ამ მოდულში ჩვენ დავიწყებთ მარტივი ტექსტის კლასიფიკაციის ამოცანას AG_NEWS მონაცემთა ნაკრების საფუძველზე: ჩვენ დავყოფთ ახალი ამბების სათაურებს 4 კატეგორიად: მსოფლიო, სპორტი, ბიზნესი და მეცნიერება/ტექნიკა.
The Dataset
მონაცემთა ნაკრების ჩასატვირთად, ჩვენ გამოვიყენებთ TensorFlow მონაცემთა ნაკრები API-ს.
იტვირთება…ახლა ჩვენ შეგვიძლია წვდომა მონაცემთა ნაკრების სასწავლო და სატესტო ნაწილებზე შესაბამისად dataset['train'] და dataset['test'] გამოყენებით:
იტვირთება…გამოტანა
Length of train dataset = 120000
Length of test dataset = 7600
მოდით ამობეჭდოთ პირველი 10 ახალი სათაური ჩვენი მონაცემთა ბაზიდან:
იტვირთება…გამოტანა
3 (Sci/Tech) -> b'AMD Debuts Dual-Core Opteron Processor' b'AMD #39;s new dual-core Opteron chip is designed mainly for corporate computing applications, including databases, Web services, and financial transactions.'
1 (Sports) -> b"Wood's Suspension Upheld (Reuters)" b'Reuters - Major League Baseball\\Monday announced a decision on the appeal filed by Chicago Cubs\\pitcher Kerry Wood regarding a suspension stemming from an\\incident earlier this season.'
2 (Business) -> b'Bush reform may have blue states seeing red' b'President Bush #39;s quot;revenue-neutral quot; tax reform needs losers to balance its winners, and people claiming the federal deduction for state and local taxes may be in administration planners #39; sights, news reports say.'
3 (Sci/Tech) -> b"'Halt science decline in schools'" b'Britain will run out of leading scientists unless science education is improved, says Professor Colin Pillinger.'
1 (Sports) -> b'Gerrard leaves practice' b'London, England (Sports Network) - England midfielder Steven Gerrard injured his groin late in Thursday #39;s training session, but is hopeful he will be ready for Saturday #39;s World Cup qualifier against Austria.'
ტექსტის ვექტორიზაცია
ახლა ჩვენ უნდა გადავიყვანოთ ტექსტი რიცხვებად, რომლებიც შეიძლება იყოს წარმოდგენილი როგორც ტენსორები. თუ გვინდა სიტყვების დონეზე წარმოდგენა, ჩვენ უნდა გავაკეთოთ ორი რამ:
- გამოიყენეთ ტოკენიზატორი ტექსტის ტოკენებად გასაყოფად.
- შექმენით ამ ნიშნების ლექსიკა.
ლექსიკის ზომის შეზღუდვა
AG News მონაცემთა ნაკრების მაგალითში, ლექსიკის ზომა საკმაოდ დიდია, 100 ათას სიტყვაზე მეტი. ზოგადად, ჩვენ არ გვჭირდება სიტყვები, რომლებიც იშვიათად გვხვდება ტექსტში — მხოლოდ რამდენიმე წინადადება ექნება მათ და მოდელი მათგან ვერ ისწავლის. ამრიგად, აზრი აქვს ლექსიკის ზომის შეზღუდვას უფრო მცირე რიცხვით, არგუმენტის გადაცემით ვექტორიზატორის კონსტრუქტორზე:
ორივე ამ ნაბიჯის დამუშავება შესაძლებელია TextVectorization ფენის გამოყენებით. მოდით შევქმნათ ვექტორიზატორის ობიექტი და შემდეგ გამოვიძახოთ adapt მეთოდი, რომ გადავხედოთ მთელ ტექსტს და შევქმნათ ლექსიკა:
იტვირთება…შენიშვნა, რომ ჩვენ ვიყენებთ მთელი მონაცემთა ნაკრების მხოლოდ ქვეჯგუფს ლექსიკის შესაქმნელად. ჩვენ ამას ვაკეთებთ იმისთვის, რომ დავაჩქაროთ შესრულების დრო და არ დაგელოდოთ. თუმცა, ჩვენ ვიღებთ რისკს, რომ მთელი თარიღის ზოგიერთი სიტყვა არ მოხვდება ლექსიკაში და იგნორირებული იქნება ტრენინგის დროს. ამდენად, მთელი ლექსიკის ზომის გამოყენება და მთელი მონაცემთა ნაკრების გაშვება
adapt-ის განმავლობაში უნდა გაზარდოს საბოლოო სიზუსტე, მაგრამ არა მნიშვნელოვნად.
ახლა ჩვენ შეგვიძლია მივიღოთ ფაქტობრივი ლექსიკა:
იტვირთება…გამოტანა
['', '[UNK]', 'the', 'to', 'a', 'in', 'of', 'and', 'on', 'for']
Length of vocabulary: 5335
ვექტორიზატორის გამოყენებით, ჩვენ შეგვიძლია მარტივად დავაშიფროთ ნებისმიერი ტექსტი რიცხვების ნაკრებში:
იტვირთება…გამოტანა
<tf.Tensor: shape=(7,), dtype=int64, numpy=array([ 112, 3695, 3, 304, 11, 1041, 1], dtype=int64)>სიტყვების ჩანთა ტექსტის წარმოდგენა
იმის გამო, რომ სიტყვები წარმოადგენს მნიშვნელობას, ზოგჯერ ჩვენ შეგვიძლია გავარკვიოთ ტექსტის ნაწილის მნიშვნელობა მხოლოდ ცალკეული სიტყვების დათვალიერებით, წინადადებაში მათი თანმიმდევრობის მიუხედავად. მაგალითად, ახალი ამბების კლასიფიკაციისას, სიტყვები, როგორიცაა ამინდი და თოვლი, სავარაუდოდ მიუთითებს * ამინდის პროგნოზს*, ხოლო სიტყვები, როგორიცაა * აქციები * და *დოლარი * ჩაითვლება ფინანსურ ამბებში.
სიტყვების ტომარა (BoW) ვექტორული წარმოდგენა ყველაზე მარტივია ტრადიციული ვექტორული წარმოდგენის გასაგებად. თითოეული სიტყვა უკავშირდება ვექტორულ ინდექსს და ვექტორული ელემენტი შეიცავს მოცემულ დოკუმენტში თითოეული სიტყვის გაჩენის რაოდენობას.
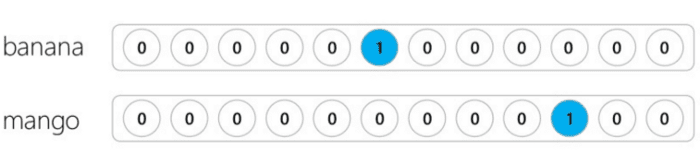
შენიშვნა: თქვენ ასევე შეგიძლიათ BoW წარმოიდგინოთ, როგორც ტექსტში ცალკეული სიტყვებისთვის one-hot კოდირებული ვექტორის ჯამი.
ქვემოთ მოცემულია მაგალითი იმისა, თუ როგორ უნდა გენერიროთ სიტყვების ჩანთა-გამოსახვა Scikit Learn პითონის ბიბლიოთეკის გამოყენებით:
იტვირთება…გამოტანა
array([[1, 1, 0, 2, 0, 0, 0, 0, 0]], dtype=int64)ჩვენ ასევე შეგვიძლია გამოვიყენოთ Keras-ის ვექტორიზატორი, რომელიც ზემოთ განვსაზღვრეთ, თითოეული სიტყვის რიცხვი გადავიყვანოთ one-hot კოდირებად და დავამატოთ ყველა ეს ვექტორი:
იტვირთება…გამოტანა
array([0., 5., 0., ..., 0., 0., 0.], dtype=float32)შენიშვნა: შეიძლება გაგიკვირდეთ, რომ შედეგი განსხვავდება წინა მაგალითისგან. მიზეზი ის არის, რომ Keras-ის მაგალითში ვექტორის სიგრძე შეესაბამება ლექსიკის ზომას, რომელიც აგებულია მთელი AG News-ის მონაცემთა ნაკრებიდან, ხოლო Scikit Learn მაგალითში ჩვენ ავაშენეთ ლექსიკა ნიმუშის ტექსტიდან.
BoW კლასიფიკატორის სწავლება
ახლა, როდესაც ვისწავლეთ, როგორ ავაშენოთ ჩვენი ტექსტის სიტყვების ჩანთა, მოდით მოვამზადოთ კლასიფიკატორი, რომელიც იყენებს მას. უპირველეს ყოვლისა, ჩვენ უნდა გადავიყვანოთ ჩვენი მონაცემთა ნაკრები სიტყვების ჩანთაში. ამის მიღწევა შესაძლებელია map ფუნქციის გამოყენებით შემდეგი გზით:
იტვირთება…ახლა მოდით განვსაზღვროთ მარტივი კლასიფიკატორის ნერვული ქსელი, რომელიც შეიცავს ერთ ხაზოვან ფენას. შეყვანის ზომაა vocab_size, ხოლო გამომავალი ზომა შეესაბამება კლასების რაოდენობას (4). იმის გამო, რომ ჩვენ ვხსნით კლასიფიკაციის ამოცანას, საბოლოო აქტივაციის ფუნქციაა softmax:
იტვირთება…გამოტანა
938/938 [==============================] - 66s 70ms/step - loss: 0.6144 - acc: 0.8427 - val_loss: 0.4416 - val_acc: 0.8697
<keras.callbacks.History at 0x20c70a947f0>ვინაიდან ჩვენ გვაქვს 4 კლასი, 80%-ზე მეტი სიზუსტე კარგი შედეგია.
კლასიფიკატორის ტრენინგი, როგორც ერთი ქსელი
იმის გამო, რომ ვექტორიზატორი ასევე არის Keras ფენა, ჩვენ შეგვიძლია განვსაზღვროთ ქსელი, რომელიც მოიცავს მას და ვავარჯიშოთ იგი ბოლომდე. ამ გზით ჩვენ არ გვჭირდება მონაცემთა ნაკრების ვექტორიზაცია map-ის გამოყენებით, ჩვენ შეგვიძლია უბრალოდ გადავიტანოთ თავდაპირველი მონაცემთა ნაკრები ქსელის შეყვანაში.
შენიშვნა: ჩვენ მაინც მოგვიწევს რუკების გამოყენება ჩვენს მონაცემთა ბაზაში, რათა გადაიყვანოთ ველები ლექსიკონებიდან (როგორიცაა
title,descriptionდაlabel) ტოპებად. თუმცა, დისკიდან მონაცემების ჩატვირთვისას, პირველ რიგში შეგვიძლია შევქმნათ მონაცემთა ბაზა საჭირო სტრუქტურით.
იტვირთება…გამოტანა
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 1)] 0
text_vectorization (TextVec (None, None) 0
torization)
tf.one_hot (TFOpLambda) (None, None, 5335) 0
tf.math.reduce_sum (TFOpLam (None, 5335) 0
bda)
dense_2 (Dense) (None, 4) 21344
=================================================================
Total params: 21,344
Trainable params: 21,344
Non-trainable params: 0
_________________________________________________________________
938/938 [==============================] - 73s 77ms/step - loss: 0.6057 - acc: 0.8414 - val_loss: 0.4202 - val_acc: 0.8736
<keras.callbacks.History at 0x20c721521f0>ბიგრამები, ტრიგრამები და n-გრამები
სიტყვების თაიგულის მიდგომის ერთ-ერთი შეზღუდვა არის ის, რომ ზოგიერთი სიტყვა მრავალსიტყვიანი გამონათქვამების ნაწილია, მაგალითად, სიტყვა „ჰოტ-დოგს“ აქვს სრულიად განსხვავებული მნიშვნელობა სხვა კონტექსტში სიტყვებისგან „ცხელი“ და „დოგი“. თუ ჩვენ წარმოვადგენთ სიტყვებს "ცხელი" და "ძაღლი" ყოველთვის ერთი და იგივე ვექტორების გამოყენებით, ამან შეიძლება დააბნიოს ჩვენი მოდელი.
ამის გადასაჭრელად n-გრამების წარმოდგენები ხშირად გამოიყენება დოკუმენტების კლასიფიკაციის მეთოდებში, სადაც თითოეული სიტყვის, ორსიტყვიანი ან სამ-სიტყვის სიხშირე სასარგებლო თვისებაა კლასიფიკატორების ტრენინგისთვის. მაგალითად, ბიგრამების წარმოდგენებში, ორიგინალური სიტყვების გარდა, ლექსიკას დავამატებთ ყველა სიტყვათა წყვილს.
ქვემოთ მოცემულია მაგალითი იმისა, თუ როგორ უნდა შექმნათ სიტყვების წარმოდგენის ბიგრამიანი ტომარა Scikit Learn გამოყენებით:
იტვირთება…გამოტანა
Vocabulary:
{'i': 7, 'like': 11, 'hot': 4, 'dogs': 2, 'i like': 8, 'like hot': 12, 'hot dogs': 5, 'the': 16, 'dog': 0, 'ran': 14, 'fast': 3, 'the dog': 17, 'dog ran': 1, 'ran fast': 15, 'its': 9, 'outside': 13, 'its hot': 10, 'hot outside': 6}
array([[1, 0, 1, 0, 2, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
dtype=int64)n-გრამის მიდგომის მთავარი ნაკლი ის არის, რომ ლექსიკის ზომა ძალიან სწრაფად იწყებს ზრდას. პრაქტიკაში, ჩვენ უნდა გავაერთიანოთ n-გრამის წარმოდგენა განზომილების შემცირების ტექნიკასთან, როგორიცაა embeddings, რომელსაც განვიხილავთ შემდეგ ერთეულში.
ჩვენს AG News მონაცემთა ბაზაში n-გრამის გამოსაყენებლად, ჩვენ უნდა გადავცეთ ngrams პარამეტრი ჩვენს TextVectorization კონსტრუქტორს. ბიგრამების ლექსიკის სიგრძე მნიშვნელოვნად დიდია, ჩვენს შემთხვევაში ის 1,3 მილიონ ტოკენზე მეტია! ამრიგად, აზრი აქვს ბიგრამის ტოკენების შეზღუდვას გარკვეული გონივრული რაოდენობით.
ჩვენ შეგვიძლია გამოვიყენოთ იგივე კოდი, როგორც ზემოთ, კლასიფიკატორის მოსამზადებლად, თუმცა, ეს იქნება ძალიან არაეფექტური მეხსიერება. შემდეგ განყოფილებაში ჩვენ მოვამზადებთ ბიგრამის კლასიფიკატორს ჩაშენების გამოყენებით. იმავდროულად, შეგიძლიათ ექსპერიმენტი ჩაატაროთ ბიგრამის კლასიფიკატორის ტრენინგით ამ ნოუთბუქში და ნახოთ, შეგიძლიათ თუ არა უფრო მაღალი სიზუსტის მიღება.
BoW ვექტორების ავტომატური გაანგარიშება
ზემოთ მოყვანილ მაგალითში ჩვენ ხელით გამოვთვალეთ BoW ვექტორები ცალკეული სიტყვების one-hot კოდირების შეჯამებით. თუმცა, TensorFlow-ის უახლესი ვერსია საშუალებას გვაძლევს ავტომატურად გამოვთვალოთ BoW ვექტორები output_mode='count პარამეტრის ვექტორიზატორის კონსტრუქტორზე გადაცემით. ეს მნიშვნელოვნად ამარტივებს ჩვენი მოდელის განსაზღვრას და სწავლებას:
იტვირთება…გამოტანა
Training vectorizer
938/938 [==============================] - 7s 7ms/step - loss: 0.5929 - acc: 0.8486 - val_loss: 0.4168 - val_acc: 0.8772
<keras.callbacks.History at 0x20c725217c0>ვადის სიხშირე - დოკუმენტის შებრუნებული სიხშირე (TF-IDF)
BoW წარმოდგენაში, სიტყვების გამოვლინებები წონით ხდება იგივე ტექნიკის გამოყენებით, მიუხედავად თავად სიტყვისა. თუმცა, ცხადია, რომ ხშირი სიტყვები, როგორიცაა a და in გაცილებით ნაკლებად მნიშვნელოვანია კლასიფიკაციისთვის, ვიდრე სპეციალიზებული ტერმინები. NLP ამოცანების უმეტესობაში ზოგიერთი სიტყვა უფრო აქტუალურია, ვიდრე სხვები.
TF-IDF ნიშნავს ტერმინი სიხშირე - დოკუმენტის შებრუნებული სიხშირე. ეს არის სიტყვების პაკეტის ვარიაცია, სადაც ორობითი 0/1 მნიშვნელობის ნაცვლად, რომელიც მიუთითებს სიტყვის გამოჩენაზე დოკუმენტში, გამოიყენება მცურავი წერტილის მნიშვნელობა, რომელიც დაკავშირებულია კორპუსში სიტყვის გაჩენის სიხშირესთან.
უფრო ფორმალურად, $w_{ij}$ $i$ სიტყვის წონა დოკუმენტში $j$ განისაზღვრება როგორც: $$ w_{ij} = tf_{ij}\times\log ({N\ მეტი df_i}) $$ სადაც
- $tf_{ij}$ არის $i$-ის შემთხვევების რაოდენობა $j$-ში, ანუ BoW მნიშვნელობა, რომელიც ადრე ვნახეთ.
- $N$ არის კოლექციაში არსებული დოკუმენტების რაოდენობა
- $df_i$ არის დოკუმენტების რაოდენობა, რომლებიც შეიცავს სიტყვას $i$ მთელ კოლექციაში
TF-IDF მნიშვნელობა $w_{ij}$ იზრდება პროპორციულად, რამდენჯერაც ჩნდება სიტყვა დოკუმენტში და კომპენსირდება კორპუსში არსებული დოკუმენტების რაოდენობით, რომელიც შეიცავს სიტყვას, რაც ხელს უწყობს იმ ფაქტს, რომ ზოგიერთი სიტყვა უფრო ხშირად ჩნდება, ვიდრე სხვები. მაგალითად, თუ სიტყვა გამოჩნდება კოლექციის ყველა დოკუმენტში, $df_i=N$ და $w_{ij}=0$ და ეს ტერმინები სრულიად უგულებელყოფილი იქნება.
თქვენ შეგიძლიათ მარტივად შექმნათ ტექსტის TF-IDF ვექტორიზაცია Scikit Learn-ის გამოყენებით:
იტვირთება…გამოტანა
array([[0.43381609, 0. , 0.43381609, 0. , 0.65985664,
0.43381609, 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. ]])Keras-ში TextVectorization ფენას შეუძლია ავტომატურად გამოთვალოს TF-IDF სიხშირეები output_mode='tf-idf' პარამეტრის გადაცემით. გავიმეოროთ ზემოთ გამოყენებული კოდი, რათა ვნახოთ, ზრდის თუ არა TF-IDF-ის გამოყენება სიზუსტეს:
იტვირთება…გამოტანა
Training vectorizer
938/938 [==============================] - 12s 12ms/step - loss: 0.4197 - acc: 0.8662 - val_loss: 0.3432 - val_acc: 0.8849
<keras.callbacks.History at 0x20c729dfd30>დასკვნა
მიუხედავად იმისა, რომ TF-IDF წარმოდგენები იძლევა სიხშირის წონას სხვადასხვა სიტყვებს, ისინი ვერ წარმოადგენენ მნიშვნელობას ან წესრიგს. როგორც 1935 წელს თქვა ცნობილმა ენათმეცნიერმა J. R. Firth-მა, „სიტყვის სრული მნიშვნელობა ყოველთვის კონტექსტუალურია და კონტექსტის გარდა მნიშვნელობის შესწავლა არ შეიძლება სერიოზულად იქნას მიღებული“. ჩვენ ვისწავლით, თუ როგორ მივიღოთ ტექსტიდან კონტექსტური ინფორმაცია ენის მოდელირების გამოყენებით, მოგვიანებით კურსზე.