განმეორებადი ნერვული ქსელები (RNN) და მათი დახურული უჯრედების ვარიანტები, როგორიცაა გრძელვადიანი მოკლევადიანი მეხსიერების უჯრედები (LSTM) და დახურული განმეორებადი ერთეულები (GRU) უზრუნველყოფდნენ ენის მოდელირების მექანიზმს, ანუ მათ შეუძლიათ ისწავლონ სიტყვების დალაგება და შემდეგი სიტყვის პროგნოზირება თანმიმდევრობით. ეს გვაძლევს საშუალებას გამოვიყენოთ RNN-ები გენერაციული ამოცანებისთვის, როგორიცაა ჩვეულებრივი ტექსტის გენერირება, მანქანური თარგმანი და სურათის წარწერაც კი.
RNN არქიტექტურაში, რომელიც განვიხილეთ წინა ერთეულში, თითოეული RNN ერთეული წარმოქმნის შემდეგ ფარულ მდგომარეობას, როგორც გამომავალს. თუმცა, ჩვენ ასევე შეგვიძლია დავამატოთ კიდევ ერთი გამომავალი თითოეულ განმეორებად ერთეულს, რომელიც მოგვცემს საშუალებას გამოვიტანოთ მიმდევრობა (რომელიც სიგრძით უდრის თავდაპირველ მიმდევრობას). უფრო მეტიც, ჩვენ შეგვიძლია გამოვიყენოთ RNN ერთეულები, რომლებიც არ იღებენ შეყვანას ყოველ საფეხურზე და უბრალოდ ავიღოთ საწყისი მდგომარეობის ვექტორი და შემდეგ გამოვიტანოთ გამომავლების თანმიმდევრობა.
ამ რვეულში ჩვენ ყურადღებას გავამახვილებთ მარტივ გენერაციულ მოდელებზე, რომლებიც დაგვეხმარება ტექსტის გენერირებაში. სიმარტივისთვის, მოდით ავაშენოთ სიმბოლოების დონის ქსელი, რომელიც ასო-ასო ტექსტს წარმოქმნის. ტრენინგის დროს ჩვენ უნდა ავიღოთ ტექსტის კორპუსი და დავყოთ ასოების თანმიმდევრობად.
იტვირთება…გამოტანა
Loading dataset...
Building vocab...
პერსონაჟების ლექსიკის აგება
სიმბოლოების დონის გენერაციული ქსელის ასაშენებლად, ჩვენ უნდა დავყოთ ტექსტი ცალკეულ სიმბოლოებად სიტყვების ნაცვლად. ეს შეიძლება გაკეთდეს სხვა ტოკენიზატორის განსაზღვრით:
იტვირთება…გამოტანა
Vocabulary size = 82
Encoding of 'a' is 1
Character with code 13 is c
ვნახოთ მაგალითი იმისა, თუ როგორ შეგვიძლია დაშიფროთ ტექსტი ჩვენი მონაცემთა ნაკრებიდან:
იტვირთება…გამოტანა
tensor([ 0, 1, 2, 2, 3, 4, 5, 6, 3, 7, 8, 1, 9, 10, 3, 11, 2, 1,
12, 3, 7, 1, 13, 14, 3, 15, 16, 5, 17, 3, 5, 18, 8, 3, 7, 2,
1, 13, 14, 3, 19, 20, 8, 21, 5, 8, 9, 10, 22, 3, 20, 8, 21, 5,
8, 9, 10, 3, 23, 3, 4, 18, 17, 9, 5, 23, 10, 8, 2, 2, 8, 9,
10, 24, 3, 0, 1, 2, 2, 3, 4, 5, 9, 8, 8, 5, 25, 10, 3, 26,
12, 27, 16, 26, 2, 27, 16, 28, 29, 30, 1, 16, 26, 3, 17, 31, 3, 21,
2, 5, 9, 1, 23, 13, 32, 16, 27, 13, 10, 24, 3, 1, 9, 8, 3, 10,
8, 8, 27, 16, 28, 3, 28, 9, 8, 8, 16, 3, 1, 28, 1, 27, 16, 6])გენერაციული RNN-ის ტრენინგი
გზა ჩვენ მოვამზადებთ RNN ტექსტის გენერირებას შემდეგია. თითოეულ საფეხურზე ჩვენ ავიღებთ nchars სიგრძის სიმბოლოების თანმიმდევრობას და ვთხოვთ ქსელს, შექმნას შემდეგი გამომავალი სიმბოლო თითოეული შეყვანის სიმბოლოსთვის:
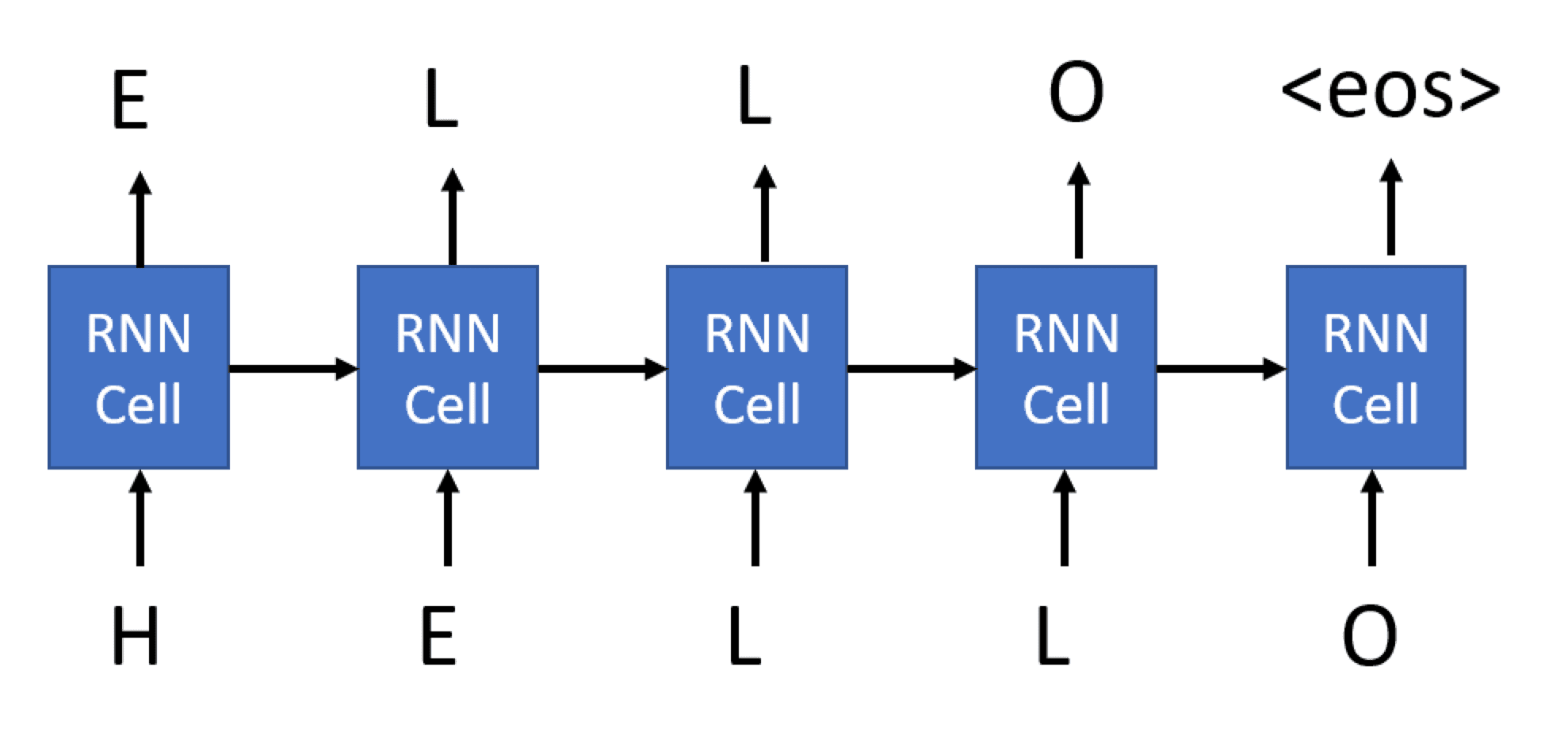
რეალური სცენარიდან გამომდინარე, შეიძლება ასევე გვსურს შევიტანოთ რამდენიმე სპეციალური სიმბოლო, როგორიცაა მიმდევრობის დასასრული <eos>. ჩვენს შემთხვევაში, ჩვენ უბრალოდ გვინდა გავავარჯიშოთ ქსელი გაუთავებელი ტექსტის გენერირებისთვის, რითაც დავაფიქსირებთ თითოეული მიმდევრობის ზომას nchars ტოკენის ტოლი. შესაბამისად, თითოეული ტრენინგის მაგალითი შედგება nchars შეყვანისგან და nchars გამოსავლებისგან (რომლებიც შეყვანის თანმიმდევრობით ერთი სიმბოლოა მარცხნივ გადატანილი). მინი პარტია შედგება რამდენიმე ასეთი თანმიმდევრობისგან.
მინი პარტიების გენერირების ხერხი არის ავიღოთ ყოველი ახალი ამბების ტექსტი l სიგრძით, და შევქმნათ ყველა შესაძლო შეყვანა-გამომავალი კომბინაციები მისგან (იქნება l-nchars ასეთი კომბინაციები). ისინი შექმნიან ერთ მინი პარტიას და მინი პარტიების ზომა განსხვავებული იქნება ყოველი ვარჯიშის ეტაპზე.
იტვირთება…გამოტანა
(tensor([[ 0, 1, 2, ..., 28, 29, 30],
[ 1, 2, 2, ..., 29, 30, 1],
[ 2, 2, 3, ..., 30, 1, 16],
...,
[20, 8, 21, ..., 1, 28, 1],
[ 8, 21, 5, ..., 28, 1, 27],
[21, 5, 8, ..., 1, 27, 16]]),
tensor([[ 1, 2, 2, ..., 29, 30, 1],
[ 2, 2, 3, ..., 30, 1, 16],
[ 2, 3, 4, ..., 1, 16, 26],
...,
[ 8, 21, 5, ..., 28, 1, 27],
[21, 5, 8, ..., 1, 27, 16],
[ 5, 8, 9, ..., 27, 16, 6]]))ახლა მოდით განვსაზღვროთ გენერატორის ქსელი. ის შეიძლება დაფუძნდეს ნებისმიერ მორეციდივე უჯრედზე, რომელიც განვიხილეთ წინა განყოფილებაში (მარტივი, LSTM ან GRU). ჩვენს მაგალითში ჩვენ გამოვიყენებთ LSTM.
იმის გამო, რომ ქსელი იღებს სიმბოლოებს შეყვანის სახით, ხოლო ლექსიკის ზომა საკმაოდ მცირეა, ჩვენ არ გვჭირდება ფენის ჩასმა, one-hot კოდირებული შეყვანა შეიძლება პირდაპირ გადავიდეს LSTM უჯრედში. თუმცა, იმის გამო, რომ სიმბოლოების რიცხვებს შეყვანის სახით გადავცემთ, საჭიროა მათი ერთჯერადი კოდირება LSTM-ზე გადასვლამდე. ეს კეთდება one_hot ფუნქციის გამოძახებით forward უღელტეხილის დროს. გამომავალი ენკოდერი იქნება წრფივი ფენა, რომელიც გადააქცევს დამალულ მდგომარეობას one-hot დაშიფრულ გამოსავალად.
იტვირთება…ტრენინგის დროს გვსურს შეგვეძლოს გენერირებული ტექსტის ნიმუშის აღება. ამისათვის ჩვენ განვსაზღვრავთ generate ფუნქციას, რომელიც გამოიმუშავებს size სიგრძის გამომავალ სტრიქონს, დაწყებული საწყისი სტრიქონიდან start.
მისი მუშაობის გზა შემდეგია. პირველ რიგში, ჩვენ გადავიტანთ მთელ დაწყების სტრიქონს ქსელში და ავიღებთ გამომავალ მდგომარეობას s და შემდეგ პროგნოზირებულ სიმბოლოს out. ვინაიდან out არის ერთჯერადი კოდირებული, ჩვენ ვიღებთ argmax სიმბოლოს nc-ის ინდექსის მისაღებად ლექსიკაში და ვიყენებთ itos რეალური სიმბოლოს გასარკვევად და მივამატებთ მას სიმბოლოების სიაში ____CODE_6. ერთი სიმბოლოს გენერირების პროცესი მეორდება size-ჯერ, სიმბოლოების საჭირო რაოდენობის შესაქმნელად.
იტვირთება…ახლა მოდით გავატაროთ ტრენინგი! სავარჯიშო ციკლი თითქმის იგივეა, რაც ჩვენს ყველა წინა მაგალითში, მაგრამ სიზუსტის ნაცვლად ჩვენ ვბეჭდავთ ნიმუშის გენერირებულ ტექსტს ყოველ 1000 ეპოქაში.
განსაკუთრებული ყურადღება უნდა მიექცეს დანაკარგის გამოთვლას. ჩვენ უნდა გამოვთვალოთ დანაკარგი one-hot კოდირებული გამომავალი out და მოსალოდნელი ტექსტი text_out, რომელიც არის სიმბოლოების ინდექსების სია. საბედნიეროდ, cross_entropy ფუნქცია მოელის ქსელის არანორმალიზებულ გამომავალს, როგორც პირველ არგუმენტს, ხოლო კლასის ნომერს, როგორც მეორეს, რაც ზუსტად ის არის, რაც გვაქვს. ის ასევე ახორციელებს ავტომატურ საშუალოდ გაანგარიშებას მინიპაკეტის ზომაზე.
ჩვენ ასევე ვზღუდავთ ტრენინგს samples_to_train ნიმუშებით, რათა დიდხანს არ დაველოდოთ. ჩვენ მოგიწოდებთ, ექსპერიმენტი ჩაატაროთ და სცადოთ უფრო გრძელი ვარჯიში, შესაძლოა რამდენიმე ეპოქისთვის (ამ შემთხვევაში თქვენ დაგჭირდებათ ამ კოდის გარშემო კიდევ ერთი ციკლის შექმნა).
იტვირთება…გამოტანა
Current loss = 4.398899078369141
today sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr sr s
Current loss = 2.161320447921753
today and to the tor to to the tor to to the tor to to the tor to to the tor to to the tor to to the tor t
Current loss = 1.6722588539123535
today and the court to the could to the could to the could to the could to the could to the could to the c
Current loss = 2.423795223236084
today and a second to the conternation of the conternation of the conternation of the conternation of the
Current loss = 1.702607274055481
today and the company to the company to the company to the company to the company to the company to the co
Current loss = 1.692358136177063
today and the company to the company to the company to the company to the company to the company to the co
Current loss = 1.9722288846969604
today and the control the control the control the control the control the control the control the control
Current loss = 1.8705692291259766
today and the second to the second to the second to the second to the second to the second to the second t
Current loss = 1.7626899480819702
today and a security and a security and a security and a security and a security and a security and a secu
Current loss = 1.5574463605880737
today and the company and the company and the company and the company and the company and the company and
Current loss = 1.5620026588439941
today and the be that the be the be that the be the be that the be the be that the be the be that the be t
ეს მაგალითი უკვე ქმნის საკმაოდ კარგ ტექსტს, მაგრამ მისი შემდგომი გაუმჯობესება შესაძლებელია რამდენიმე გზით:
- უკეთესი მინი პარტია. ტრენინგისთვის მონაცემების მომზადების გზა იყო ერთი ნიმუშიდან ერთი მინი პარტიის გენერირება. ეს არ არის იდეალური, რადგან მინი პარტიები ყველა სხვადასხვა ზომისაა და ზოგიერთი მათგანის გენერირებაც კი შეუძლებელია, რადგან ტექსტი უფრო მცირეა ვიდრე
nchars. ასევე, მცირე მინი პარტიები საკმარისად არ იტვირთება GPU-ს. უფრო გონივრული იქნება, რომ ყველა ნიმუშიდან მივიღოთ ტექსტის ერთი დიდი ნაწილი, შემდეგ შევქმნათ ყველა შემავალი-გამომავალი წყვილი, შევურიოთ ისინი და შევქმნათ თანაბარი ზომის მინი პარტიები. - მრავალშრიანი LSTM. აზრი აქვს სცადოთ LSTM უჯრედების 2 ან 3 ფენა. როგორც წინა განყოფილებაში აღვნიშნეთ, LSTM-ის თითოეული ფენა ამოიღებს გარკვეულ შაბლონებს ტექსტიდან, ხოლო სიმბოლოების დონის გენერატორის შემთხვევაში შეიძლება ველოდოთ, რომ ქვედა LSTM დონე პასუხისმგებელია სილაბების ამოღებაზე, ხოლო უფრო მაღალი დონეები - სიტყვებისა და სიტყვების კომბინაციებისთვის. ეს შეიძლება უბრალოდ განხორციელდეს LSTM კონსტრუქტორზე ფენების რაოდენობის პარამეტრის გადაცემით.
- თქვენ ასევე შეიძლება გინდოდეთ ექსპერიმენტი GRU ერთეულებით და ნახოთ რომელი მათგანი უკეთესად მუშაობს და სხვადასხვა ფარული ფენის ზომები. ძალიან დიდმა დამალულმა ფენამ შეიძლება გამოიწვიოს გადაჭარბება (მაგ. ქსელი ისწავლის ზუსტ ტექსტს), ხოლო მცირე ზომამ შეიძლება არ გამოიწვიოს კარგი შედეგი.
რბილი ტექსტის გენერაცია და ტემპერატურა
generate-ის წინა განმარტებაში, ჩვენ ყოველთვის ვიღებდით სიმბოლოს ყველაზე დიდი ალბათობით, როგორც შემდეგი სიმბოლო გენერირებულ ტექსტში. ამან განაპირობა ის, რომ ტექსტი ხშირად „ტრიალებს“ ერთი და იგივე სიმბოლოების თანმიმდევრობას შორის, როგორც ამ მაგალითში:```
today of the second the company and a second the company ...
იტვირთება…იტვირთება…გამოტანა
--- Temperature = 0.3
Today and a company and complete an all the land the restrational the as a security and has provers the pay to and a report and the computer in the stand has filities and working the law the stations for a company and with the company and the final the first company and refight of the state and and workin
--- Temperature = 0.8
Today he oniis its first to Aus bomblaties the marmation a to manan boogot that pirate assaid a relaid their that goverfin the the Cappets Ecrotional Assonia Cition targets it annight the w scyments Blamity #39;s TVeer Diercheg Reserals fran envyuil that of ster said access what succers of Dour-provelith
--- Temperature = 1.0
Today holy they a 11 will meda a toket subsuaties, engins for Chanos, they's has stainger past to opening orital his thempting new Nattona was al innerforder advan-than #36;s night year his religuled talitatian what the but with Wednesday to Justment will wemen of Mark CCC Camp as Timed Nae wome a leaders
--- Temperature = 1.3
Today gpone 2.5 fech atcusion poor cocles toparsdorM.cht Line Pamage put 43 his calt lowed to the book, that has authh-the silia rruch ailing to'ory andhes beutirsimi- Aefffive heading offil an auf eacklets is charged evis, Gunymy oy) Mony has it after-sloythyor loveId out filme, the Natabl -Najuntaxiggs
--- Temperature = 1.8
Today plary, P.slan chly\401 mardregationly #39;t 8.1Mide) closes ,filtcon alfly playin roven!\grea.-QFBEP: Iss onfarchQ/itilia CCf Zivesigntwasta orce.-Peul-aw.uicrin of fuglinfsut aftaningwo, MIEX awayew Aice Woiduar Corvagiugge oppo esig ThusBratourid canthly-RyI.co lagitems\eexciaishes.conBabntusmor I
ჩვენ შემოვიღეთ კიდევ ერთი პარამეტრი, სახელწოდებით ტემპერატურა, რომელიც გამოიყენება იმის საჩვენებლად, თუ რამდენად უნდა დავიცვათ ყველაზე მაღალი ალბათობა. თუ ტემპერატურა 1.0-ია, ჩვენ ვაკეთებთ სამართლიან მრავალწევრებულ შერჩევას და როდესაც ტემპერატურა მიდის უსასრულობამდე - ყველა ალბათობა თანაბარი ხდება და შემთხვევით ვირჩევთ შემდეგ სიმბოლოს. ქვემოთ მოცემულ მაგალითში შეგვიძლია შევამჩნიოთ, რომ ტექსტი უაზრო ხდება, როდესაც ტემპერატურას ძალიან გავზრდით და ემსგავსება "ციკლურ" მძიმე გენერირებულ ტექსტს, როდესაც ის 0-ს მიუახლოვდება.