სემანტიკური ემბედინგები, როგორიცაა Word2Vec და GloVe, ფაქტობრივად პირველი ნაბიჯია ენის მოდელირებისკენ - მოდელების შექმნა, რომლებიც როგორღაც ესმით (ან წარმოადგენს) ენის ბუნებას.
სალექციო ვიქტორინა
ენის მოდელირების მთავარი იდეა არის მათი სწავლება არალეიბლირებულ მონაცემთა ნაკრებებზე ზედამხედველობის გარეშე. ეს მნიშვნელოვანია, რადგან ჩვენ გვაქვს ხელმისაწვდომი არალეიბლირებული ტექსტის უზარმაზარი რაოდენობა, ხოლო ეტიკეტირებული ტექსტის რაოდენობა ყოველთვის შემოიფარგლება იმ ძალისხმევით, რაც შეგვიძლია დახარჯოთ მარკირებაზე. ყველაზე ხშირად, ჩვენ შეგვიძლია შევქმნათ ენის მოდელები, რომლებსაც შეუძლიათ ტექსტში გამოტოვებული სიტყვების პროგნოზირება, რადგან მარტივია ტექსტში შემთხვევითი სიტყვის შენიღბვა და მისი გამოყენება სასწავლო ნიმუშად.
სასწავლო ემბედინგები
ჩვენს წინა მაგალითებში ჩვენ გამოვიყენეთ წინასწარ გაწვრთნილი სემანტიკური ემბედინგები, მაგრამ საინტერესოა, თუ როგორ შეიძლება ამ ჩაშენების მომზადება. არსებობს რამდენიმე შესაძლო იდეა, რომელთა გამოყენება შესაძლებელია:
- N-Gram ენის მოდელირება, როდესაც ჩვენ ვიწინასწარმეტყველებთ ჟეტონს N წინა ნიშნის (N-გრამი) ნახვით.
- სიტყვების უწყვეტი ჩანთა (CBoW), როდესაც ჩვენ ვიწინასწარმეტყველებთ შუა ნიშანს $W_0$ ნიშნის თანმიმდევრობით $W_{-N}$, ..., $W_N$.
- Skip-gram, სადაც ჩვენ ვიწინასწარმეტყველებთ მომიჯნავე ტოკენების ერთობლიობას {$W_{-N},\dots, W_{-1}, W_1,\dots, W_N$} შუა ტოკენიდან $W_0$.
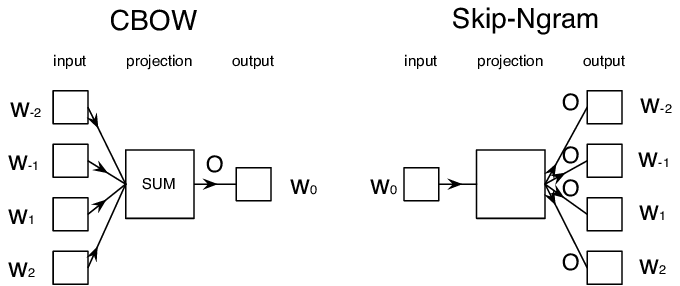
სურათი ეს ქაღალდი-დან
სამაგალითო ნოუთბუქები: სასწავლო CBoW მოდელი
განაგრძეთ სწავლა შემდეგ რვეულებში:
- CBoW Word2Vec-ის სწავლება TensorFlow-ით
- სწავლება CBoW Word2Vec PyTorch-ით
დასკვნა
წინა გაკვეთილზე ვნახეთ, რომ სიტყვების ჩასმა ჯადოსნურად მუშაობს! ახლა ჩვენ ვიცით, რომ სიტყვების ჩაშენების სწავლება არც თუ ისე რთული ამოცანაა და საჭიროების შემთხვევაში უნდა შევძლოთ საკუთარი სიტყვების ჩაშენების მომზადება დომენის კონკრეტული ტექსტისთვის.
ლექციის შემდგომი ვიქტორინა
მიმოხილვა და თვითშესწავლა
- ოფიციალური PyTorch გაკვეთილი ენის მოდელირების შესახებ.
- ოფიციალური TensorFlow გაკვეთილი Word2Vec მოდელის ტრენინგის შესახებ.
- gensim ჩარჩოს გამოყენება ყველაზე ხშირად გამოყენებული ემბედინგების რამდენიმე სტრიქონში კოდის მოსამზადებლად აღწერილია ამ დოკუმენტაციაში.