განმეორებადი ქსელების ერთი მთავარი ნაკლი არის ის, რომ ყველა სიტყვას თანმიმდევრობით ერთნაირი გავლენა აქვს შედეგზე. ეს იწვევს არაოპტიმალურ შესრულებას სტანდარტული LSTM შიფრატორ-დეკოდერის მოდელების თანმიმდევრობით მიმდევრობით დავალებებისთვის, როგორიცაა დასახელებული ერთეულის ამოცნობა და მანქანური თარგმანი. სინამდვილეში, შეყვანის თანმიმდევრობის კონკრეტული სიტყვები ხშირად უფრო მეტ გავლენას ახდენს თანმიმდევრულ გამოსავალზე, ვიდრე სხვები.
განვიხილოთ თანმიმდევრობით-მიმდევრობის მოდელი, როგორიცაა მანქანური თარგმანი. იგი ხორციელდება ორი განმეორებადი ქსელით, სადაც ერთი ქსელი (ენკოდერი) აქცევს შეყვანის თანმიმდევრობას დამალულ მდგომარეობაში, ხოლო მეორე, დეკოდერი, ამ ფარულ მდგომარეობას თარგმნის შედეგში. ამ მიდგომის პრობლემა ის არის, რომ ქსელის საბოლოო მდგომარეობას გაუჭირდება წინადადების დასაწყისის დამახსოვრება, რაც იწვევს მოდელის უხარისხობას გრძელ წინადადებებზე.
ყურადღების მექანიზმები უზრუნველყოფს თითოეული შეყვანის ვექტორის კონტექსტური ზემოქმედების შეწონვის საშუალებას RNN-ის თითოეულ გამომავალ პროგნოზზე. მისი განხორციელების გზა არის მალსახმობების შექმნა შეყვანის RNN-ის შუალედურ მდგომარეობასა და გამომავალ RNN-ს შორის. ამ გზით, $y_t$ გამომავალი სიმბოლოს გენერირებისას, ჩვენ გავითვალისწინებთ ყველა შეყვანის დამალულ მდგომარეობას $h_i$, სხვადასხვა წონის კოეფიციენტებით $\alpha_{t,i}$.
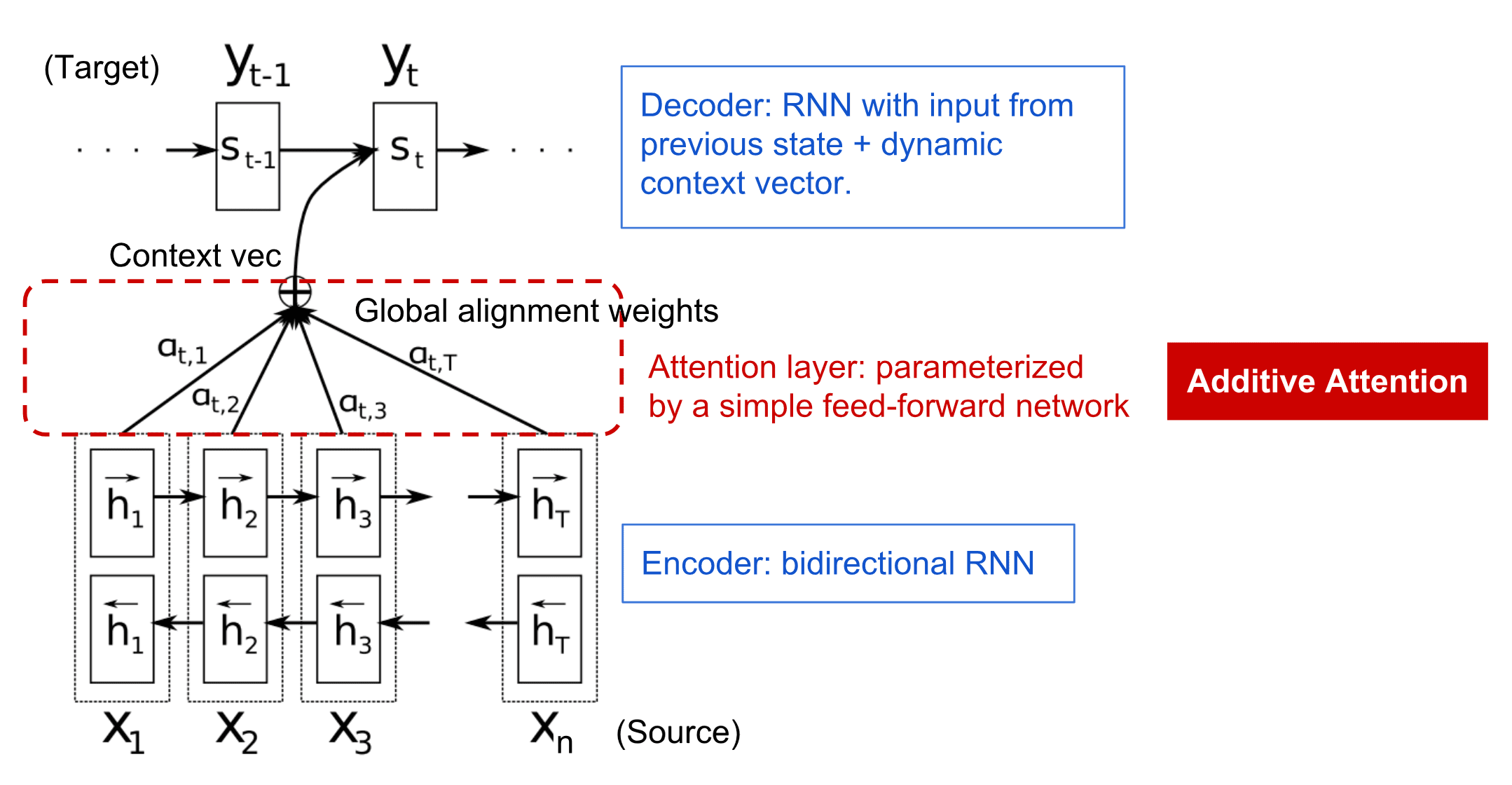 კოდერ-დეკოდერის მოდელი დანამატის ყურადღების მექანიზმით ბაჰდანაუ და სხვები, 2015 წ-ში, ციტირებულია ეს ბლოგის პოსტი-დან
კოდერ-დეკოდერის მოდელი დანამატის ყურადღების მექანიზმით ბაჰდანაუ და სხვები, 2015 წ-ში, ციტირებულია ეს ბლოგის პოსტი-დან
საყურადღებო მატრიცა ${\alpha_{i,j}}$ წარმოადგენს ხარისხს, რომელსაც გარკვეული შემავალი სიტყვები უკრავს მოცემული სიტყვის წარმოქმნისას გამომავალი თანმიმდევრობით. ქვემოთ მოცემულია ასეთი მატრიცის მაგალითი:

სურათი აღებულია ბაჰდანაუ და სხვები, 2015 წ-დან (ნახ.3)
ყურადღების მექანიზმები პასუხისმგებელნი არიან ბუნებრივი ენის დამუშავების თანამედროვე ან თითქმის მიმდინარე მდგომარეობის დიდ ნაწილზე. თუმცა ყურადღების მიქცევა მნიშვნელოვნად ზრდის მოდელის პარამეტრების რაოდენობას, რამაც გამოიწვია სკალირების პრობლემები RNN-ებთან. RNN-ების სკალირების მთავარი შეზღუდვა ის არის, რომ მოდელების განმეორებითი ბუნება რთულს ხდის ტრენინგის ჯგუფურ და პარალელიზებას. RNN-ში, თანმიმდევრობის თითოეული ელემენტი უნდა დამუშავდეს თანმიმდევრული თანმიმდევრობით, რაც ნიშნავს, რომ მისი ადვილად პარალელიზება შეუძლებელია.
ამ შეზღუდვასთან ერთად ყურადღების მექანიზმების გამოყენებამ განაპირობა თანამედროვე ტრანსფორმატორის მოდელების შექმნა, რომლებიც ჩვენ ვიცით და ვიყენებთ დღეს BERT-დან OpenGPT3-მდე.
ტრანსფორმატორის მოდელები
შეფასების საფეხურზე ყოველი წინა პროგნოზის კონტექსტის გადაცემის ნაცვლად, ტრანსფორმატორის მოდელები იყენებს პოზიციურ კოდირებას (positional encoding) და ყურადღების მექანიზმს (attention mechanism) ტექსტის მოცემულ ფანჯარაში შეყვანის კონტექსტის აღსაბეჭდად. ქვემოთ მოყვანილი სურათი გვიჩვენებს, თუ როგორ შეუძლია ყურადღების მქონე პოზიციურ დაშიფვრებს კონტექსტის აღბეჭდვა მოცემულ ფანჯარაში.

იმის გამო, რომ თითოეული შეყვანის პოზიცია დამოუკიდებლად არის შედგენილი თითოეულ გამომავალ პოზიციაზე, ტრანსფორმატორებს შეუძლიათ უკეთესად გაატარონ პარალელიზაცია, ვიდრე RNN, რაც იძლევა ბევრად უფრო დიდ და უფრო გამოხატულ ენობრივ მოდელებს. თითოეული ყურადღების თავი შეიძლება გამოყენებულ იქნას სიტყვებს შორის განსხვავებული ურთიერთობების შესასწავლად, რაც აუმჯობესებს ბუნებრივი ენის დამუშავების ამოცანებს.
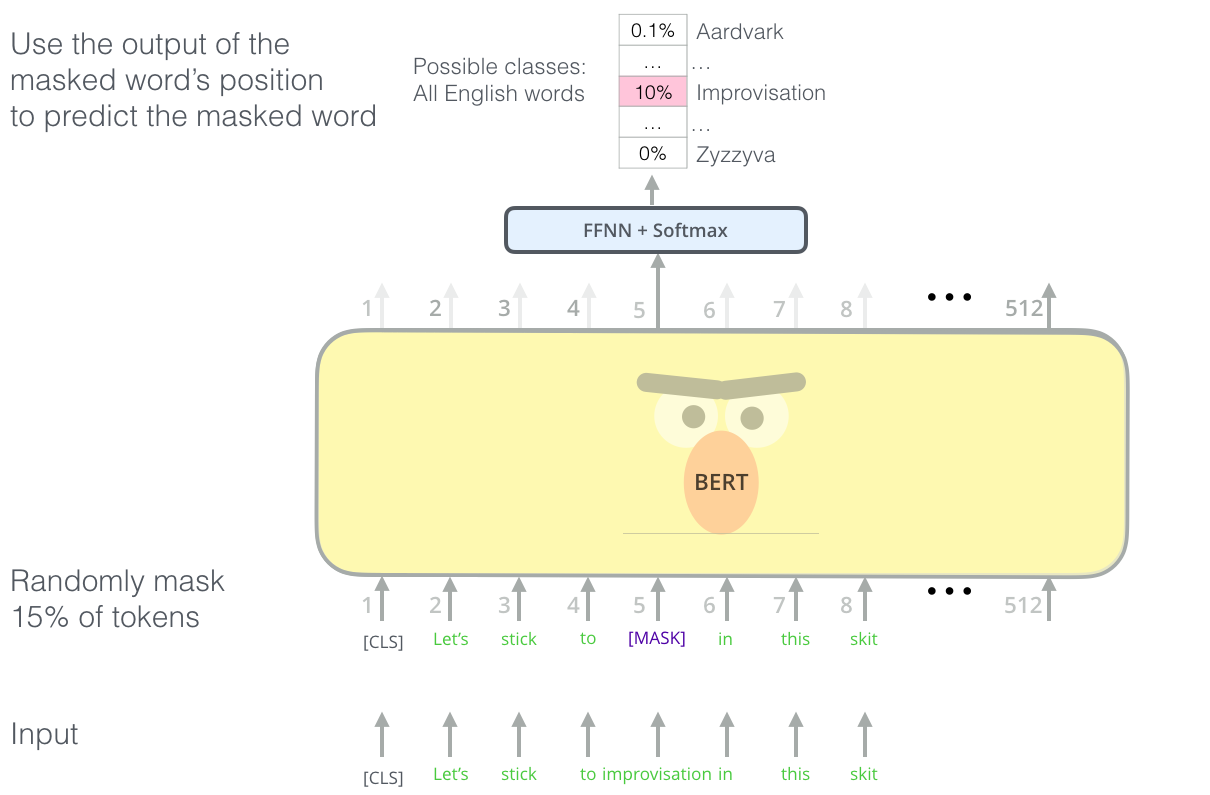
BERT (ორმხრივი კოდირების წარმოდგენები ტრანსფორმერებისგან) არის ძალიან დიდი მრავალშრიანი ტრანსფორმატორის ქსელი 12 ფენით BERT-base-ისთვის და 24 BERT-large-ისთვის. მოდელი პირველად წინასწარ ივარჯიშება ტექსტური მონაცემების დიდ კორპუსზე (ვიკიპედია + წიგნები) უკონტროლო ტრენინგის გამოყენებით (წინადადებაში ნიღბიანი სიტყვების პროგნოზირება). წინასწარი ტრენინგის დროს მოდელი შთანთქავს ენის გაგების მნიშვნელოვან დონეს, რომელიც შემდეგ შეიძლება გამოყენებულ იქნას სხვა მონაცემთა ნაკრებებთან ერთად ზუსტი დარეგულირების გამოყენებით. ამ პროცესს ეწოდება ტრანსფერული სწავლა.
ტრანსფორმატორის არქიტექტურის მრავალი ვარიაციაა, მათ შორის BERT, DistilBERT. BigBird, OpenGPT3 და სხვა, რომელთა დარეგულირება შესაძლებელია. HuggingFace პაკეტი უზრუნველყოფს საცავს PyTorch-ით ამ მრავალი არქიტექტურის სწავლებისთვის.
BERT-ის გამოყენება ტექსტის კლასიფიკაციისთვის
ვნახოთ, როგორ გამოვიყენოთ წინასწარ მომზადებული BERT მოდელი ჩვენი ტრადიციული ამოცანის გადასაჭრელად: თანმიმდევრობის კლასიფიკაცია. ჩვენ დავახარისხებთ ჩვენს თავდაპირველ AG News მონაცემთა ბაზას.
პირველ რიგში, მოდით ჩატვირთოთ HuggingFace ბიბლიოთეკა და ჩვენი მონაცემთა ნაკრები:
იტვირთება…გამოტანა
Loading dataset...
Building vocab...
იმის გამო, რომ ჩვენ გამოვიყენებთ წინასწარ გაწვრთნილ BERT მოდელს, დაგვჭირდება კონკრეტული ტოკენიზატორის გამოყენება. პირველ რიგში, ჩვენ ჩატვირთავთ ტოკენიზერს, რომელიც დაკავშირებულია წინასწარ გაწვრთნილ BERT მოდელთან.
HuggingFace ბიბლიოთეკა შეიცავს წინასწარ მომზადებული მოდელების საცავს, რომელიც შეგიძლიათ გამოიყენოთ მხოლოდ მათი სახელების მითითებით from_pretrained ფუნქციების არგუმენტად. მოდელისთვის საჭირო ყველა ორობითი ფაილი ავტომატურად ჩამოიტვირთება.
თუმცა, გარკვეულ დროს დაგჭირდებათ საკუთარი მოდელების ჩატვირთვა, ამ შემთხვევაში შეგიძლიათ მიუთითოთ დირექტორია, რომელიც შეიცავს ყველა შესაბამის ფაილს, მათ შორის პარამეტრებს ტოკენიზატორისთვის, config.json ფაილი მოდელის პარამეტრებით, ბინარული წონებით და ა.შ.
იტვირთება…tokenizer ობიექტი შეიცავს encode ფუნქციას, რომელიც შეიძლება პირდაპირ იქნას გამოყენებული ტექსტის დაშიფვრისთვის:
იტვირთება…გამოტანა
[101, 1052, 22123, 2953, 2818, 2003, 1037, 2307, 7705, 2005, 17953, 2361, 102]შემდეგ, შევქმნათ იტერატორები, რომლებსაც გამოვიყენებთ ტრენინგის დროს მონაცემების წვდომისთვის. იმის გამო, რომ BERT იყენებს საკუთარი კოდირების ფუნქციას, ჩვენ დაგვჭირდება განვსაზღვროთ შეფუთვის ფუნქცია, რომელიც ადრე განვსაზღვრეთ padify-ს:
იტვირთება…ჩვენს შემთხვევაში, ჩვენ გამოვიყენებთ წინასწარ გაწვრთნილ BERT მოდელს სახელწოდებით bert-base-uncased. მოდით ჩატვირთოთ მოდელი BertForSequenceClassfication პაკეტის გამოყენებით. ეს უზრუნველყოფს, რომ ჩვენს მოდელს უკვე აქვს საჭირო არქიტექტურა კლასიფიკაციისთვის, საბოლოო კლასიფიკატორის ჩათვლით. თქვენ იხილავთ გამაფრთხილებელ შეტყობინებას, რომელშიც ნათქვამია, რომ საბოლოო კლასიფიკატორის წონა არ არის ინიციალიზებული და მოდელი საჭიროებს წინასწარ მომზადებას - ეს აბსოლუტურად ნორმალურია, რადგან ეს არის ზუსტად ის, რის გაკეთებასაც ჩვენ ვაპირებთ!
იტვირთება…გამოტანა
Some weights of the model checkpoint at ./bert were not used when initializing BertForSequenceClassification: ['cls.predictions.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.decoder.weight', 'cls.seq_relationship.weight', 'cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.LayerNorm.bias']
- This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at ./bert and are newly initialized: ['classifier.weight', 'classifier.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
ახლა ჩვენ მზად ვართ ვარჯიშის დასაწყებად! იმის გამო, რომ BERT უკვე წინასწარ არის მომზადებული, ჩვენ გვინდა დავიწყოთ საკმაოდ მცირე სწავლის სიჩქარით, რათა არ გავანადგუროთ საწყისი წონა.
ყველა მძიმე სამუშაო შესრულებულია BertForSequenceClassification მოდელით. როდესაც ჩვენ მოვუწოდებთ მოდელს სასწავლო მონაცემებზე, ის აბრუნებს როგორც დანაკარგს, ასევე ქსელის გამომავალს შეყვანის მინი პარტიისთვის. ჩვენ ვიყენებთ დანაკარგს პარამეტრების ოპტიმიზაციისთვის (loss.backward() აკეთებს უკან გადასასვლელად), და out გამოთვლითი ტრენინგის სიზუსტისთვის, მიღებული ეტიკეტების labs (გამოთვლილი argmax გამოყენებით) მოსალოდნელ labels-თან შედარებით.
პროცესის გასაკონტროლებლად, ჩვენ ვაგროვებთ დანაკარგს და სიზუსტეს რამდენიმე გამეორებაზე და ვბეჭდავთ მათ ყოველ report_freq სასწავლო ციკლში.
ამ ტრენინგს, სავარაუდოდ, საკმაოდ დიდი დრო დასჭირდება, ამიტომ ჩვენ ვზღუდავთ გამეორებების რაოდენობას.
იტვირთება…გამოტანა
Loss = 1.1254194641113282, Accuracy = 0.585
Loss = 0.6194715118408203, Accuracy = 0.83
Loss = 0.46665248870849607, Accuracy = 0.8475
Loss = 0.4309701919555664, Accuracy = 0.8575
Loss = 0.35427074432373046, Accuracy = 0.8825
Loss = 0.3306886291503906, Accuracy = 0.8975
Loss = 0.30340143203735354, Accuracy = 0.8975
Loss = 0.26139299392700194, Accuracy = 0.915
Loss = 0.26708646774291994, Accuracy = 0.9225
Loss = 0.3667240524291992, Accuracy = 0.8675
თქვენ ხედავთ (განსაკუთრებით თუ გაზრდით გამეორებების რაოდენობას და დიდხანს დაელოდებით), რომ BERT კლასიფიკაცია საკმაოდ კარგ სიზუსტეს გვაძლევს! ეს იმიტომ ხდება, რომ BERT-ს უკვე კარგად ესმის ენის სტრუქტურა და ჩვენ მხოლოდ საბოლოო კლასიფიკატორის დაზუსტება გვჭირდება. თუმცა, იმის გამო, რომ BERT არის დიდი მოდელი, მთელი სასწავლო პროცესი დიდ დროს იღებს და მოითხოვს სერიოზულ გამოთვლით ძალას! (GPU და სასურველია ერთზე მეტი).
შენიშვნა: ჩვენს მაგალითში, ჩვენ ვიყენებდით ერთ-ერთ ყველაზე პატარა წინასწარ მომზადებულ BERT მოდელს. არსებობს უფრო დიდი მოდელები, რომლებიც, სავარაუდოდ, უკეთეს შედეგს მოიტანენ.
მოდელის მუშაობის შეფასება
ახლა ჩვენ შეგვიძლია შევაფასოთ ჩვენი მოდელის შესრულება ტესტის მონაცემთა ბაზაზე. შეფასების ციკლი საკმაოდ ჰგავს ტრენინგს, მაგრამ არ უნდა დაგვავიწყდეს მოდელის შეფასების რეჟიმში გადართვა model.eval()-ის დარეკვით.
იტვირთება…გამოტანა
Final accuracy: 0.9047029702970297
Takeaway
ამ განყოფილებაში ჩვენ დავინახეთ, თუ რამდენად ადვილია წინასწარ მომზადებული ენის მოდელის აღება ტრანსფორმერების ბიბლიოთეკიდან და მისი ადაპტირება ტექსტის კლასიფიკაციის ამოცანასთან. ანალოგიურად, BERT მოდელები შეიძლება გამოყენებულ იქნას ერთეულის ამოღების, კითხვებზე პასუხის გაცემის და სხვა NLP ამოცანებისთვის.
ტრანსფორმატორის მოდელები წარმოადგენს უახლეს მიღწევას (state-of-the-art) NLP-ში და უმეტეს შემთხვევაში ეს უნდა იყოს პირველი გამოსავალი, რომლითაც დაიწყებთ ექსპერიმენტებს პერსონალური NLP გადაწყვეტილებების განხორციელებისას. თუმცა, ამ მოდულში განხილული განმეორებადი ნერვული ქსელების ძირითადი პრინციპების გაგება ძალზე მნიშვნელოვანია, თუ გსურთ შექმნათ მოწინავე ნერვული მოდელები.