წინა მოდულში ჩვენ ვიყენებდით ტექსტის მდიდარ სემანტიკურ წარმოდგენებს და ემბედინგების თავზე მარტივ ხაზოვან კლასიფიკატორს. რასაც ეს არქიტექტურა აკეთებს არის სიტყვების გაერთიანებული მნიშვნელობის აღქმა წინადადებაში, მაგრამ ის არ ითვალისწინებს სიტყვების მიმდევრობას, რადგან ჩაშენების თავზე აგრეგაციის ოპერაციამ ამოიღო ეს ინფორმაცია ორიგინალური ტექსტიდან. იმის გამო, რომ ამ მოდელებს არ შეუძლიათ სიტყვების დალაგების მოდელირება, მათ არ შეუძლიათ გადაჭრან უფრო რთული ან ორაზროვანი ამოცანები, როგორიცაა ტექსტის შექმნა ან კითხვებზე პასუხის გაცემა.
ტექსტის თანმიმდევრობის მნიშვნელობის გასაგებად, ჩვენ უნდა გამოვიყენოთ სხვა ნერვული ქსელის არქიტექტურა, რომელსაც ეწოდება განმეორებადი ნერვული ქსელი, ან RNN. RNN-ში ჩვენ წინადადებას ქსელის მეშვეობით გადავცემთ თითო სიმბოლოს და ქსელი აწარმოებს რაღაც მდგომარეობას, რომელსაც შემდეგ კვლავ გადავცემთ ქსელს შემდეგი სიმბოლოთი.
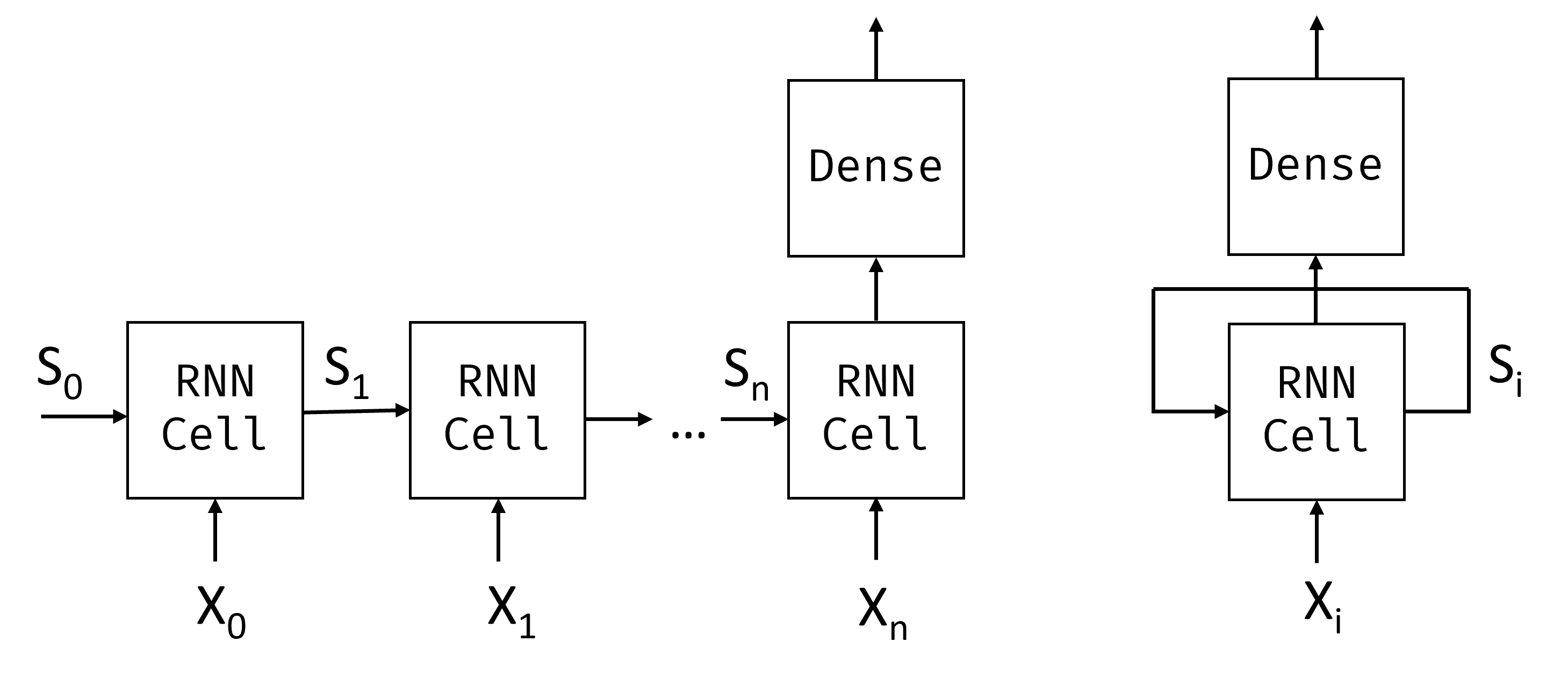
$X_0,\dots,X_n$ ნიშნების შეყვანის თანმიმდევრობის გათვალისწინებით, RNN ქმნის ნერვული ქსელის ბლოკების თანმიმდევრობას და ავარჯიშებს ამ თანმიმდევრობას ბოლოდან ბოლომდე უკანა გამრავლების გამოყენებით. თითოეული ქსელის ბლოკი იღებს $(X_i,S_i)$ წყვილს, როგორც შეყვანას და შედეგად წარმოქმნის $S_{i+1}$-ს. საბოლოო მდგომარეობა $S_n$ ან გამომავალი $X_n$ გადადის წრფივ კლასიფიკატორში შედეგის მისაღებად. ქსელის ყველა ბლოკი იზიარებს ერთსა და იმავე წონას და წვრთნიან ბოლომდე გავრცელების ერთი საშვის გამოყენებით.
იმის გამო, რომ $S_0,\dots,S_n$ მდგომარეობის ვექტორები გადადის ქსელში, მას შეუძლია ისწავლოს თანმიმდევრული დამოკიდებულებები სიტყვებს შორის. მაგალითად, როდესაც სიტყვა not გამოჩნდება სადმე მიმდევრობაში, მას შეუძლია ისწავლოს გარკვეული ელემენტების უარყოფა მდგომარეობის ვექტორში, რაც გამოიწვევს უარყოფას.
ვინაიდან სურათზე ყველა RNN ბლოკის წონა გაზიარებულია, ერთი და იგივე სურათი შეიძლება წარმოდგენილი იყოს როგორც ერთი ბლოკი (მარჯვნივ) განმეორებითი უკუკავშირის მარყუჟით, რომელიც გადასცემს ქსელის გამომავალ მდგომარეობას უკან შეყვანაში.
ვნახოთ, როგორ დაგვეხმარება განმეორებადი ნერვული ქსელები ახალი ამბების მონაცემთა ბაზის კლასიფიკაციაში.
იტვირთება…გამოტანა
Loading dataset...
Building vocab...
მარტივი RNN კლასიფიკატორი
მარტივი RNN-ის შემთხვევაში, ყოველი განმეორებადი ერთეული არის მარტივი წრფივი ქსელი, რომელიც იღებს შეერთებულ შეყვანის ვექტორს და მდგომარეობის ვექტორს და აწარმოებს ახალ მდგომარეობის ვექტორს. PyTorch წარმოადგენს ამ ერთეულს RNNCell კლასით, ხოლო ასეთი უჯრედების ქსელებს RNN ფენით.
RNN კლასიფიკატორის განსასაზღვრად, ჩვენ ჯერ გამოვიყენებთ ჩაშენების ფენას შეყვანის ლექსიკის განზომილების შესამცირებლად, შემდეგ კი მის თავზე გვაქვს RNN ფენა:
იტვირთება…შენიშვნა: ჩვენ ვიყენებთ დაუვარჯიშებელ ჩაშენების ფენას სიმარტივისთვის, მაგრამ კიდევ უკეთესი შედეგისთვის შეგვიძლია გამოვიყენოთ წინასწარ გაწვრთნილი ჩაშენების ფენა Word2Vec ან GloVe ჩაშენებით, როგორც ეს აღწერილია წინა განყოფილებაში. უკეთესი გაგებისთვის, შეიძლება დაგჭირდეთ ამ კოდის ადაპტირება წინასწარ მომზადებულ ჩაშენებებთან მუშაობისთვის.
ჩვენს შემთხვევაში, ჩვენ გამოვიყენებთ padded data loader-ს, ასე რომ, თითოეულ პარტიას ექნება იმავე სიგრძის შეფუთული თანმიმდევრობა. RNN ფენა მიიღებს ტენსორების ჩაშენების თანმიმდევრობას და გამოიმუშავებს ორ გამოსავალს:
- $x$ არის RNN უჯრედის გამომავალი თანმიმდევრობა თითოეულ საფეხურზე
- $h$ არის საბოლოო დამალული მდგომარეობა მიმდევრობის ბოლო ელემენტისთვის
შემდეგ ჩვენ ვიყენებთ სრულად დაკავშირებულ ხაზოვან კლასიფიკატორს კლასის რაოდენობის მისაღებად.
შენიშვნა: RNN-ების მომზადება საკმაოდ რთულია, რადგან როგორც კი RNN უჯრედები გაიხსნება თანმიმდევრობის სიგრძის გასწვრივ, შედეგად მიღებული ფენების რაოდენობა, რომლებიც მონაწილეობენ უკანა გამრავლებაში, საკმაოდ დიდია. ამრიგად, ჩვენ უნდა ავირჩიოთ სწავლის მცირე სიჩქარე და ვავარჯიშოთ ქსელი უფრო დიდ მონაცემთა ბაზაზე, რათა მივიღოთ კარგი შედეგები. ამას შეიძლება საკმაოდ დიდი დრო დასჭირდეს, ამიტომ სასურველია GPU-ს გამოყენება.
იტვირთება…გამოტანა
3200: acc=0.3090625
6400: acc=0.38921875
9600: acc=0.4590625
12800: acc=0.511953125
16000: acc=0.5506875
19200: acc=0.57921875
22400: acc=0.6070089285714285
25600: acc=0.6304296875
28800: acc=0.6484027777777778
32000: acc=0.66509375
35200: acc=0.6790056818181818
38400: acc=0.6929166666666666
41600: acc=0.7035817307692308
44800: acc=0.7137276785714286
48000: acc=0.72225
51200: acc=0.73001953125
54400: acc=0.7372794117647059
57600: acc=0.7436631944444444
60800: acc=0.7503947368421052
64000: acc=0.75634375
67200: acc=0.7615773809523809
70400: acc=0.7662642045454545
73600: acc=0.7708423913043478
76800: acc=0.7751822916666666
80000: acc=0.7790625
83200: acc=0.7825
86400: acc=0.7858564814814815
89600: acc=0.7890513392857142
92800: acc=0.7920474137931034
96000: acc=0.7952708333333334
99200: acc=0.7982258064516129
102400: acc=0.80099609375
105600: acc=0.8037594696969697
108800: acc=0.8060569852941176
გრძელვადიანი მოკლევადიანი მეხსიერება (LSTM)
კლასიკური RNN-ების ერთ-ერთი მთავარი პრობლემა არის ეგრეთ წოდებული გაქრობის გრადიენტების პრობლემა. იმის გამო, რომ RNN-ები გაწვრთნილნი არიან თავიდან ბოლომდე ერთი უკუღმა გავრცელების უღელტეხილზე, მას უჭირს შეცდომის გავრცელება ქსელის პირველ ფენებში და, შესაბამისად, ქსელი ვერ ისწავლის ურთიერთობას შორეულ ტოკენებს შორის. ამ პრობლემის თავიდან აცილების ერთ-ერთი გზააექსპლიციტური სახელმწიფო მენეჯმენტისდანერგვა ე.წ.კარიბჭეებისგამოყენებით. ამ ტიპის ორი ყველაზე ცნობილი არქიტექტურა არსებობს:გრძელვადიანი მოკლევადიანი მეხსიერება(LSTM) დაკარით სარელეო ერთეული(GRU).

LSTM ქსელი ორგანიზებულია RNN-ის მსგავსად, მაგრამ არის ორი მდგომარეობა, რომელიც გადადის ფენიდან ფენაზე: ფაქტობრივი მდგომარეობა $c$ და ფარული ვექტორი $h$. თითოეულ ერთეულზე, ფარული ვექტორი $h_i$ არის შერწყმული $x_i$ შეყვანით და ისინი აკონტროლებენ რა მოუვა $c$ მდგომარეობასკარიბჭის საშუალებით. თითოეული კარიბჭე არის ნერვული ქსელი სიგმოიდური აქტივაციით (გამომავალი $[0,1]$ დიაპაზონში), რომელიც შეიძლება ჩაითვალოს ბიტიურ ნიღბად, როდესაც მრავლდება მდგომარეობის ვექტორზე. არის შემდეგი კარიბჭე (მარცხნიდან მარჯვნივ ზემოთ სურათზე):
- forget gate იღებს დამალულ ვექტორს და ადგენს $c$ ვექტორის რომელი კომპონენტები უნდა დავივიწყოთ და რომელი გავიაროთ.
- შეყვანის კარიბჭე იღებს გარკვეულ ინფორმაციას შეყვანისა და ფარული ვექტორიდან და აყენებს მას მდგომარეობაში.
- გამომავალი კარიბჭე გარდაქმნის მდგომარეობას ზოგიერთი წრფივი შრის მეშვეობით $\tanh$ გააქტიურებით, შემდეგ ირჩევს მის ზოგიერთ კომპონენტს ფარული ვექტორის გამოყენებით $h_i$ ახალი $c_{i+1}$ მდგომარეობის შესაქმნელად.
$c$ სახელმწიფოს კომპონენტები შეიძლება ჩაითვალოს როგორც დროშები, რომლებიც შეიძლება ჩართოთ და გამორთოთ. მაგალითად, როდესაც თანმიმდევრობაში ვხვდებით სახელს ალისა, შეიძლება გვინდოდეს ვივარაუდოთ, რომ ეს ეხება ქალის პერსონაჟს და ავწიოთ დროშა იმ მდგომარეობაში, რომ წინადადებაში გვაქვს ქალის არსებითი სახელი. როდესაც შემდგომ ვხვდებით ფრაზებს and Tom, ჩვენ ავწევთ დროშას, რომელიც გვაქვს მრავლობითი არსებითი სახელი. ამრიგად, მდგომარეობით მანიპულირებით, ჩვენ შეგვიძლია ვივარაუდოთ წინადადების ნაწილების გრამატიკულ თვისებებზე.
შენიშვნა: LSTM-ის შინაგანი გაგებისთვის შესანიშნავი რესურსია ეს შესანიშნავი სტატია LSTM ქსელების გაგება კრისტოფერ ოლაჰის მიერ.
მიუხედავად იმისა, რომ LSTM უჯრედის შიდა სტრუქტურა შეიძლება რთულად გამოიყურებოდეს, PyTorch მალავს ამ განხორციელებას LSTMCell კლასში და უზრუნველყოფს LSTM ობიექტს მთელი LSTM ფენის წარმოსადგენად. ამრიგად, LSTM კლასიფიკატორის დანერგვა საკმაოდ ჰგავს მარტივ RNN-ს, რომელიც ზემოთ ვნახეთ:
იტვირთება…ახლა მოდით ვავარჯიშოთ ჩვენი ქსელი. გაითვალისწინეთ, რომ LSTM ვარჯიში ასევე საკმაოდ ნელია და შესაძლოა, ვარჯიშის დასაწყისში სიზუსტე დიდად არ გაზარდოთ. ასევე, შეიძლება დაგჭირდეთ lr სწავლის სიჩქარის პარამეტრით თამაში, რათა იპოვოთ სწავლის სიჩქარე, რომელიც იწვევს ვარჯიშის გონივრულ სიჩქარეს და, თუმცა, მეხსიერების დაკარგვას.
იტვირთება…გამოტანა
3200: acc=0.259375
6400: acc=0.25859375
9600: acc=0.26177083333333334
12800: acc=0.2784375
16000: acc=0.313
19200: acc=0.3528645833333333
22400: acc=0.3965625
25600: acc=0.4385546875
28800: acc=0.4752777777777778
32000: acc=0.505375
35200: acc=0.5326704545454546
38400: acc=0.5557552083333334
41600: acc=0.5760817307692307
44800: acc=0.5954910714285714
48000: acc=0.6118333333333333
51200: acc=0.62681640625
54400: acc=0.6404779411764706
57600: acc=0.6520138888888889
60800: acc=0.662828947368421
64000: acc=0.673546875
67200: acc=0.6831547619047619
70400: acc=0.6917897727272727
73600: acc=0.6997146739130434
76800: acc=0.707109375
80000: acc=0.714075
83200: acc=0.7209134615384616
86400: acc=0.727037037037037
89600: acc=0.7326674107142858
92800: acc=0.7379633620689655
96000: acc=0.7433645833333333
99200: acc=0.7479032258064516
102400: acc=0.752119140625
105600: acc=0.7562405303030303
108800: acc=0.76015625
112000: acc=0.7641339285714286
115200: acc=0.7677777777777778
118400: acc=0.7711233108108108
(0.03487814127604167, 0.7728)შეფუთული თანმიმდევრობა
ჩვენს მაგალითში, ჩვენ უნდა ჩავსვათ ყველა თანმიმდევრობა მინიჯგუფში ნულოვანი ვექტორებით. მიუხედავად იმისა, რომ ეს იწვევს მეხსიერების გარკვეულ ნარჩენებს, RNN-ებთან ერთად უფრო მნიშვნელოვანია, რომ შეიქმნას დამატებითი RNN უჯრედები შეფუთული შეყვანის ელემენტებისთვის, რომლებიც მონაწილეობენ ტრენინგში, მაგრამ არ ატარებენ რაიმე მნიშვნელოვან შეყვანის ინფორმაციას. ბევრად უკეთესი იქნებოდა RNN-ის მომზადება მხოლოდ რეალური თანმიმდევრობის ზომამდე.
ამისათვის PyTorch-ში დაინერგა დატენილი თანმიმდევრობის შენახვის სპეციალური ფორმატი. დავუშვათ, რომ ჩვენ გვაქვს შეყვანილი მინი პარტია, რომელიც ასე გამოიყურება:[[1,2,3,4,5], [6,7,8,0,0], [9,0,0,0,0]]აქ 0 წარმოადგენს შეფუთულ მნიშვნელობებს, ხოლო შეყვანის თანმიმდევრობების რეალური სიგრძის ვექტორი არის [5,3,1].
იმისათვის, რომ ეფექტურად ვავარჯიშოთ RNN შეფუთული თანმიმდევრობით, ჩვენ გვინდა დავიწყოთ RNN უჯრედების პირველი ჯგუფის ვარჯიში დიდი მინი პარტიით ([1,6,9]), მაგრამ შემდეგ დავასრულოთ მესამე მიმდევრობის დამუშავება და გავაგრძელოთ ვარჯიში მოკლე მინი პარტიებით ([2,7], [3,8]) და ა.შ. ამრიგად, შეფუთული თანმიმდევრობა წარმოდგენილია როგორც ერთი ვექტორი - ჩვენს შემთხვევაში [1,6,9,2,7,3,8,4,5] და სიგრძის ვექტორი ([5,3,1]), საიდანაც ჩვენ შეგვიძლია მარტივად აღვადგინოთ ორიგინალური შეფუთული მინი პარტია.
შეფუთული თანმიმდევრობის შესაქმნელად, ჩვენ შეგვიძლია გამოვიყენოთ torch.nn.utils.rnn.pack_padded_sequence ფუნქცია. ყველა განმეორებადი ფენა, მათ შორის RNN, LSTM და GRU, მხარს უჭერს შეფუთულ მიმდევრობებს, როგორც შეყვანას და აწარმოებს შეფუთულ გამომავალს, რომლის გაშიფვრა შესაძლებელია torch.nn.utils.rnn.pad_packed_sequence-ის გამოყენებით.
იმისათვის, რომ შევძლოთ შეფუთული თანმიმდევრობის გამომუშავება, ჩვენ უნდა გადავიტანოთ სიგრძის ვექტორი ქსელში და, შესაბამისად, გვჭირდება განსხვავებული ფუნქცია მინი პარტიების მოსამზადებლად:
იტვირთება…ფაქტობრივი ქსელი ძალიან წააგავს LSTMClassifier-ს ზემოთ, მაგრამ forward საშვი მიიღებს როგორც შეფუთულ მინი პარტიას, ასევე მიმდევრობის სიგრძის ვექტორს. ჩაშენების გამოთვლის შემდეგ, ჩვენ ვიანგარიშებთ შეფუთულ თანმიმდევრობას, გადავცემთ მას LSTM ფენას და შემდეგ ხსნის შედეგს უკან.
შენიშვნა: ჩვენ რეალურად არ ვიყენებთ შეფუთულ შედეგს
x, რადგან ვიყენებთ გამომავალს ფარული ფენებიდან შემდეგ გამოთვლებში. ამრიგად, ჩვენ შეგვიძლია ამ კოდიდან საერთოდ ამოიღოთ შეფუთვა. მიზეზი იმისა, რომ ჩვენ მას აქ ვათავსებთ, არის ის, რომ თქვენ შეძლოთ ამ კოდის მარტივად შეცვლა, იმ შემთხვევაში, თუ დაგჭირდებათ ქსელის გამომავალი გამოყენება შემდგომ გამოთვლებში.
იტვირთება…ახლა ჩავატაროთ ტრენინგი:
იტვირთება…გამოტანა
3200: acc=0.285625
6400: acc=0.33359375
9600: acc=0.3876041666666667
12800: acc=0.44078125
16000: acc=0.4825
19200: acc=0.5235416666666667
22400: acc=0.5559821428571429
25600: acc=0.58609375
28800: acc=0.6116666666666667
32000: acc=0.63340625
35200: acc=0.6525284090909091
38400: acc=0.668515625
41600: acc=0.6822596153846154
44800: acc=0.6948214285714286
48000: acc=0.7052708333333333
51200: acc=0.71521484375
54400: acc=0.7239889705882353
57600: acc=0.7315277777777778
60800: acc=0.7388486842105263
64000: acc=0.74571875
67200: acc=0.7518303571428572
70400: acc=0.7576988636363636
73600: acc=0.7628940217391305
76800: acc=0.7681510416666667
80000: acc=0.7728125
83200: acc=0.7772235576923077
86400: acc=0.7815393518518519
89600: acc=0.7857700892857142
92800: acc=0.7895043103448276
96000: acc=0.7930520833333333
99200: acc=0.7959072580645161
102400: acc=0.798994140625
105600: acc=0.802064393939394
108800: acc=0.8051378676470589
112000: acc=0.8077857142857143
115200: acc=0.8104600694444445
118400: acc=0.8128293918918919
(0.029785829671223958, 0.8138166666666666)შენიშვნა: თქვენ შეიძლება შეამჩნიეთ პარამეტრი
use_pack_sequence, რომელსაც გადავცემთ ტრენინგის ფუნქციას. ამჟამად,pack_padded_sequenceფუნქცია მოითხოვს, რომ სიგრძის მიმდევრობის ტენსორი იყოს CPU მოწყობილობაზე და, შესაბამისად, სასწავლო ფუნქციამ უნდა თავიდან აიცილოს სიგრძის თანმიმდევრობის მონაცემების GPU-ზე გადატანა ვარჯიშის დროს. შეგიძლიათ იხილოთtrain_embფუნქციის განხორციელებაtorchnlp.pyფაილში.
ორმხრივი და მრავალშრიანი RNN
ჩვენს მაგალითებში, ყველა განმეორებადი ქსელი მოქმედებდა ერთი მიმართულებით, მიმდევრობის დასაწყისიდან ბოლომდე. ბუნებრივად გამოიყურება, რადგან წააგავს სიტყვის კითხვისა და მოსმენის ხერხს. თუმცა, რადგან ბევრ პრაქტიკულ შემთხვევაში გვაქვს შემთხვევითი წვდომა შეყვანის თანმიმდევრობაზე, შეიძლება აზრი ჰქონდეს განმეორებითი გამოთვლების გაშვებას ორივე მიმართულებით. ასეთ ქსელებს უწოდებენ ორმხრივი RNN-ებს და მათი შექმნა შესაძლებელია bidirectional=True პარამეტრის RNN/LSTM/GRU კონსტრუქტორზე გადაცემით.
როდესაც საქმე გვაქვს ორმხრივ ქსელთან, დაგვჭირდება ორი ფარული მდგომარეობის ვექტორი, თითო თითოეული მიმართულებისთვის. PyTorch დაშიფვრავს ამ ვექტორებს, როგორც ორჯერ უფრო დიდი ზომის ერთ ვექტორს, რაც საკმაოდ მოსახერხებელია, რადგან თქვენ ჩვეულებრივ გადასცემდით მიღებულ დამალულ მდგომარეობას სრულად დაკავშირებულ ხაზოვან ფენას და თქვენ უბრალოდ უნდა გაითვალისწინოთ ზომის ეს ზრდა ფენის შექმნისას.
განმეორებადი ქსელი, ცალმხრივი ან ორმხრივი, იჭერს გარკვეულ შაბლონებს მიმდევრობის ფარგლებში და შეუძლია შეინახოს ისინი სახელმწიფო ვექტორში ან გადავიდეს გამოსავალში. როგორც კონვოლუციური ქსელების შემთხვევაში, ჩვენ შეგვიძლია ავაშენოთ კიდევ ერთი განმეორებადი ფენა პირველის თავზე უფრო მაღალი დონის შაბლონების გადასაღებად, ავაშენოთ დაბალი დონის შაბლონებიდან, რომლებიც ამოღებულია პირველი ფენით. ეს მიგვიყვანს მრავალფენიანი RNN-ის ცნებამდე, რომელიც შედგება ორი ან მეტი განმეორებადი ქსელისაგან, სადაც წინა ფენის გამომავალი გადაეცემა შემდეგ ფენას, როგორც შეყვანა.
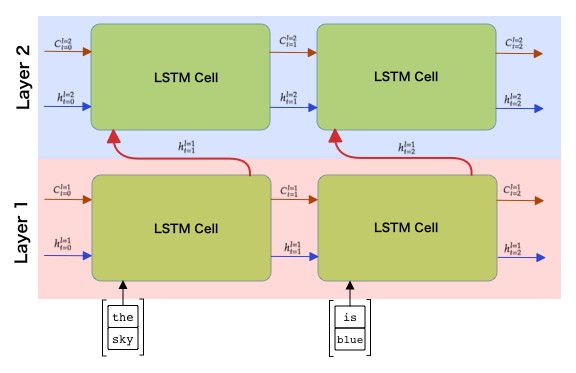
სურათი ეს მშვენიერი პოსტი-დან ფერნანდო ლოპესიდან
PyTorch ხდის ასეთი ქსელების მშენებლობას მარტივ ამოცანას, რადგან თქვენ უბრალოდ უნდა გადასცეთ num_layers პარამეტრი RNN/LSTM/GRU კონსტრუქტორს, რათა ავტომატურად ააშენოთ განმეორების რამდენიმე ფენა. ეს ასევე ნიშნავს, რომ ფარული/მდგომარეობის ვექტორის ზომა პროპორციულად გაიზრდება და თქვენ უნდა გაითვალისწინოთ ეს განმეორებადი ფენების გამომავალი დამუშავებისას.
RNN სხვა ამოცანებისთვის
ამ ერთეულში, ჩვენ ვნახეთ, რომ RNN-ები შეიძლება გამოვიყენოთ თანმიმდევრობის კლასიფიკაციისთვის, მაგრამ სინამდვილეში, მათ შეუძლიათ მრავალი სხვა ამოცანის შესრულება, როგორიცაა ტექსტის შექმნა, მანქანური თარგმანი და სხვა. ამ ამოცანებს განვიხილავთ შემდეგ განყოფილებაში.