გამოსახულების კლასიფიკაციის მოდელებმა, რომლებთანაც ჩვენ აქამდე განვიხილეთ, აიღეს სურათი და გამოიღეს კატეგორიული შედეგი, როგორიცაა კლასის „რიცხვი“ MNIST პრობლემაში. თუმცა, ხშირ შემთხვევაში ჩვენ არ გვინდა უბრალოდ ვიცოდეთ, რომ სურათი ასახავს ობიექტებს - ჩვენ გვინდა შევძლოთ მათი ზუსტი მდებარეობის დადგენა. ეს არის ზუსტად ობიექტის აღმოჩენის წერტილი.
სალექციო ვიქტორინა
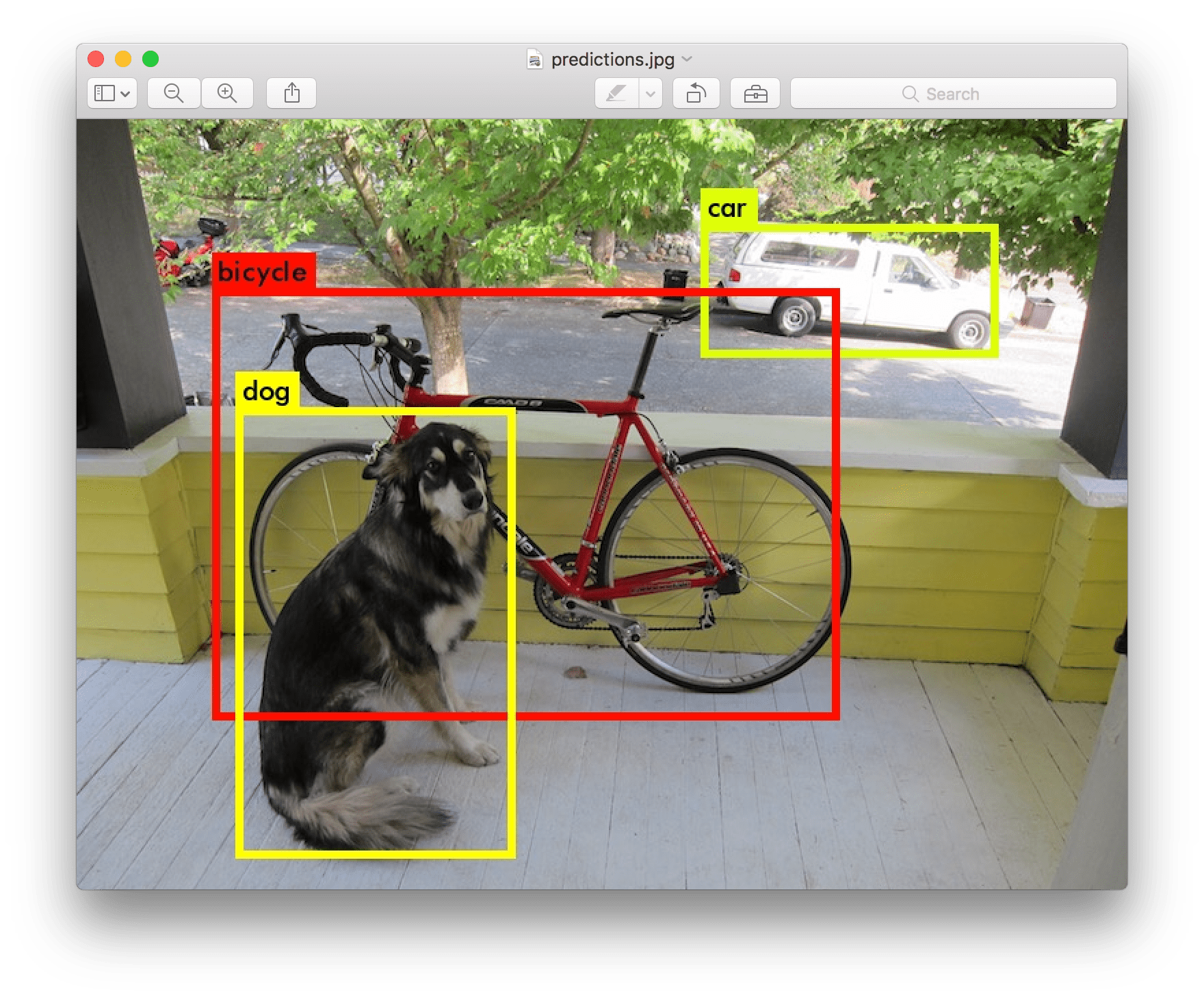
სურათი YOLO v2 ვებსაიტი-დან
გულუბრყვილო მიდგომა ობიექტების გამოვლენისადმი
თუ ვივარაუდებთ, რომ გვინდოდა კატის პოვნა სურათზე, ძალიან გულუბრყვილო მიდგომა ობიექტების აღმოჩენის მიმართ იქნება შემდეგი:
- დაყავით სურათი რამდენიმე ფილამდე
- გაუშვით გამოსახულების კლასიფიკაცია თითოეულ ფილაზე.
- ის ფილები, რომლებიც იწვევს საკმარისად მაღალ აქტივაციას, შეიძლება ჩაითვალოს, რომ შეიცავს მოცემულ ობიექტს.
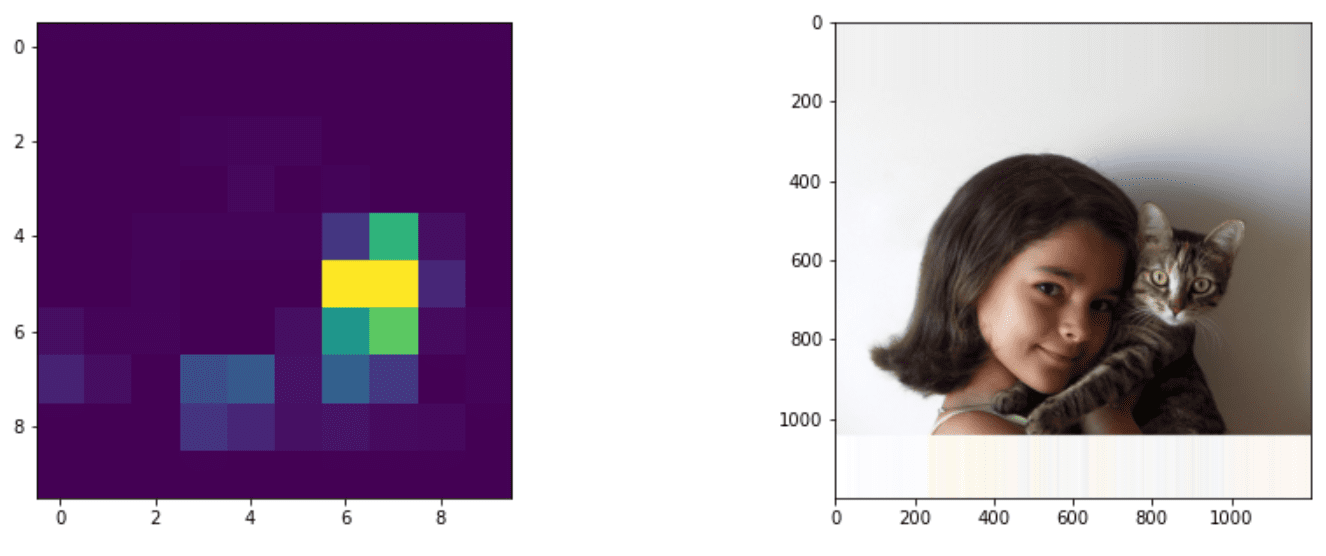
სურათი სავარჯიშო ნოუთბუქი-დან
თუმცა, ეს მიდგომა შორს არის იდეალურისგან, რადგან ის მხოლოდ საშუალებას აძლევს ალგორითმს, ძალიან არაზუსტად დაადგინოს ობიექტის შემოსაზღვრული ყუთი. უფრო ზუსტი მდებარეობისთვის, ჩვენ გვჭირდება რაიმე სახის რეგრესია, რათა ვიწინასწარმეტყველოთ შემოსაზღვრული უჯრების კოორდინატები - და ამისთვის გვჭირდება მონაცემთა კონკრეტული ნაკრები.
რეგრესია ობიექტების აღმოჩენისთვის
ეს ბლოგის პოსტი აქვს შესანიშნავი ნაზი შესავალი ფორმების ამოცნობაში.
მონაცემთა ნაკრები ობიექტების გამოვლენისთვის
ამ ამოცანისთვის შეგიძლიათ გაუშვათ შემდეგი მონაცემთა ნაკრები:
- PASCAL VOC - 20 კლასი
- კოკო - საერთო ობიექტები კონტექსტში. 80 კლასი, შეზღუდვის ყუთები და სეგმენტაციის ნიღბები

ობიექტის გამოვლენის მეტრიკა
კვეთა კავშირის თავზე
მიუხედავად იმისა, რომ გამოსახულების კლასიფიკაციისთვის ადვილია გავზომოთ რამდენად კარგად მუშაობს ალგორითმი, ობიექტის აღმოჩენისთვის ჩვენ უნდა გავზომოთ როგორც კლასის სისწორე, ასევე დასკვნის შეზღუდვის მდებარეობის სიზუსტე. ამ უკანასკნელისთვის ჩვენ ვიყენებთ ეგრეთ წოდებულ გადაკვეთას კავშირზე (IoU), რომელიც ზომავს რამდენად კარგად არის გადახურული ორი ყუთი (ან ორი თვითნებური ტერიტორია).
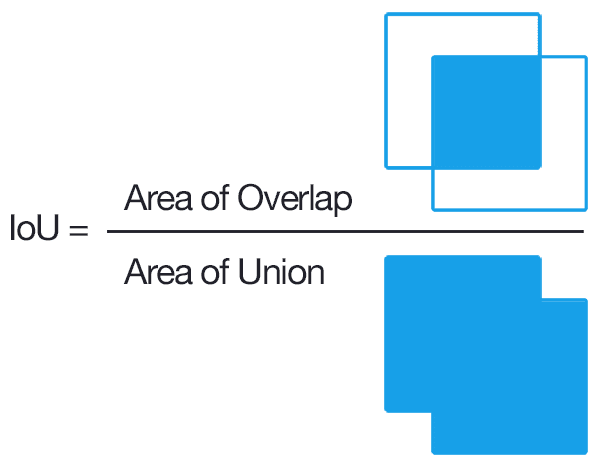
სურათი 2 ეს შესანიშნავი ბლოგის პოსტი IoU-ზე-დან
იდეა მარტივია - ორ ფიგურას შორის გადაკვეთის ფართობს ვყოფთ მათი შეერთების ფართობზე. ორი იდენტური უბნისთვის, IoU იქნება 1, ხოლო სრულიად განცალკევებული უბნებისთვის იქნება 0. წინააღმდეგ შემთხვევაში, ის იცვლება 0-დან 1-მდე. ჩვენ ჩვეულებრივ განვიხილავთ მხოლოდ იმ შეზღუდულ ველებს, რომლებისთვისაც IoU აღემატება გარკვეულ მნიშვნელობას.
საშუალო სიზუსტე
დავუშვათ, გვინდა გავზომოთ რამდენად კარგად არის აღიარებული $C$ ობიექტების მოცემული კლასი. მის გასაზომად ვიყენებთ საშუალო სიზუსტის მეტრიკას, რომელიც გამოითვლება შემდეგნაირად:
- განვიხილოთ Precision-Recall მრუდი აჩვენებს სიზუსტეს, რომელიც დამოკიდებულია აღმოჩენის ზღურბლის მნიშვნელობაზე (0-დან 1-მდე).
- ზღურბლიდან გამომდინარე მივიღებთ სურათზე გამოვლენილ მეტ-ნაკლებად ობიექტებს და სიზუსტისა და დამახსოვრების სხვადასხვა მნიშვნელობებს.
- მრუდი ასე გამოიყურება:

სურათი ნეიროვორკშოპი-დან
საშუალო სიზუსტე მოცემული კლასისთვის $C$ არის ფართობი ამ მრუდის ქვეშ. უფრო ზუსტად, გახსენების ღერძი ჩვეულებრივ იყოფა 10 ნაწილად და სიზუსტე საშუალოდ ფასდება ყველა იმ წერტილზე:
$$ AP = {1\over11}\sum_{i=0}^{10}\mbox{Precision}(\mbox{გახსენება}={i\over10}) $$
AP და IoU
ჩვენ განვიხილავთ მხოლოდ იმ აღმოჩენებს, რომელთათვისაც IoU არის გარკვეულ მნიშვნელობაზე მეტი. მაგალითად, PASCAL VOC მონაცემთა ნაკრებში, როგორც წესი, $\mbox{IoU Threshold} = 0.5$ არის გათვალისწინებული, ხოლო COCO AP-ში იზომება $\mbox{IoU Threshold}$-ის სხვადასხვა მნიშვნელობებისთვის.

სურათი ნეიროვორკშოპი-დან
საშუალო საშუალო სიზუსტე - mAP
ობიექტის ამოცნობის მთავარ მეტრიკას ეწოდება საშუალო საშუალო სიზუსტე, ან mAP. ეს არის საშუალო სიზუსტის მნიშვნელობა, საშუალო ობიექტის ყველა კლასში და ზოგჯერ $\mbox{IoU ბარიერი}$-ზე მეტი. უფრო დეტალურად აღწერილია mAP გაანგარიშების პროცესი ამ ბლოგის პოსტში), და ასევე აქ კოდის ნიმუშებით.
ობიექტების გამოვლენის სხვადასხვა მიდგომები
არსებობს ობიექტების აღმოჩენის ალგორითმის ორი ფართო კლასი:
- რეგიონის შეთავაზების ქსელები (R-CNN, სწრაფი R-CNN, უფრო სწრაფი R-CNN). მთავარი იდეაა ინტერესების რეგიონების (ROI) გენერირება და მათზე CNN-ის გაშვება, მაქსიმალური გააქტიურების ძიებაში. ეს ცოტათი წააგავს გულუბრყვილო მიდგომას, გარდა იმისა, რომ ROI-ები უფრო ჭკვიანურად იქმნება. ასეთი მეთოდების ერთ-ერთი მთავარი ნაკლი არის ის, რომ ისინი ნელია, რადგან ჩვენ გვჭირდება CNN კლასიფიკატორის მრავალი გადასასვლელი სურათზე.
- ერთი გადასასვლელი (YOLO, SSD, RetinaNet) მეთოდები. ამ არქიტექტურებში ჩვენ ვქმნით ქსელს, რათა ვიწინასწარმეტყველოთ ორივე კლასები და ROI-ები ერთი პასით.
R-CNN: რეგიონზე დაფუძნებული CNN
R-CNN იყენებს შერჩევითი ძებნა-ს ROI რეგიონების იერარქიული სტრუქტურის გენერირებისთვის, რომლებიც შემდეგ გადაეცემა CNN-ის ფუნქციების ამომყვანებსა და SVM-კლასიფიკატორებს ობიექტის კლასის დასადგენად და ხაზოვან რეგრესიას შეზღუდული უჯრის კოორდინატების დასადგენად. ოფიციალური ნაშრომი

სურათი van de Sande et al. ICCV'11
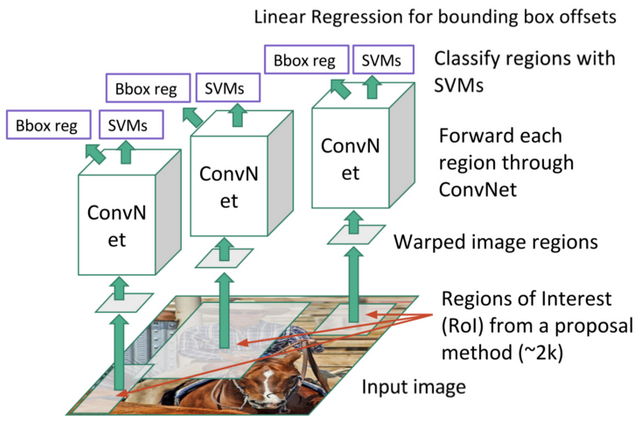
*სურათები ეს ბლოგი-დან
F-RCNN - სწრაფი R-CNN
ეს მიდგომა R-CNN-ის მსგავსია, მაგრამ რეგიონები განისაზღვრება კონვოლუციის ფენების გამოყენების შემდეგ.
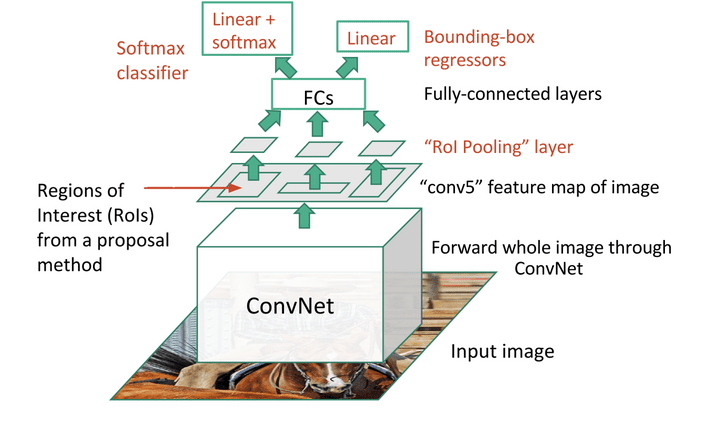
სურათი ოფიციალური დოკუმენტი-დან, arXiv, 2015 წ.
უფრო სწრაფი R-CNN
ამ მიდგომის მთავარი იდეაა ნერვული ქსელის გამოყენება ROI-ების პროგნოზირებისთვის - ე.წ. Region Proposal Network. ქაღალდი, 2016 წ
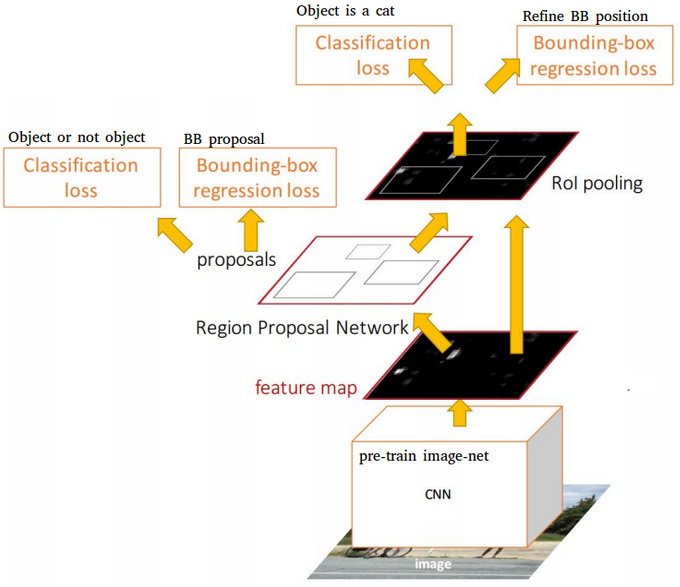
სურათი ოფიციალური ქაღალდი-დან
R-FCN: რეგიონზე დაფუძნებული სრულად კონვოლუციური ქსელი
ეს ალგორითმი უფრო სწრაფია ვიდრე Faster R-CNN. მთავარი იდეა შემდეგია:
- ჩვენ ვიღებთ ფუნქციებს ResNet-101-ის გამოყენებით
- ფუნქციები დამუშავებულია პოზიციისადმი მგრძნობიარე ქულების რუქით. $C$ კლასებიდან თითოეული ობიექტი იყოფა $k\times k$ რეგიონებით და ჩვენ ვვარჯიშობთ ობიექტების ნაწილების პროგნოზირებისთვის.
- $k\times k$ რეგიონებიდან თითოეული ნაწილისთვის ყველა ქსელი ხმას აძლევს ობიექტის კლასებს და არჩეულია ობიექტის კლასი მაქსიმალური ხმის მქონე.
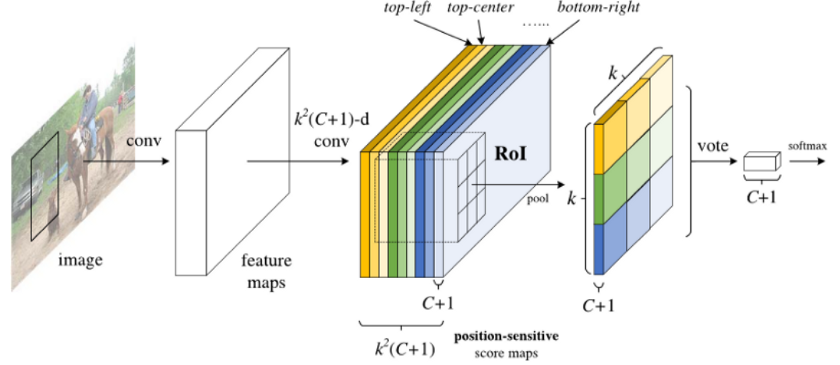
სურათი ოფიციალური ქაღალდი-დან
YOLO - მხოლოდ ერთხელ უყურებ
YOLO არის რეალურ დროში, ერთი გადასასვლელი ალგორითმი. მთავარი იდეა შემდეგია:
- სურათი დაყოფილია $S\ჯერ S$ რეგიონებად
- თითოეული რეგიონისთვის, CNN პროგნოზირებს $n$ შესაძლო ობიექტებს, შეზღუდულ ველს კოორდინატებს და დარწმუნებას=ალბათობას * IoU.
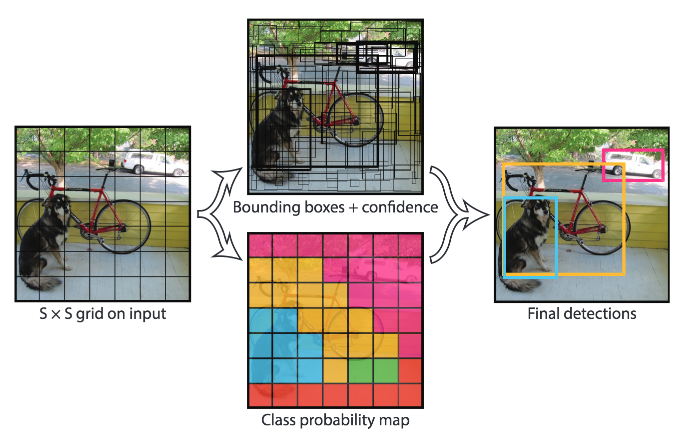
სურათი ოფიციალური ქაღალდი-დან
სხვა ალგორითმები
- RetinaNet: ოფიციალური ქაღალდი
- PyTorch დანერგვა Torchvision-ში
- Keras იმპლემენტაცია
- ობიექტების გამოვლენა RetinaNet-ით Keras Samples-ში
- SSD (ერთჯერადი გასროლის დეტექტორი): ოფიციალური ქაღალდი
სავარჯიშოები: ობიექტების ამოცნობა
განაგრძეთ სწავლა შემდეგ რვეულში:
ObjectDetection.ipynb
დასკვნა
ამ გაკვეთილზე თქვენ მოინახულეთ გრიგალის ტური ყველა სხვადასხვა გზით, რომლითაც შესაძლებელია ობიექტების ამოცნობა!
გამოწვევა
წაიკითხეთ ეს სტატიები და ნოუთბუქები YOLO-ს შესახებ და სცადეთ ისინი თქვენთვის
- კარგი ბლოგის პოსტი აღწერს YOLO-ს
- ოფიციალური საიტი
- Yolo: Keras განხორციელება, ნაბიჯ-ნაბიჯ ნოუთბუქი
- Yolo v2: Keras განხორციელება, ნაბიჯ-ნაბიჯ ნოუთბუქი
ლექციის შემდგომი ვიქტორინა
მიმოხილვა და თვითშესწავლა
- ობიექტის გამოვლენა ნიხილ სარდანას მიერ
- ობიექტების აღმოჩენის ალგორითმების კარგი შედარება
- ღრმა სწავლის ალგორითმების მიმოხილვა ობიექტების აღმოჩენისთვის
- ნაბიჯ-ნაბიჯ შესავალი ობიექტების გამოვლენის ძირითადი ალგორითმების შესახებ
- უფრო სწრაფი R-CNN-ის დანერგვა პითონში ობიექტების აღმოჩენისთვის