ეს ნოუთბუქი AI დამწყებთათვის სასწავლო გეგმები-ის ნაწილია. ეწვიეთ საცავს სასწავლო მასალების სრული ნაკრებისთვის.
ნერვული ჩარჩოები
ნერვული ქსელების მომზადების რამდენიმე ჩარჩო არსებობს. თუმცა, თუ გსურთ სწრაფად დაიწყოთ და არ გაეცნოთ ბევრ დეტალს იმის შესახებ, თუ როგორ მუშაობს შინაგანად - უნდა განიხილოთ კერასი-ის გამოყენება. ეს მოკლე გაკვეთილი დაგეხმარებათ და თუ გსურთ უფრო ღრმად გაიგოთ, თუ როგორ მუშაობს ყველაფერი - გადახედეთ ტენსორფლოსა და კერასის შესავალი ნოუთბუქში.
საქმეების მომზადება
Keras არის Tensorflow 2.x ჩარჩოს ნაწილი. მოდით დავრწმუნდეთ, რომ ჩვენ გვაქვს დაინსტალირებული Tensorflow-ის ვერსია 2.x.x:pip install tensorflowან```
conda install tensorflow
იტვირთება…გამოტანა
Tensorflow version = 2.7.0
Keras version = 2.7.0
ძირითადი ცნებები: ტენსორი
Tensor არის მრავალგანზომილებიანი მასივი. ძალიან მოსახერხებელია ტენსორების გამოყენება სხვადასხვა ტიპის მონაცემების წარმოსადგენად:
- 400x400 - შავ-თეთრი სურათი
- 400x400x3 - ფერადი სურათი
- 16x400x400x3 - 16 ფერადი სურათის მინი პარტია
- 25x400x400x3 - ერთი წამი 25-fps ვიდეოდან
- 8x25x400x400x3 - 8 1 წამიანი ვიდეოს მინი პარტია
ტენსორები გვაძლევენ შესავალი/გამომავალი მონაცემების წარმოდგენის მოსახერხებელ გზას, ისევე როგორც ჩვენ ვაწონებთ ნერვულ ქსელში.
პრობლემის ნიმუში
განვიხილოთ ორობითი კლასიფიკაციის პრობლემა. ასეთი პრობლემის კარგი მაგალითი იქნება სიმსივნის კლასიფიკაცია ავთვისებიანსა და კეთილთვისებიანს შორის მისი ზომისა და ასაკის მიხედვით. დავიწყოთ რამდენიმე ნიმუშის მონაცემების გენერირებით:
იტვირთება…იტვირთება…იტვირთება…გამოტანა
C:\Users\dmitryso\AppData\Local\Temp/ipykernel_103052/2721537645.py:17: UserWarning: Matplotlib is currently using module://matplotlib_inline.backend_inline, which is a non-GUI backend, so cannot show the figure.
fig.show()
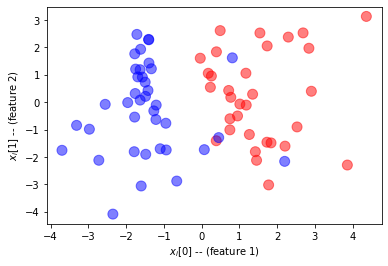
მონაცემთა ნორმალიზება
ვარჯიშის დაწყებამდე ჩვეულებრივია ჩვენი შეყვანის მახასიათებლების [0,1] (ან [-1,1]) სტანდარტულ დიაპაზონში მიყვანა. ამის ზუსტ მიზეზებს მოგვიანებით განვიხილავთ, მაგრამ მოკლედ ამის მიზეზი შემდეგია. ჩვენ გვინდა, რომ ავიცილოთ მნიშვნელობები, რომლებიც მიედინება ჩვენს ქსელში, არ გახდეს ძალიან დიდი ან ძალიან მცირე, და ჩვენ ჩვეულებრივ ვთანხმდებით, რომ ყველა მნიშვნელობა შევინარჩუნოთ მცირე დიაპაზონში 0-თან ახლოს. ამრიგად, ჩვენ ვაყენებთ წონებს მცირე შემთხვევითი რიცხვებით და ვინახავთ სიგნალებს იმავე დიაპაზონში.
მონაცემთა ნორმალიზებისას, ჩვენ უნდა გამოვაკლოთ min მნიშვნელობა და გავყოთ დიაპაზონზე. ჩვენ ვიანგარიშებთ მინიმალურ მნიშვნელობას და დიაპაზონს სასწავლო მონაცემების გამოყენებით, შემდეგ კი ტესტირების/დამოწმების მონაცემთა ნაკრების ნორმალიზებას იგივე მინ/დიაპაზონის მნიშვნელობების გამოყენებით სასწავლო ნაკრებიდან. ეს იმიტომ ხდება, რომ რეალურ ცხოვრებაში ჩვენ ვიცნობთ მხოლოდ სასწავლო კომპლექტს და არა ყველა შემომავალ ახალ მნიშვნელობას, რომლის პროგნოზირებაც ქსელს მოეთხოვება. ხანდახან, ახალი მნიშვნელობა შესაძლოა [0,1] დიაპაზონში აღმოჩნდეს, მაგრამ ეს არ არის გადამწყვეტი.
იტვირთება…სასწავლო ერთი ფენის ქსელი (პერცეპტრონი)
ხშირ შემთხვევაში, ნერვული ქსელი იქნება ფენების თანმიმდევრობა. ის შეიძლება განისაზღვროს Keras-ში Sequential მოდელის გამოყენებით შემდეგი გზით:
იტვირთება…გამოტანა
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 1) 3
activation_1 (Activation) (None, 1) 0
=================================================================
Total params: 3
Trainable params: 3
Non-trainable params: 0
_________________________________________________________________
აქ ჩვენ ჯერ ვქმნით მოდელს და შემდეგ ვამატებთ მას ფენებს:
- პირველი
Inputფენა (რომელიც მკაცრად რომ ვთქვათ არ არის ფენა) შეიცავს ქსელის შეყვანის ზომის სპეციფიკაციას Denseფენა არის რეალური პერცეტრონი, რომელიც შეიცავს სავარჯიშო წონას- და ბოლოს, არის ფენა sigmoid
Activationფუნქციით, რათა მოხდეს ქსელის შედეგი 0-1 დიაპაზონში (იმისთვის, რომ ეს იყოს ალბათობა).
შეყვანის ზომა, ისევე როგორც აქტივაციის ფუნქცია, ასევე შეიძლება განისაზღვროს პირდაპირ Dense ფენაში მოკლედ:
იტვირთება…გამოტანა
Model: "sequential_9"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_9 (Dense) (None, 1) 3
=================================================================
Total params: 3
Trainable params: 3
Non-trainable params: 0
_________________________________________________________________
მოდელის სწავლებამდე საჭიროა შევადგინოთ იგი, რაც არსებითად ნიშნავს დაკონკრეტებას:
- დაკარგვის ფუნქცია, რომელიც განსაზღვრავს ზარალის გამოთვლას. რადგან გვაქვს ორკლასიანი კლასიფიკაციის პრობლემა, გამოვიყენებთ ორობითი ჯვარედინი ენტროპიის დაკარგვას.
- ოპტიმიზატორი გამოსაყენებლად. უმარტივესი ვარიანტი იქნება
sgd-ის გამოყენება სტოქასტური გრადიენტური დაღმართისთვის, ან შეგიძლიათ გამოიყენოთ უფრო დახვეწილი ოპტიმიზატორები, როგორიცააadam. - მეტრიკა, რომელიც გვინდა გამოვიყენოთ ჩვენი ტრენინგის წარმატების გასაზომად. ვინაიდან ეს არის კლასიფიკაციის ამოცანა, კარგი მეტრიკა იქნება
Accuracy(ან მოკლედacc)
ჩვენ შეგვიძლია განვსაზღვროთ დანაკარგი, მეტრიკა და ოპტიმიზატორი ან სტრიქონების სახით, ან Keras-ის ჩარჩოდან ზოგიერთი ობიექტის მიწოდებით. ჩვენს მაგალითში, ჩვენ უნდა მივუთითოთ learning_rate პარამეტრი ჩვენი მოდელის სწავლის სიჩქარის სრულყოფილად დასარეგულირებლად და ამგვარად მივაწოდოთ Keras SGD ოპტიმიზატორის სრული სახელი.
იტვირთება…მოდელის შედგენის შემდეგ, ჩვენ შეგვიძლია გავაკეთოთ ფაქტობრივი ტრენინგი fit მეთოდის გამოძახებით. ყველაზე მნიშვნელოვანი პარამეტრებია:
xდაyმიუთითებენ ტრენინგის მონაცემებს, მახასიათებლებს და ეტიკეტებს შესაბამისად- თუ გვსურს, რომ ვალიდაცია შესრულდეს თითოეულ ეპოქაში, შეგვიძლია მივუთითოთ
validation_dataპარამეტრი, რომელიც იქნება მახასიათებლების და ეტიკეტების წყება epochsდააზუსტა ეპოქების რაოდენობა- თუ გვინდა, რომ ტრენინგი ჩატარდეს მინი პატჩებში, შეგვიძლია მივუთითოთ
batch_sizeპარამეტრი. ასევე შეგიძლიათ წინასწარ შეაგროვოთ მონაცემები ხელით, სანამ გადასცემთx/y/validation_data-ს, ამ შემთხვევაში თქვენ არ გჭირდებათbatch_size
იტვირთება…გამოტანა
Epoch 1/10
70/70 [==============================] - 0s 4ms/step - loss: 0.3379 - acc: 0.9000 - val_loss: 0.3282 - val_acc: 0.9000
Epoch 2/10
70/70 [==============================] - 0s 2ms/step - loss: 0.3270 - acc: 0.9429 - val_loss: 0.3336 - val_acc: 0.9000
Epoch 3/10
70/70 [==============================] - 0s 2ms/step - loss: 0.3195 - acc: 0.9143 - val_loss: 0.3137 - val_acc: 0.9000
Epoch 4/10
70/70 [==============================] - 0s 2ms/step - loss: 0.3087 - acc: 0.9286 - val_loss: 0.2970 - val_acc: 0.9333
Epoch 5/10
70/70 [==============================] - 0s 3ms/step - loss: 0.3006 - acc: 0.9429 - val_loss: 0.3210 - val_acc: 0.9000
Epoch 6/10
70/70 [==============================] - 0s 3ms/step - loss: 0.3003 - acc: 0.9000 - val_loss: 0.2985 - val_acc: 0.9000
Epoch 7/10
70/70 [==============================] - 0s 3ms/step - loss: 0.2956 - acc: 0.9286 - val_loss: 0.3037 - val_acc: 0.9000
Epoch 8/10
70/70 [==============================] - 0s 3ms/step - loss: 0.2891 - acc: 0.9429 - val_loss: 0.3035 - val_acc: 0.9000
Epoch 9/10
70/70 [==============================] - 0s 3ms/step - loss: 0.2809 - acc: 0.9000 - val_loss: 0.2815 - val_acc: 0.9000
Epoch 10/10
70/70 [==============================] - 0s 3ms/step - loss: 0.2809 - acc: 0.9286 - val_loss: 0.2907 - val_acc: 0.9000
<keras.callbacks.History at 0x2c420b89910>შეგიძლიათ სცადოთ ექსპერიმენტი სხვადასხვა ტრენინგის პარამეტრებზე, რათა ნახოთ, როგორ იმოქმედებს ისინი ვარჯიშზე:
batch_size-ის ზედმეტად დიდად დაყენება (ან საერთოდ არ არის მითითებული) შეიძლება გამოიწვიოს ნაკლებად სტაბილური ტრენინგი, რადგან დაბალი განზომილებიანი მონაცემებით, პარტიების მცირე ზომები უზრუნველყოფს გრადიენტის უფრო ზუსტ მიმართულებას თითოეული კონკრეტული შემთხვევისთვის.- ძალიან მაღალმა
learning_rateშეიძლება გამოიწვიოს ზედმეტად მორგება ან ნაკლებად სტაბილური შედეგები, ხოლო სწავლის ძალიან დაბალი მაჩვენებელი ნიშნავს, რომ შედეგის მისაღწევად მეტი ეპოქა დასჭირდება
გაითვალისწინეთ, რომ შეგიძლიათ ზედიზედ რამდენჯერმე გამოიძახოთ
fitფუნქცია ქსელის შემდგომი მომზადებისთვის. თუ გსურთ დაიწყოთ ვარჯიში ნულიდან - საჭიროა ხელახლა გაუშვათ უჯრედი მოდელის განმარტებით.
იმისათვის, რომ დავრწმუნდეთ, რომ ჩვენი ტრენინგი მუშაობდა, მოდით დავხატოთ ხაზი, რომელიც ჰყოფს ორ კლასს. გამოყოფის ხაზი განისაზღვრება განტოლებით $W\ჯერ x + b = 0.5$
იტვირთება…გამოტანა
C:\Users\dmitryso\AppData\Local\Temp/ipykernel_103052/2721537645.py:17: UserWarning: Matplotlib is currently using module://matplotlib_inline.backend_inline, which is a non-GUI backend, so cannot show the figure.
fig.show()
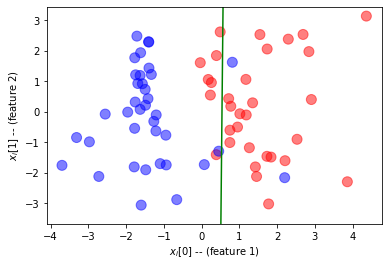
სასწავლო გრაფიკების შედგენა
fit ფუნქცია აბრუნებს history ობიექტს შედეგად, რომელიც შეიძლება გამოყენებულ იქნას დანაკარგების და მეტრიკის დასაკვირვებლად თითოეულ ეპოქაში. ქვემოთ მოცემულ მაგალითში ჩვენ ხელახლა დავიწყებთ ტრენინგს მცირე სწავლის სიჩქარით და დავაკვირდებით, როგორ იქცევა დანაკარგი და სიზუსტე.
გაითვალისწინეთ, რომ ჩვენ ვიყენებთ ოდნავ განსხვავებულ სინტაქსს
Sequentialმოდელის განსაზღვრისთვის. ფენებისadd-ის ნაცვლად სათითაოდ, ჩვენ ასევე შეგვიძლია განვსაზღვროთ შრეების სია პირველ რიგში მოდელის შექმნისას - ეს ცოტა უფრო მოკლე სინტაქსია და თქვენ შეგიძლიათ გამოიყენოთ იგი.
იტვირთება…გამოტანა
Epoch 1/10
70/70 [==============================] - 1s 5ms/step - loss: 0.6600 - acc: 0.6143 - val_loss: 0.6351 - val_acc: 0.8000
Epoch 2/10
70/70 [==============================] - 0s 2ms/step - loss: 0.6384 - acc: 0.7143 - val_loss: 0.6187 - val_acc: 0.8333
Epoch 3/10
70/70 [==============================] - 0s 2ms/step - loss: 0.6188 - acc: 0.7571 - val_loss: 0.6001 - val_acc: 0.8667
Epoch 4/10
70/70 [==============================] - 0s 3ms/step - loss: 0.6022 - acc: 0.7714 - val_loss: 0.5837 - val_acc: 0.9000
Epoch 5/10
70/70 [==============================] - 0s 2ms/step - loss: 0.5860 - acc: 0.8571 - val_loss: 0.5673 - val_acc: 0.9000
Epoch 6/10
70/70 [==============================] - 0s 2ms/step - loss: 0.5702 - acc: 0.8571 - val_loss: 0.5597 - val_acc: 0.8667
Epoch 7/10
70/70 [==============================] - 0s 2ms/step - loss: 0.5568 - acc: 0.8286 - val_loss: 0.5458 - val_acc: 0.9000
Epoch 8/10
70/70 [==============================] - 0s 2ms/step - loss: 0.5430 - acc: 0.8714 - val_loss: 0.5325 - val_acc: 0.9000
Epoch 9/10
70/70 [==============================] - 0s 2ms/step - loss: 0.5308 - acc: 0.8714 - val_loss: 0.5234 - val_acc: 0.9000
Epoch 10/10
70/70 [==============================] - 0s 3ms/step - loss: 0.5175 - acc: 0.9143 - val_loss: 0.5170 - val_acc: 0.8667
იტვირთება…გამოტანა
[<matplotlib.lines.Line2D at 0x2c41a32fe80>]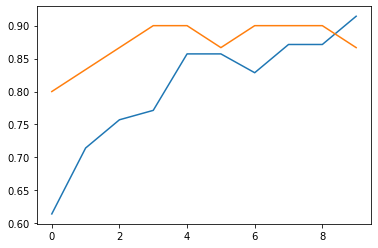
მრავალკლასიანი კლასიფიკაცია
თუ თქვენ გჭირდებათ მრავალკლასიანი კლასიფიკაციის პრობლემის გადაჭრა, თქვენს ქსელს ექნება ერთზე მეტი გამომავალი - $C$ კლასების რაოდენობის შესაბამისი. თითოეული გამომავალი შეიცავს მოცემული კლასის ალბათობას.
გაითვალისწინეთ, რომ თქვენ ასევე შეგიძლიათ გამოიყენოთ ორი გამომავალი ქსელი ორობითი კლასიფიკაციის იმავე წესით შესასრულებლად. ეს არის ზუსტად ის, რასაც ჩვენ ახლა ვამტკიცებთ.
როდესაც თქვენ ველით, რომ ქსელი გამოსცემს ალბათობათა კომპლექტს $p_1,\dots, p_C$, ჩვენ გვჭირდება ყველა მათგანის 1-მდე დამატება. ამის უზრუნველსაყოფად, ჩვენ ვიყენებთ softmax როგორც საბოლოო აქტივაციის ფუნქცია ბოლო ფენაზე. Softmax იღებს ვექტორულ შეყვანას და დარწმუნდება, რომ ამ ვექტორის ყველა კომპონენტი გარდაიქმნება ალბათობებად.
ასევე, რადგან ქსელის გამომავალი არის $C$-განზომილებიანი ვექტორი, ჩვენ გვჭირდება ეტიკეტები, რომ ჰქონდეს იგივე ფორმა. ამის მიღწევა შესაძლებელია one-hot კოდირების გამოყენებით, როდესაც $i$ კლასის რიცხვი გარდაიქმნება ნულების ვექტორად, 1 $i$-ე პოზიციაზე.
ნეირონული ქსელის ალბათობის გამომავალი მოსალოდნელ one-hotი კოდირებულ ლეიბლთან შესადარებლად, ჩვენ ვიყენებთ ჯვარედინი ენტროპიის დაკარგვის ფუნქციას. მას სჭირდება ორი ალბათობის განაწილება და გამოაქვს მნიშვნელობა, თუ რამდენად განსხვავებულია ისინი.
ასე რომ, შევაჯამოთ რა უნდა გავაკეთოთ მრავალკლასიანი კლასიფიკაციისთვის $C$ კლასებით:
- ქსელს უნდა ჰქონდეს $C$ ნეირონები ბოლო ფენაში
- ბოლო გააქტიურების ფუნქცია უნდა იყოს softmax
- დანაკარგი უნდა იყოს ჯვარედინი ენტროპიის დაკარგვა
- ლეიბლები უნდა გადაკეთდეს ერთი ცხელ კოდირებად (ეს შეიძლება გაკეთდეს
numpy-ის გამოყენებით, ან Keras utilsto_categorical-ის გამოყენებით)
იტვირთება…გამოტანა
Epoch 1/10
70/70 [==============================] - 1s 6ms/step - loss: 0.6524 - acc: 0.7000 - val_loss: 0.5936 - val_acc: 0.9000
Epoch 2/10
70/70 [==============================] - 0s 2ms/step - loss: 0.5715 - acc: 0.8286 - val_loss: 0.5255 - val_acc: 0.8333
Epoch 3/10
70/70 [==============================] - 0s 3ms/step - loss: 0.4820 - acc: 0.8714 - val_loss: 0.4213 - val_acc: 0.9000
Epoch 4/10
70/70 [==============================] - 0s 3ms/step - loss: 0.4426 - acc: 0.9000 - val_loss: 0.3694 - val_acc: 0.9333
Epoch 5/10
70/70 [==============================] - 0s 3ms/step - loss: 0.3602 - acc: 0.9000 - val_loss: 0.3454 - val_acc: 0.9000
Epoch 6/10
70/70 [==============================] - 0s 3ms/step - loss: 0.3209 - acc: 0.8857 - val_loss: 0.2862 - val_acc: 0.9333
Epoch 7/10
70/70 [==============================] - 0s 3ms/step - loss: 0.2905 - acc: 0.9286 - val_loss: 0.2787 - val_acc: 0.9000
Epoch 8/10
70/70 [==============================] - 0s 3ms/step - loss: 0.2698 - acc: 0.9000 - val_loss: 0.2381 - val_acc: 0.9333
Epoch 9/10
70/70 [==============================] - 0s 3ms/step - loss: 0.2639 - acc: 0.8857 - val_loss: 0.2217 - val_acc: 0.9667
Epoch 10/10
70/70 [==============================] - 0s 2ms/step - loss: 0.2592 - acc: 0.9286 - val_loss: 0.2391 - val_acc: 0.9000
იშვიათი კატეგორიული ჯვარედინი ენტროპია
ხშირად ეტიკეტები მრავალკლასიან კლასიფიკაციაში წარმოდგენილია კლასის ნომრებით. Keras ასევე მხარს უჭერს სხვა სახის დაკარგვის ფუნქციას, სახელად მწირი კატეგორიული კროსენტროპია, რომელიც მოელის, რომ კლასის რიცხვი იყოს მთელი რიცხვები და არა one-hot ვექტორები. ამ სახის დაკარგვის ფუნქციის გამოყენებით, ჩვენ შეგვიძლია გავამარტივოთ ჩვენი სასწავლო კოდი:
იტვირთება…გამოტანა
Epoch 1/10
70/70 [==============================] - 1s 6ms/step - loss: 0.2353 - acc: 0.9143 - val_loss: 0.2190 - val_acc: 0.9000
Epoch 2/10
70/70 [==============================] - 0s 3ms/step - loss: 0.2243 - acc: 0.9286 - val_loss: 0.1886 - val_acc: 0.9333
Epoch 3/10
70/70 [==============================] - 0s 2ms/step - loss: 0.2366 - acc: 0.9143 - val_loss: 0.2262 - val_acc: 0.9000
Epoch 4/10
70/70 [==============================] - 0s 2ms/step - loss: 0.2259 - acc: 0.9429 - val_loss: 0.2124 - val_acc: 0.9000
Epoch 5/10
70/70 [==============================] - 0s 2ms/step - loss: 0.2061 - acc: 0.9429 - val_loss: 0.2691 - val_acc: 0.9000
Epoch 6/10
70/70 [==============================] - 0s 2ms/step - loss: 0.2200 - acc: 0.9286 - val_loss: 0.2344 - val_acc: 0.9000
Epoch 7/10
70/70 [==============================] - 0s 3ms/step - loss: 0.2133 - acc: 0.9286 - val_loss: 0.1973 - val_acc: 0.9000
Epoch 8/10
70/70 [==============================] - 0s 3ms/step - loss: 0.2062 - acc: 0.9429 - val_loss: 0.1893 - val_acc: 0.9000
Epoch 9/10
70/70 [==============================] - 0s 3ms/step - loss: 0.2060 - acc: 0.9571 - val_loss: 0.2719 - val_acc: 0.9000
Epoch 10/10
70/70 [==============================] - 0s 3ms/step - loss: 0.2021 - acc: 0.9571 - val_loss: 0.2293 - val_acc: 0.9000
<keras.callbacks.History at 0x2c42267de80>მრავალ ეტიკეტის კლასიფიკაცია
ზოგჯერ გვაქვს შემთხვევები, როდესაც ჩვენი ობიექტები შეიძლება მიეკუთვნებოდეს ერთდროულად ორ კლასს. მაგალითად, დავუშვათ, რომ გვსურს შევიმუშავოთ კლასიფიკატორი კატებისა და ძაღლებისთვის სურათზე, მაგრამ ასევე გვინდა დავუშვათ შემთხვევები, როდესაც ორივე კატა და ძაღლი იმყოფება.
მრავალ ეტიკეტიანი კლასიფიკაციით, one-hot კოდირებული ვექტორის ნაცვლად, გვექნება ვექტორი, რომელსაც აქვს 1 პოზიცია, რომელიც შეესაბამება შეყვანის ნიმუშის შესაბამისი ყველა კლასს. ამრიგად, ქსელის გამომავალს არ უნდა ჰქონდეს ნორმალიზებული ალბათობა ყველა კლასისთვის, არამედ თითოეული კლასისთვის ინდივიდუალურად - რაც შეესაბამება sigmoid აქტივაციის ფუნქციის გამოყენებას. ჯვარედინი ენტროპიის დაკარგვა კვლავ შეიძლება გამოყენებულ იქნას როგორც დანაკარგის ფუნქცია.
გაითვალისწინეთ, რომ ეს ძალიან ჰგავს განსხვავებული ნერვული ქსელების გამოყენებას ორობითი კლასიფიკაციის გასაკეთებლად თითოეული კონკრეტული კლასისთვის - მხოლოდ ქსელის საწყისი ნაწილი (კლასიფიკაციის საბოლოო ფენამდე) არის გაზიარებული ყველა კლასისთვის.
კლასიფიკაციის დაკარგვის ფუნქციების შეჯამება
ჩვენ ვნახეთ, რომ ორობითი, მრავალკლასიანი და მრავალ ეტიკეტიანი კლასიფიკაცია განსხვავდება დაკარგვის ფუნქციის ტიპისა და ქსელის ბოლო ფენაზე აქტივაციის ფუნქციის მიხედვით. ეს ყველაფერი შეიძლება ცოტა დამაბნეველი იყოს, თუ ახლახან იწყებთ სწავლას, მაგრამ აქ არის რამდენიმე წესი, რომელიც უნდა გახსოვდეთ:
- თუ ქსელს აქვს ერთი გამომავალი (ორობითი კლასიფიკაცია), ჩვენ ვიყენებთ sigmoid აქტივაციის ფუნქციას, მრავალკლასიანი კლასიფიკაციისთვის - softmax
- თუ გამომავალი კლასი წარმოდგენილია როგორც one-hot კოდირება, დანაკარგის ფუნქცია იქნება ჯვარედინი ენტროპიის დაკარგვა (კატეგორიული ჯვარედინი ენტროპია), თუ გამომავალი შეიცავს კლასის ნომერს - მწირი კატეგორიული ჯვარედინი ენტროპია. ორობითი კლასიფიკაციისთვის - გამოიყენეთ ორობითი ჯვარედინი ენტროპია (იგივე ლოგის დაკარგვა)
- მულტილეიბლიანი კლასიფიკაცია არის ის, როდესაც შეგვიძლია ერთდროულად რამდენიმე კლასს მიეკუთვნოს ობიექტი. ამ შემთხვევაში, ჩვენ გვჭირდება ეტიკეტების დაშიფვრა one-hot კოდირების გამოყენებით და გამოვიყენოთ sigmoid როგორც აქტივაციის ფუნქცია, ისე რომ თითოეული კლასის ალბათობა იყოს 0-დან 1-მდე.
| კლასიფიკაცია | ეტიკეტის ფორმატი | აქტივაციის ფუნქცია | დაკარგვა | |---------------------------------------|---------------|----------| | ორობითი | 1 კლასის ალბათობა | სიგმოიდური | ბინარული კროსენტროპია | | ორობითი | one-hot კოდირება (2 გამომავალი) | softmax | კატეგორიული კროსენტროპია | | მრავალკლასიანი | one-hot კოდირება | softmax | კატეგორიული კროსენტროპია | | მრავალკლასიანი | კლასის ნომერი | softmax | იშვიათი კატეგორიული კროსენტროპია | | მრავალნიშანი | one-hot კოდირება | სიგმოიდური | კატეგორიული კროსენტროპია |
ამოცანა: გამოიყენეთ Keras MNIST ხელნაწერი ციფრების კლასიფიკატორის მოსამზადებლად:
- გაითვალისწინეთ, რომ Keras შეიცავს რამდენიმე სტანდარტულ მონაცემთა ნაკრებს, მათ შორის MNIST. Keras-ის MNIST-ის გამოსაყენებლად საჭიროა მხოლოდ რამდენიმე ხაზი კოდი (დამატებითი ინფორმაცია აქ)
- სცადეთ რამდენიმე ქსელის კონფიგურაცია, სხვადასხვა რაოდენობის ფენებით/ნეირონებით, აქტივაციის ფუნქციებით.
რა არის საუკეთესო სიზუსტე, რისი მიღწევაც შეძელით?
Takeaways
- Keras ნამდვილად რეკომენდირებულია დამწყებთათვის, რადგან ის საშუალებას გაძლევთ შექმნათ ქსელები ფენებიდან საკმაოდ მარტივად და შემდეგ ივარჯიშოთ კოდის რამდენიმე ხაზით.
- თუ არასტანდარტული არქიტექტურა გჭირდებათ, ცოტა უფრო ღრმად უნდა ისწავლოთ Tensorflow. ან შეგიძლიათ სთხოვოთ ვინმეს დანერგოს მორგებული ლოგიკა Keras-ის ფენად და შემდეგ გამოიყენოს იგი Keras-ის მოდელებში
- კარგი იდეაა გადახედოთ PyTorch-საც და შევადაროთ მიდგომები.
კარგი ნიმუში ნოუთბუქის შემქმნელი Keras on Keras და Tensorflow 2.0 შეგიძლიათ იხილოთ აქ.