სალექციო ვიქტორინა
განმეორებადი ნერვული ქსელები (RNN) და მათი დახურული უჯრედების ვარიანტები, როგორიცაა გრძელვადიანი მოკლევადიანი მეხსიერების უჯრედები (LSTMs) და Gated Recurrent Units (GRUs) უზრუნველყოფენ ენის მოდელირების მექანიზმს, რომ მათ შეუძლიათ ისწავლონ სიტყვების დალაგება და შემდეგი სიტყვის პროგნოზირება თანმიმდევრობით. ეს გვაძლევს საშუალებას გამოვიყენოთ RNN-ები გენერაციული ამოცანებისთვის, როგორიცაა ჩვეულებრივი ტექსტის გენერირება, მანქანური თარგმანი და სურათის წარწერაც კი.
დაფიქრდით ყველა დროზე, როდესაც ისარგებლეთ გენერაციული ამოცანებით, როგორიცაა ტექსტის დასრულება აკრეფისას. ჩაატარეთ გამოკვლევა თქვენს საყვარელ აპლიკაციებში, რათა ნახოთ, გამოიყენეს თუ არა RNN-ები.
RNN არქიტექტურაში, რომელიც განვიხილეთ წინა ერთეულში, თითოეული RNN ერთეული აწარმოებდა შემდეგ ფარულ მდგომარეობას, როგორც გამომავალს. თუმცა, ჩვენ ასევე შეგვიძლია დავამატოთ კიდევ ერთი გამომავალი თითოეულ განმეორებად ერთეულს, რომელიც მოგვცემს საშუალებას გამოვიტანოთ მიმდევრობა (რომელიც სიგრძით უდრის თავდაპირველ მიმდევრობას). უფრო მეტიც, ჩვენ შეგვიძლია გამოვიყენოთ RNN ერთეულები, რომლებიც არ იღებენ შეყვანას ყოველ საფეხურზე და უბრალოდ ავიღოთ საწყისი მდგომარეობის ვექტორი და შემდეგ გამოვიტანოთ გამომავლების თანმიმდევრობა.
ეს იძლევა სხვადასხვა ნერვულ არქიტექტურას, რომლებიც ნაჩვენებია ქვემოთ მოცემულ სურათზე:
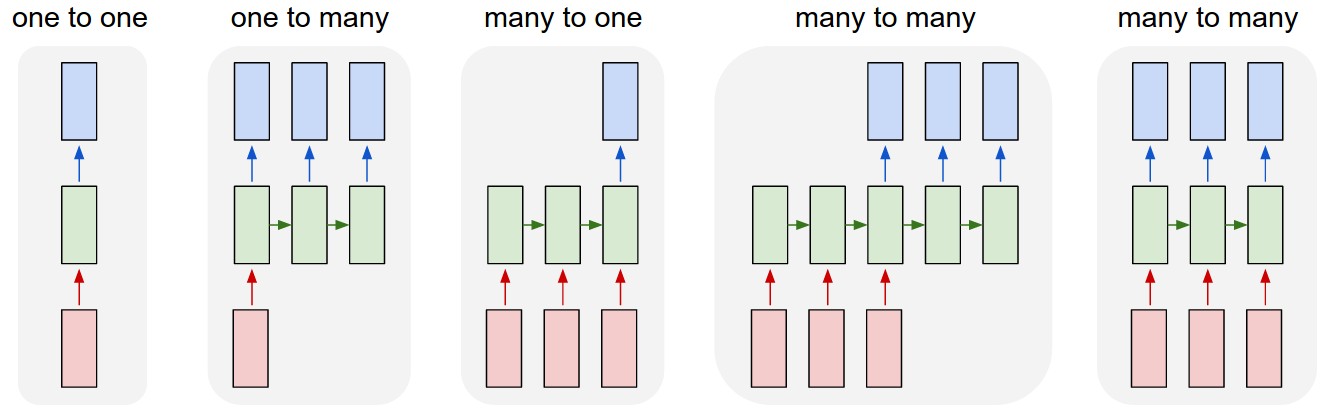
სურათი ბლოგის პოსტიდან მორეციდივე ნერვული ქსელების არაგონივრული ეფექტურობა ანდრეი კარპატი-ის მიერ
- ერთი-ერთზე არის ტრადიციული ნერვული ქსელი ერთი შეყვანით და ერთი გამომავალით
- ერთი-მრავალზე არის გენერაციული არქიტექტურა, რომელიც იღებს ერთ შეყვანის მნიშვნელობას და წარმოქმნის გამომავალი მნიშვნელობების თანმიმდევრობას. მაგალითად, თუ გვინდა გავავარჯიშოთ გამოსახულების წარწერის ქსელი, რომელიც აწარმოებს სურათის ტექსტურ აღწერას, ჩვენ შეგვიძლია სურათის შეყვანა, გადავიტანოთ CNN-ში, რათა მივიღოთ მისი ფარული მდგომარეობა, შემდეგ კი განმეორებადი ჯაჭვი წარმოქმნის წარწერას სიტყვა-სიტყვით.
- ბევრი ერთში შეესაბამება RNN არქიტექტურებს, რომლებიც ჩვენ აღვწერეთ წინა განყოფილებაში, როგორიცაა ტექსტის კლასიფიკაცია
- ბევრი-მრავალზე, ან მიმდევრობა-მიმდევრობა შეესაბამება ამოცანებს, როგორიცაა მანქანური თარგმნა, სადაც ჩვენ ჯერ RNN შეაგროვებს ყველა ინფორმაციას შეყვანის თანმიმდევრობიდან დამალულ მდგომარეობაში, ხოლო სხვა RNN ჯაჭვი ამ მდგომარეობას ხსნის გამომავალ თანმიმდევრობაში.
ამ განყოფილებაში ჩვენ ყურადღებას გავამახვილებთ მარტივ გენერაციულ მოდელებზე, რომლებიც დაგვეხმარება ტექსტის გენერირებაში. სიმარტივისთვის, ჩვენ გამოვიყენებთ სიმბოლოების დონის ტოკენიზაციას.
ჩვენ მოვამზადებთ ამ RNN-ს ტექსტის გენერირებისთვის ეტაპობრივად. თითოეულ საფეხურზე ჩვენ ავიღებთ nchars სიგრძის სიმბოლოების თანმიმდევრობას და ვთხოვთ ქსელს, შექმნას შემდეგი გამომავალი სიმბოლო თითოეული შეყვანის სიმბოლოსთვის:
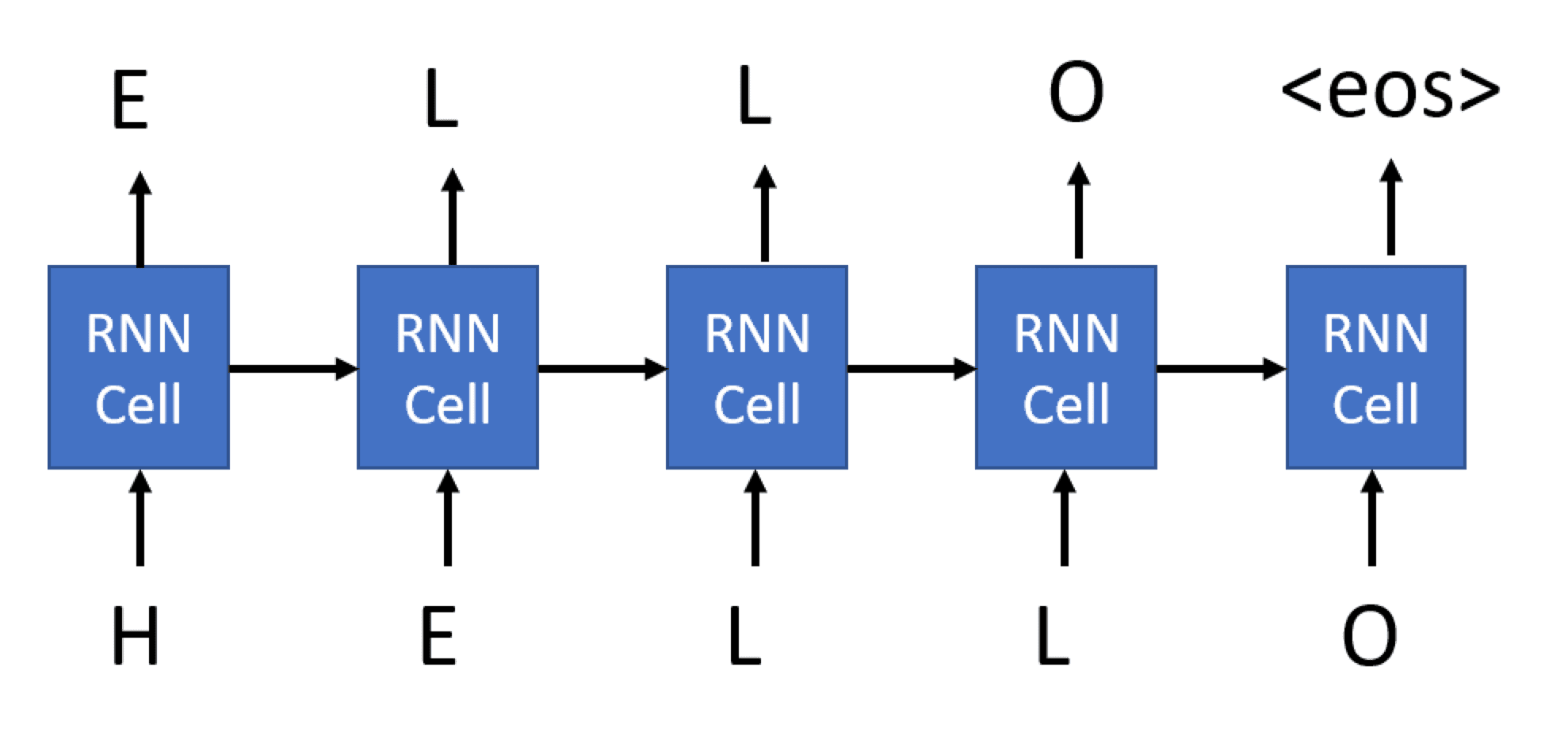
ტექსტის გენერირებისას (დასკვნის დროს) ვიწყებთ მოთხოვნით, რომელიც გადაეცემა RNN უჯრედებში მისი შუალედური მდგომარეობის გენერირებისთვის და შემდეგ ამ მდგომარეობიდან იწყება გენერაცია. ჩვენ ვაგენერირებთ ერთ სიმბოლოს ერთდროულად და გადავცემთ მდგომარეობას და გენერირებულ სიმბოლოს სხვა RNN უჯრედს, რომ გენერირება შემდეგი, სანამ არ გენერირება საკმარისი სიმბოლო.
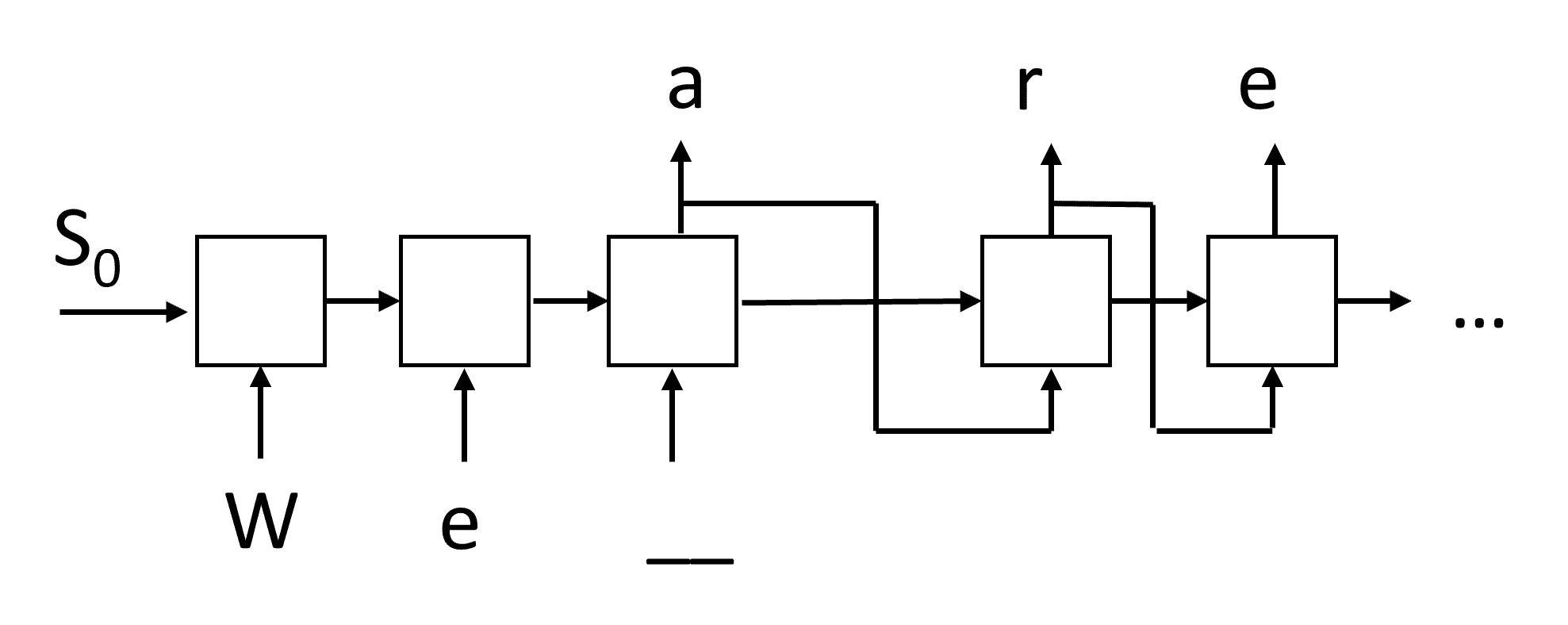
ავტორის სურათი
სავარჯიშოები: გენერაციული ქსელები
განაგრძეთ სწავლა შემდეგ რვეულებში:
- გენერაციული ქსელები PyTorch-ით
- გენერაციული ქსელები TensorFlow-ით
რბილი ტექსტის გენერაცია და ტემპერატურა
თითოეული RNN უჯრედის გამომავალი არის სიმბოლოების ალბათობის განაწილება. თუ გენერირებულ ტექსტში ყოველთვის ავიღებთ ყველაზე დიდი ალბათობით სიმბოლოს, როგორც მომდევნო სიმბოლოს, ტექსტი ხშირად შეიძლება "ციკლი" გახდეს იგივე სიმბოლოების თანმიმდევრობებს შორის ისევ და ისევ, როგორც ამ მაგალითში:
today of the second the company and a second the company ...
თუმცა, თუ გადავხედავთ ალბათობის განაწილებას შემდეგი სიმბოლოსთვის, შეიძლება იყოს ის, რომ განსხვავება რამდენიმე უმაღლეს ალბათობას შორის არ არის დიდი, მაგ. ერთ სიმბოლოს შეიძლება ჰქონდეს ალბათობა 0.2, მეორეს - 0.19 და ა.შ. მაგალითად, "play" თანმიმდევრობით შემდეგი სიმბოლოს ძიებისას, შემდეგი სიმბოლო შეიძლება იყოს ან სივრცე, ან e (როგორც სიტყვაში player).
ეს მიგვიყვანს დასკვნამდე, რომ ყოველთვის არ არის „სამართლიანი“ პერსონაჟის უფრო მაღალი ალბათობით შერჩევა, რადგან მეორე უმაღლესის არჩევამ შესაძლოა მაინც მიგვიყვანოს შინაარსიან ტექსტამდე. უფრო გონივრული იქნება აირჩიოთ სიმბოლოები ქსელის გამომავალი ალბათობის განაწილებიდან. ჩვენ ასევე შეგვიძლია გამოვიყენოთ პარამეტრი, ტემპერატურა, რომელიც გაასწორებს ალბათობის განაწილებას, იმ შემთხვევაში, თუ ჩვენ გვინდა დავამატოთ მეტი შემთხვევითობა, ან გავხადოთ ის უფრო ციცაბო, თუ გვსურს მეტი დავტოვოთ ყველაზე მაღალი ალბათობის სიმბოლოებზე.
გამოიკვლიეთ, თუ როგორ არის დანერგილი ეს რბილი ტექსტის გენერაცია ზემოთ მითითებულ ნოუთბუქებში.
დასკვნა
მიუხედავად იმისა, რომ ტექსტის გენერირება შეიძლება სასარგებლო იყოს თავისთავად, ძირითადი სარგებელი მოდის ტექსტის გენერირების შესაძლებლობიდან RNN-ების გამოყენებით ზოგიერთი საწყისი ფუნქციის ვექტორიდან. მაგალითად, ტექსტის გენერირება გამოიყენება მანქანური თარგმანის ნაწილად (მიმდევრობა-მიმდევრობით, ამ შემთხვევაში მდგომარეობის ვექტორი ენკოდერიდან გამოიყენება თარგმნილი შეტყობინების გენერირებისთვის ან *გაშიფვრისთვის), ან გამოსახულების ტექსტური აღწერის გენერირებისთვის (ამ შემთხვევაში ფუნქციის ვექტორი CNN ექსტრაქტორიდან მოდის).
გამოწვევა
გაიარეთ რამდენიმე გაკვეთილი Microsoft Learn-ზე ამ თემაზე
- ტექსტის გენერაცია PyTorch/TensorFlow-ით
ლექციის შემდგომი ვიქტორინა
მიმოხილვა და თვითშესწავლა
აქ არის რამდენიმე სტატია თქვენი ცოდნის გასაფართოებლად
- ტექსტის გენერირების განსხვავებული მიდგომები Markov Chain, LSTM და GPT-2: ბლოგის პოსტი
- ტექსტის გენერირების ნიმუში კერას დოკუმენტაცია-ში