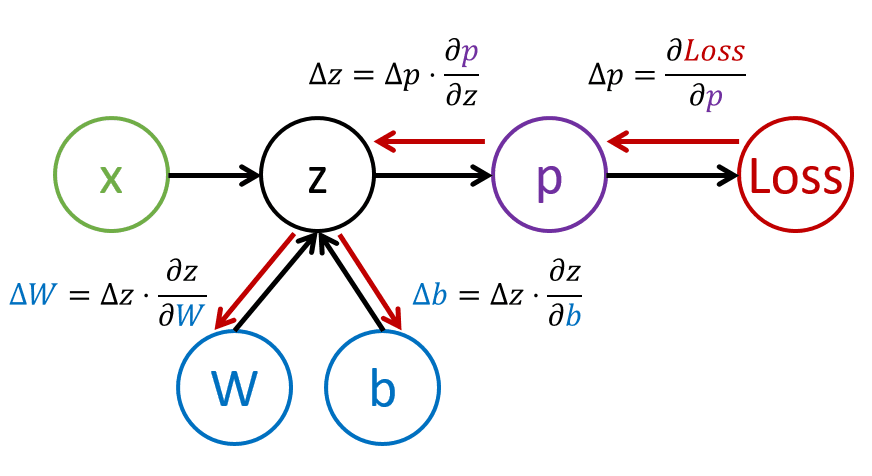
ეს პროცესი იწყებს ზარალის შეცდომის განაწილებას ქსელის გამოსვლიდან მის პარამეტრებზე. ამრიგად, პროცესს ეწოდება უკან გავრცელება.
ქსელის ტრენინგის ერთი გავლა ორი ნაწილისგან შედგება:
- Forward pass, როდესაც ვიანგარიშებთ დაკარგვის ფუნქციის მნიშვნელობას მოცემული შეყვანის მინი პარტიისთვის
- უკან გადასასვლელი, როდესაც ვცდილობთ ამ შეცდომის მინიმიზაციას გამოთვლითი გრაფიკის მეშვეობით მოდელის პარამეტრებზე მისი გადანაწილებით.
უკან გამრავლების განხორციელება
- მოდით დავამატოთ
backwardფუნქცია ჩვენს თითოეულ კვანძს, რომელიც გამოთვლის წარმოებულს და გაავრცელებს შეცდომას უკან გადასვლის დროს. - ჩვენ ასევე უნდა განვახორციელოთ პარამეტრების განახლებები ზემოთ აღწერილი პროცედურის მიხედვით
ჩვენ უნდა გამოვთვალოთ წარმოებულები თითოეული ფენისთვის ხელით, მაგალითად წრფივი ფენისთვის $z = x\ჯერ W+b$: $$\ დასაწყისი{გასწორება} \frac{\partial z}{\partial W} &= x \ \frac{\partial z}{\partial b} &= 1 \ \end{align}$$
თუ ჩვენ გვჭირდება შეცდომის ანაზღაურება $\Delta z$ ფენის გამოსავალზე, ჩვენ უნდა განვაახლოთ წონა შესაბამისად: $$\ დასაწყისი{გასწორება} \დელტა x &= \დელტა z \ჯერ W \ \Delta W &= \frac{\partial z}{\partial W} \Delta z = \Delta z \ჯერ x \ \Delta b &= \frac{\partial z}{\partial b} \Delta z = \დელტა z \ \end{align}$$
მნიშვნელოვანია: გამოთვლები კეთდება არა თითოეული სასწავლო ნიმუშისთვის დამოუკიდებლად, არამედ მთლიანი მინი პარტიისთვის. პარამეტრების საჭირო განახლებები $\Delta W$ და $\Delta b$ გამოითვლება მთელ მინი პარტიაში და შესაბამის ვექტორებს აქვთ ზომები: $x\in\mathbb{R}^{\mathrm{minibatch}, \times, \mathrm{ncclass}}$
იტვირთება…ანალოგიურად, ჩვენ შეგვიძლია განვსაზღვროთ backward ფუნქცია ჩვენი დანარჩენი ფენებისთვის:
იტვირთება…მოდელის ვარჯიში
ახლა ჩვენ მზად ვართ დავწეროთ სავარჯიშო მარყუჟი, რომელიც გაივლის ჩვენს მონაცემთა ბაზას და შევასრულოთ ოპტიმიზაციის მინი პარტია მინიჯგუფის მიხედვით. მონაცემთა ნაკრების ერთ სრულ გავლას ხშირად უწოდებენ ეპოქას:
იტვირთება…გამოტანა
Initial accuracy: 0.725
Final accuracy: 0.825
სასიამოვნოა იმის დანახვა, თუ როგორ შეგვიძლია გავზარდოთ მოდელის სიზუსტე დაახლოებით 50%-დან დაახლოებით 80%-მდე ერთ ეპოქაში.
ქსელის კლასი
ვინაიდან ხშირ შემთხვევაში ნერვული ქსელი მხოლოდ ფენების კომპოზიციაა, ჩვენ შეგვიძლია ავაშენოთ კლასი, რომელიც საშუალებას მოგვცემს დავაწყოთ ფენები ერთად და გავაკეთოთ მათში წინ და უკან გადასვლები ამ ლოგიკის მკაფიოდ დაპროგრამების გარეშე. ჩვენ ვინახავთ შრეების სიას Net კლასში და ვიყენებთ add() ფუნქციას ახალი ფენების დასამატებლად:
იტვირთება…ამ Net კლასით ჩვენი მოდელის განმარტება და ტრენინგი უფრო დახვეწილი ხდება:
იტვირთება…გამოტანა
Initial loss=0.6212072429381601, accuracy=0.6875:
Final loss=0.44369925927417986, accuracy=0.8:
Test loss=0.4767711377257787, accuracy=0.85:
სასწავლო პროცესის შედგენა
კარგი იქნებოდა ვიზუალურად თუ როგორ მიმდინარეობს ქსელის წვრთნა! ჩვენ განვსაზღვრავთ train_and_plot ფუნქციას ამისთვის. ქსელის მდგომარეობის ვიზუალიზაციისთვის ჩვენ გამოვიყენებთ დონის რუკას, ანუ გამოვხატავთ ქსელის გამომავალი სხვადასხვა მნიშვნელობებს სხვადასხვა ფერის გამოყენებით.
არ ინერვიულოთ, თუ არ გესმით ქვემოთ მოცემული შედგენის კოდი - უფრო მნიშვნელოვანია გაიგოთ ძირითადი ნერვული ქსელის კონცეფციები.
იტვირთება…იტვირთება…იტვირთება…იტვირთება…გამოტანა
<IPython.core.display.Javascript object><IPython.core.display.HTML object>ზემოთ მოცემული უჯრედის გაშვების შემდეგ თქვენ უნდა შეძლოთ ინტერაქტიულად ნახოთ, თუ როგორ იცვლება კლასებს შორის საზღვარი ვარჯიშის დროს. გაითვალისწინეთ, რომ ჩვენ ავირჩიეთ ძალიან მცირე სწავლის მაჩვენებელი, რათა დავინახოთ, როგორ ხდება პროცესი.
მრავალ ფენიანი მოდელები
ზემოთ მოყვანილი ქსელი აგებულია რამდენიმე ფენისგან, მაგრამ ჩვენ მაინც გვქონდა მხოლოდ ერთი Linear ფენა, რომელიც ასრულებს რეალურ კლასიფიკაციას. რა მოხდება, თუ გადავწყვეტთ რამდენიმე ასეთი ფენის დამატებას?
გასაკვირია, რომ ჩვენი კოდი იმუშავებს! თუმცა, ძალიან მნიშვნელოვანი ისაა, რომ ხაზოვან ფენებს შორის უნდა გვქონდეს არაწრფივი აქტივაციის ფუნქცია, როგორიცაა tanh. ასეთი არაწრფივობის გარეშე, რამდენიმე წრფივ ფენას ექნებოდა იგივე გამომსახველობითი ძალა, როგორც მხოლოდ ერთ ფენას - რადგან წრფივი ფუნქციების შემადგენლობა ასევე წრფივია!
იტვირთება…რამდენიმე ფენის დამატებას აზრი აქვს, რადგან ერთი ფენის ქსელისგან განსხვავებით, მრავალშრიანი მოდელი შეძლებს ზუსტად კლასიფიცირდეს კომპლექტები, რომლებიც არ არის წრფივად განცალკევებული. ანუ, მოდელი რამდენიმე ფენით იქნება reacher.
შეიძლება დადასტურდეს, რომ საკმარისი რაოდენობის ნეირონებით, ორ ფენიან მოდელს შეუძლია მონაცემთა წერტილების ნებისმიერი ამოზნექილი ნაკრების კლასიფიკაცია, ხოლო სამ ფენიან ქსელს შეუძლია პრაქტიკულად ნებისმიერი ნაკრების კლასიფიკაცია.
მათემატიკურად, მრავალშრიანი პერცეტრონი წარმოდგენილი იქნება უფრო რთული ფუნქციით $f_\theta$, რომელიც შეიძლება გამოითვალოს რამდენიმე ეტაპად:
- $z_1 = W_1\ჯერ x+b_1$
- $z_2 = W_2\ჯერ\ალფა(z_1)+b_2$
- $f = \sigma(z_2)$
აქ $\alpha$ არის არაწრფივი აქტივაციის ფუნქცია, $\sigma$ არის softmax ფუნქცია და $\theta=\langle W_1,b_1,W_2,b_2\rangle$ არის პარამეტრები.
გრადიენტული დაღმართის ალგორითმი იგივე დარჩება, მაგრამ უფრო რთული იქნება გრადიენტების გამოთვლა. იმის გათვალისწინებით, ჯაჭვის დიფერენციაციის წესი, ჩვენ შეგვიძლია გამოვთვალოთ წარმოებულები შემდეგნაირად:
$$\ დასაწყისი{გასწორება} \frac{\partial\mathcal{L}}{\partial W_2} &= \color{red}{\frac{\partial\mathcal{L}}{\partial\sigma}\frac{\partial\sigma}{\partial z_2}}\color{black}{\frac{\partial z_2}{\partial\_ \frac{\partial\mathcal{L}}{\partial W_1} &= \color{red}{\frac{\partial\mathcal{L}}{\partial\sigma}\frac{\partial\sigma}{\partial z_2}}\color{black}{\frac{\partial z_2}{\frac\partial\partial z_1}\frac{\partial z_1}{\partial W_1}} \ბოლო{გასწორება} $$
გაითვალისწინეთ, რომ ყველა ამ გამონათქვამის დასაწყისი ისევ იგივეა, და ამრიგად, ჩვენ შეგვიძლია გავაგრძელოთ უკან გავრცელება ერთი წრფივი ფენის მიღმა, რათა დაარეგულიროთ შემდგომი წონა გამოთვლით გრაფიკზე.
ახლა მოდით ექსპერიმენტი ორ ფენიანი ქსელით:
იტვირთება…იტვირთება…გამოტანა
<IPython.core.display.Javascript object><IPython.core.display.HTML object>რატომ არ გამოიყენოთ ყოველთვის მრავალ ფენიანი მოდელი?
ჩვენ ვნახეთ, რომ მრავალშრიანი მოდელი უფრო ძლიერი და გამომსახველობითია ვიდრე ერთშრიანი. შეიძლება გაინტერესებთ, რატომ არ ვიყენებთ ყოველთვის მრავალ ფენიან მოდელს. ამ კითხვაზე პასუხი გადაჭარბებულია.
ამ ტერმინს უფრო მოგვიანებით განვიხილავთ, მაგრამ იდეა შემდეგია: რაც უფრო ძლიერია მოდელი, მით უკეთესია სასწავლო მონაცემების მიახლოება და მეტი მონაცემი სჭირდება მას სათანადო განზოგადება ახალი მონაცემებისთვის, რომელიც აქამდე არ უნახავს.
ხაზოვანი მოდელი:
- ჩვენ სავარაუდოდ მივიღებთ ვარჯიშის მაღალ დანაკარგს - ეგრეთ წოდებულ underfitting, როდესაც მოდელს არ აქვს საკმარისი ძალა ყველა მონაცემის სწორად გამოყოფისთვის.
- ვალიდაციის დაკარგვა და ტრენინგის დაკარგვა მეტ-ნაკლებად იგივეა. მოდელი, სავარაუდოდ, კარგად განზოგადდება ტესტის მონაცემებისთვის.
კომპლექსური მრავალშრიანი მოდელი
- ვარჯიშის დაბალი დანაკარგი - მოდელს შეუძლია კარგად მოახდინოს ვარჯიშის მონაცემების მიახლოება, რადგან მას აქვს საკმარისი გამოხატვის ძალა.
- ვალიდაციის დაკარგვა შეიძლება ბევრად აღემატებოდეს ვარჯიშის დაკარგვას და შეიძლება გაიზარდოს ვარჯიშის დროს - ეს იმიტომ ხდება, რომ მოდელი "იმახსოვრებს" სავარჯიშო ქულებს და კარგავს "ზოგად სურათს".
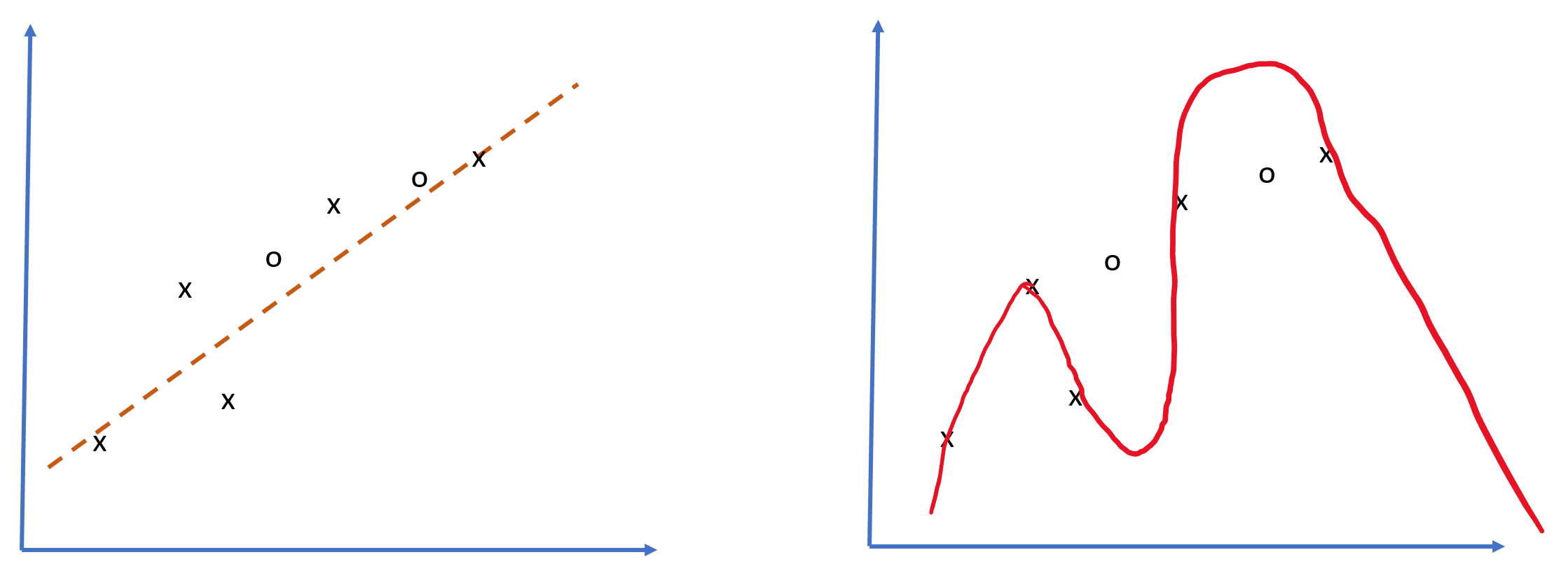
ამ სურათზე
xნიშნავს ტრენინგის მონაცემებს,o- ვალიდაციის მონაცემებს. მარცხნივ - ხაზოვანი მოდელი (ერთ ფენა), ის საკმაოდ კარგად აახლოებს მონაცემთა ბუნებას. მარჯვენა - გადაჭარბებული მოდელი, მოდელი მშვენივრად უახლოვდება ტრენინგის მონაცემებს, მაგრამ წყვეტს აზრს სხვა მონაცემებთან (ვალიდაციის შეცდომა ძალიან მაღალია)
Takeaways
- მარტივი მოდელები (ნაკლები ფენა, ნაკლები ნეირონები) დაბალი რაოდენობის პარამეტრებით („დაბალი სიმძლავრე“) ნაკლებად სავარაუდოა, რომ გადაჭარბებული იყოს
- უფრო რთული მოდელები (მეტი ფენა, მეტი ნეირონი თითოეულ შრეზე, მაღალი სიმძლავრე) სავარაუდოდ გადაჭარბებული იქნება. ჩვენ უნდა დავაკვირდეთ ვალიდაციის შეცდომას, რათა დავრწმუნდეთ, რომ ის არ იზრდება შემდგომი ტრენინგის დროს
- უფრო რთულ მოდელებს მეტი მონაცემები სჭირდებათ ვარჯიშისთვის.
- ზედმეტი მორგების პრობლემის გადაჭრა შეგიძლიათ შემდეგი გზით:
- თქვენი მოდელის გამარტივება
- ტრენინგის მონაცემების რაოდენობის გაზრდა
- მიკერძოება-ვარიანტობის გაცვლა არის ტერმინი, რომელიც გვიჩვენებს, რომ თქვენ უნდა მიიღოთ კომპრომისი
- მოდელის სიმძლავრესა და მონაცემთა რაოდენობას შორის,
- ზედმეტ მორგებასა და დაქვეითებას შორის
- არ არსებობს ერთი რეცეპტი, თუ რამდენი ფენის პარამეტრი გჭირდებათ - საუკეთესო გზაა ექსპერიმენტი
კრედიტები
ეს ნოუთბუქი არის AI დამწყებთათვის სასწავლო გეგმები-ის ნაწილი და მომზადებულია დიმიტრი სოშნიკოვი-ის მიერ. ის შთაგონებულია ნეირონული ქსელის სემინარიდან Microsoft Research Cambridge-ში. ზოგიერთი კოდი და საილუსტრაციო მასალა აღებულია კატია ჰოფმანი, მეთიუ ჯონსონი და რიოტო ტომიოკა პრეზენტაციებიდან და ნეიროვორკშოპი საცავიდან.