განმეორებადი ნერვული ქსელები (RNN) და მათი დახურული უჯრედების ვარიანტები, როგორიცაა გრძელვადიანი მოკლევადიანი მეხსიერების უჯრედები (LSTM) და დახურული განმეორებადი ერთეულები (GRU) უზრუნველყოფდნენ ენის მოდელირების მექანიზმს, ანუ მათ შეუძლიათ ისწავლონ სიტყვების დალაგება და შემდეგი სიტყვის პროგნოზირება თანმიმდევრობით. ეს გვაძლევს საშუალებას გამოვიყენოთ RNN-ები გენერაციული ამოცანებისთვის, როგორიცაა ჩვეულებრივი ტექსტის გენერირება, მანქანური თარგმანი და სურათის წარწერაც კი.
RNN არქიტექტურაში, რომელიც განვიხილეთ წინა ერთეულში, თითოეული RNN ერთეული წარმოქმნის შემდეგ ფარულ მდგომარეობას, როგორც გამომავალს. თუმცა, ჩვენ ასევე შეგვიძლია დავამატოთ კიდევ ერთი გამომავალი თითოეულ განმეორებად ერთეულს, რომელიც მოგვცემს საშუალებას გამოვიტანოთ მიმდევრობა (რომელიც სიგრძით უდრის თავდაპირველ მიმდევრობას). უფრო მეტიც, ჩვენ შეგვიძლია გამოვიყენოთ RNN ერთეულები, რომლებიც არ იღებენ შეყვანას ყოველ საფეხურზე და უბრალოდ ავიღოთ საწყისი მდგომარეობის ვექტორი და შემდეგ გამოვიტანოთ გამომავლების თანმიმდევრობა.
ამ რვეულში ჩვენ ყურადღებას გავამახვილებთ მარტივ გენერაციულ მოდელებზე, რომლებიც დაგვეხმარება ტექსტის გენერირებაში. სიმარტივისთვის, მოდით ავაშენოთ სიმბოლოების დონის ქსელი, რომელიც ასო-ასო ტექსტს წარმოქმნის. ტრენინგის დროს ჩვენ უნდა ავიღოთ ტექსტის კორპუსი და დავყოთ ასოების თანმიმდევრობად.
იტვირთება…პერსონაჟების ლექსიკის აგება
სიმბოლოების დონის გენერაციული ქსელის ასაშენებლად, ჩვენ უნდა დავყოთ ტექსტი ცალკეულ სიმბოლოებად სიტყვების ნაცვლად. TextVectorization ფენას, რომელსაც ადრე ვიყენებდით, ამის გაკეთება არ შეუძლია, ამიტომ ჩვენ გვიწევს პარამეტრები:
- ხელით ჩატვირთეთ ტექსტი და გააკეთეთ ტოკენიზაცია „ხელით“, როგორც კერასის ეს ოფიციალური მაგალითი-ში
- გამოიყენეთ
Tokenizerკლასი სიმბოლოების დონის ტოკენიზაციისთვის.
ჩვენ გადავალთ მეორე ვარიანტზე. Tokenizer ასევე შეიძლება გამოყენებულ იქნას სიტყვებად ტოკენიზაციისთვის, ასე რომ თქვენ უნდა შეძლოთ char-დონიდან სიტყვა-დონეზე გადართვა საკმაოდ მარტივად.
სიმბოლოების დონის ტოკენიზაციის გასაკეთებლად, ჩვენ უნდა გადავცეთ char_level=True პარამეტრი:
იტვირთება…ჩვენ ასევე გვინდა გამოვიყენოთ ერთი სპეციალური ტოკენი მიმდევრობის დასასრულის აღსანიშნავად, რომელსაც დავარქმევთ <eos>. მოდით, ხელით დავამატოთ იგი ლექსიკაში:
იტვირთება…ახლა, ტექსტის დაშიფვრად რიცხვების თანმიმდევრობით, შეგვიძლია გამოვიყენოთ:
იტვირთება…გამოტანა
[[48, 2, 10, 10, 5, 44, 1, 25, 5, 8, 10, 13, 78]]გენერაციული RNN-ის სწავლება სათაურების გენერირებისთვის
გზა ჩვენ მოვამზადებთ RNN-ს ახალი ამბების სათაურების გენერირებისთვის შემდეგია. თითოეულ საფეხურზე ჩვენ ავიღებთ ერთ სათაურს, რომელიც შეიტანება RNN-ში და თითოეული შეყვანის სიმბოლოსთვის ვთხოვთ ქსელს შემდეგი გამომავალი სიმბოლოს გენერირებას:
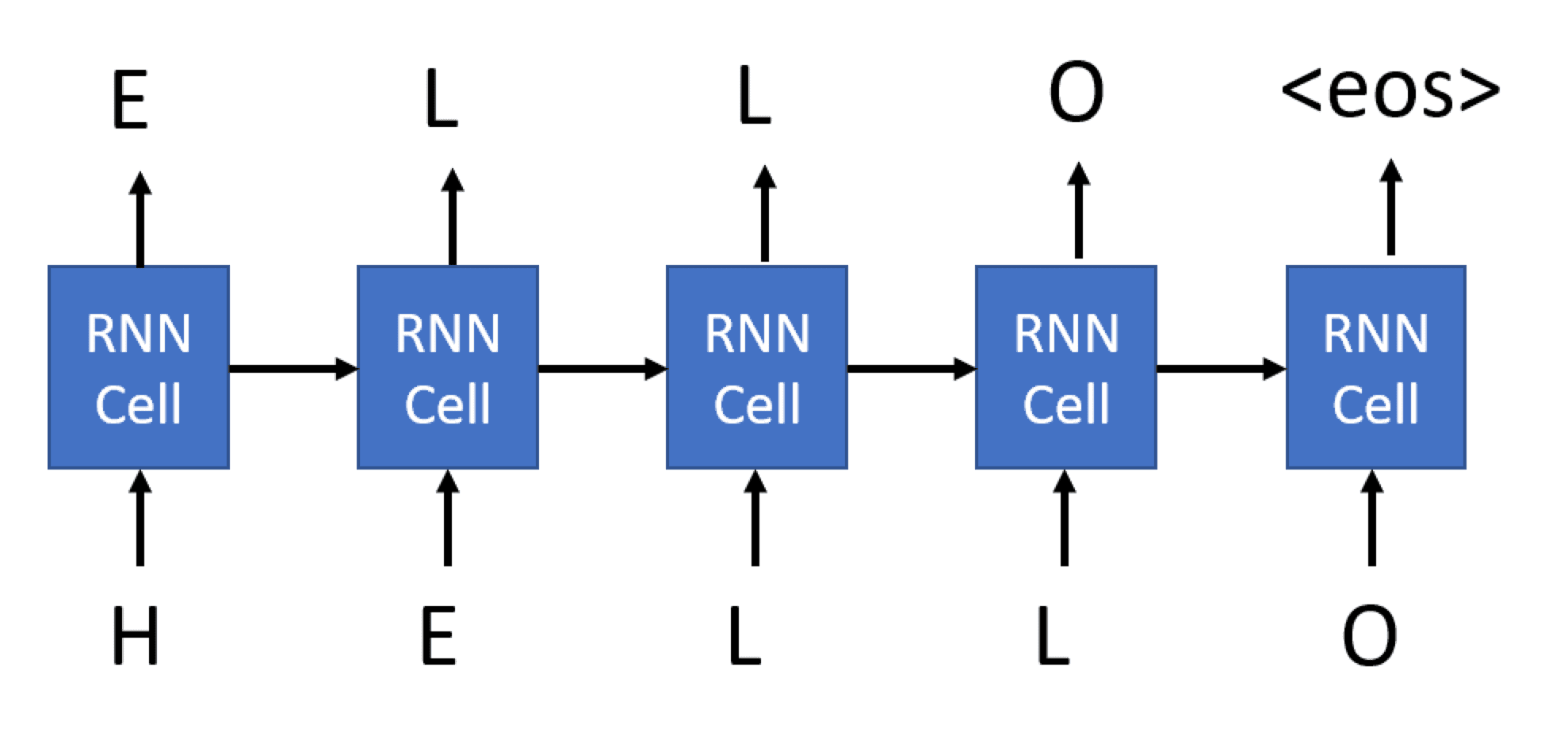
ჩვენი თანმიმდევრობის ბოლო სიმბოლოსთვის, ჩვენ ვთხოვთ ქსელს შექმნას <eos> ტოკენი.
მთავარი განსხვავება გენერაციულ RNN-ს შორის, რომელსაც ჩვენ აქ ვიყენებთ, არის ის, რომ ჩვენ ავიღებთ გამოსავალს RNN-ის თითოეული ნაბიჯიდან და არა მხოლოდ საბოლოო უჯრედიდან. ამის მიღწევა შესაძლებელია RNN უჯრედში return_sequences პარამეტრის მითითებით.
ამრიგად, ტრენინგის დროს, ქსელში შეყვანა იქნება გარკვეული სიგრძის დაშიფრული სიმბოლოების თანმიმდევრობა, ხოლო გამომავალი იქნება იგივე სიგრძის თანმიმდევრობა, მაგრამ გადატანილი ერთი ელემენტით და მთავრდება <eos>-ით. Minibatch შედგება რამდენიმე ასეთი თანმიმდევრობისგან და ჩვენ უნდა გამოვიყენოთ padding ყველა თანმიმდევრობის გასასწორებლად.
მოდით შევქმნათ ფუნქციები, რომლებიც გარდაქმნის მონაცემთა ბაზას ჩვენთვის. იმის გამო, რომ ჩვენ გვსურს მიმდევრობების შევსება მინიჯგუფის დონეზე, ჩვენ ჯერ შევაგროვებთ მონაცემთა ბაზას .batch()-ის გამოძახებით, შემდეგ კი map ტრანსფორმაციის განსახორციელებლად. ამრიგად, ტრანსფორმაციის ფუნქცია პარამეტრად მიიღებს მთელ მინი პარტიას:
იტვირთება…რამდენიმე მნიშვნელოვანი რამ, რასაც ჩვენ აქ ვაკეთებთ:
- ჩვენ პირველად გამოვყოფთ ფაქტობრივ ტექსტს სიმებიანი ტენსორიდან
text_to_sequencesგარდაქმნის სტრიქონების სიას მთელი რიცხვების ტენსორების სიაშიpad_sequencesამაგრებს ამ ტენსორებს მაქსიმალურ სიგრძემდე- ჩვენ საბოლოოდ ერთჯერად ვშიფრავთ ყველა სიმბოლოს, ასევე ვაკეთებთ შეცვლას და
<eos>დამატებას. ჩვენ მალე დავინახავთ, რატომ გვჭირდება one-hot კოდირებული სიმბოლოები
თუმცა, ეს ფუნქცია პითონიკურია, ანუ ის ავტომატურად ვერ გადაითარგმნება Tensorflow-ის გამოთვლით გრაფიკში. ჩვენ მივიღებთ შეცდომებს, თუ შევეცდებით ამ ფუნქციის გამოყენებას პირდაპირ Dataset.map ფუნქციაში. ჩვენ უნდა დავამაგროთ ეს პითონიკური ზარი py_function შეფუთვის გამოყენებით:
იტვირთება…შენიშვნა: Pythonic-ისა და Tensorflow-ის ტრანსფორმაციის ფუნქციებს შორის დიფერენცირება შეიძლება ცოტა ზედმეტად რთული მოგეჩვენოთ და შეიძლება გაგიჩნდეთ კითხვა, რატომ არ ვაქცევთ მონაცემთა ბაზას სტანდარტული Python ფუნქციების გამოყენებით
fit-ზე გადაცემამდე. მიუხედავად იმისა, რომ ეს ნამდვილად შეიძლება გაკეთდეს,Dataset.map-ის გამოყენებას აქვს უზარმაზარი უპირატესობა, რადგან მონაცემთა ტრანსფორმაციის მილსადენი შესრულებულია Tensorflow გამოთვლითი გრაფიკის გამოყენებით, რომელიც იყენებს GPU გამოთვლებს და ამცირებს მონაცემთა გადაცემის საჭიროებას CPU/GPU-ს შორის.
ახლა ჩვენ შეგვიძლია ავაშენოთ ჩვენი გენერატორის ქსელი და დავიწყოთ ტრენინგი. ის შეიძლება დაფუძნდეს ნებისმიერ მორეციდივე უჯრედზე, რომელიც განვიხილეთ წინა განყოფილებაში (მარტივი, LSTM ან GRU). ჩვენს მაგალითში ჩვენ გამოვიყენებთ LSTM.
იმის გამო, რომ ქსელი იღებს სიმბოლოებს შეყვანის სახით და ლექსიკის ზომა საკმაოდ მცირეა, ჩვენ არ გვჭირდება ჩაშენებული ფენა, one-hot კოდირებული შეყვანა შეიძლება პირდაპირ შევიდეს LSTM უჯრედში. გამომავალი ფენა იქნება Dense კლასიფიკატორი, რომელიც გადააქცევს LSTM გამომავალს one-hotი კოდირებულ ნიშნად.
გარდა ამისა, ვინაიდან საქმე გვაქვს ცვლადი სიგრძის თანმიმდევრობებთან, შეგვიძლია გამოვიყენოთ Masking ფენა, რათა შევქმნათ ნიღაბი, რომელიც უგულებელყოფს სტრიქონის დაფარულ ნაწილს. ეს არ არის მკაცრად საჭირო, რადგან ჩვენ დიდად არ გვაინტერესებს ყველაფერი, რაც სცილდება <eos> ნიშანს, მაგრამ ჩვენ მას გამოვიყენებთ ამ ფენის ტიპის გარკვეული გამოცდილების მისაღებად. input_shape იქნება (None, vocab_size), სადაც None მიუთითებს ცვლადი სიგრძის თანმიმდევრობას და გამომავალი ფორმა არის (None,vocab_size) ასევე, როგორც ხედავთ summary-დან:
იტვირთება…გამოტანა
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
masking (Masking) (None, None, 84) 0
_________________________________________________________________
lstm (LSTM) (None, None, 128) 109056
_________________________________________________________________
dense (Dense) (None, None, 84) 10836
=================================================================
Total params: 119,892
Trainable params: 119,892
Non-trainable params: 0
_________________________________________________________________
15000/15000 [==============================] - 229s 15ms/step - loss: 1.5385
<tensorflow.python.keras.callbacks.History at 0x7fa40c1245e0>გამომავალი გენერირება
ახლა, როდესაც ჩვენ მოვამზადეთ მოდელი, გვსურს გამოვიყენოთ ის გარკვეული გამოსავლის გენერირებისთვის. უპირველეს ყოვლისა, ჩვენ გვჭირდება გზა, რათა გაშიფროს ტექსტი, რომელიც წარმოდგენილია სიმბოლური რიცხვების თანმიმდევრობით. ამისათვის ჩვენ შეგვიძლია გამოვიყენოთ tokenizer.sequences_to_texts ფუნქცია; თუმცა, ის კარგად არ მუშაობს პერსონაჟების დონის ტოკენიზაციასთან დაკავშირებით. ამიტომ ჩვენ ავიღებთ ტოკენების ლექსიკონს ტოკენიზატორიდან (ე.წ. word_index), ავაშენებთ საპირისპირო რუკას და დავწერთ ჩვენს დეკოდირების ფუნქციას:
იტვირთება…ახლა, მოდით გავაკეთოთ თაობა. ჩვენ დავიწყებთ ზოგიერთი სტრიქონით start, დაშიფვრით მას თანმიმდევრობით inp, შემდეგ კი ყოველ საფეხურზე მოვუწოდებთ ჩვენს ქსელს შემდეგი სიმბოლოს დასადგენად.
ქსელის გამომავალი out არის vocab_size ელემენტების ვექტორი, რომელიც წარმოადგენს თითოეული ტოკენის ალბათობას და ჩვენ შეგვიძლია ვიპოვოთ ყველაზე სავარაუდო ტოკენის ნომერი argmax-ის გამოყენებით. ჩვენ შემდეგ ვამატებთ ამ სიმბოლოს ტოკენების გენერირებულ სიას და ვაგრძელებთ გენერირებას. ერთი სიმბოლოს გენერირების ეს პროცესი size-ჯერ მეორდება სიმბოლოების საჭირო რაოდენობის შესაქმნელად და ჩვენ ადრე ვწყვეტთ, როდესაც eos_token შეგხვდებათ.
იტვირთება…გამოტანა
'Today #39;s lead to strike for the strike for the strike for the strike (AFP)'შერჩევის შედეგი ტრენინგის დროს
იმის გამო, რომ ჩვენ არ გვაქვს რაიმე სასარგებლო მეტრიკა, როგორიცაა სიზუსტე, ერთადერთი გზა, რითაც შეგვიძლია დავინახოთ, რომ ჩვენი მოდელი უკეთესდება, არის შერჩევის გენერირებული სტრიქონი ტრენინგის დროს. ამისათვის ჩვენ გამოვიყენებთ გამოძახებას, ანუ ფუნქციებს, რომლებიც შეგვიძლია გადავიტანოთ fit ფუნქციაზე და რომლებიც პერიოდულად გამოიძახება ტრენინგის დროს.
იტვირთება…გამოტანა
Epoch 1/3
15000/15000 [==============================] - 226s 15ms/step - loss: 1.2703
Today #39;s a lead in the company for the strike
Epoch 2/3
15000/15000 [==============================] - 227s 15ms/step - loss: 1.2057
Today #39;s the Market Service on Security Start (AP)
Epoch 3/3
15000/15000 [==============================] - 226s 15ms/step - loss: 1.1752
Today #39;s a line on the strike to start for the start
<tensorflow.python.keras.callbacks.History at 0x7fa40c74e3d0>ეს მაგალითი უკვე ქმნის საკმაოდ კარგ ტექსტს, მაგრამ მისი შემდგომი გაუმჯობესება შესაძლებელია რამდენიმე გზით:
- მეტი ტექსტი. ჩვენ მხოლოდ სათაურები გამოვიყენეთ ჩვენი ამოცანისთვის, მაგრამ თქვენ შეგიძლიათ ექსპერიმენტი ჩაატაროთ სრული ტექსტით. გახსოვდეთ, რომ RNN-ები არც თუ ისე კარგია გრძელი მიმდევრობების მართვაში, ამიტომ აზრი აქვს ან დაყოთ ისინი მოკლე წინადადებებად, ან ყოველთვის ივარჯიშოთ გარკვეული წინასწარ განსაზღვრული მნიშვნელობის
num_charsფიქსირებულ მიმდევრობის სიგრძეზე (ვთქვათ, 256). თქვენ შეგიძლიათ სცადოთ შეცვალოთ ზემოთ მოცემული მაგალითი ასეთ არქიტექტურაში, გამოიყენეთ კერასის ოფიციალური გაკვეთილი როგორც შთაგონება. - მრავალშრიანი LSTM. აზრი აქვს სცადოთ LSTM უჯრედების 2 ან 3 ფენა. როგორც წინა განყოფილებაში აღვნიშნეთ, LSTM-ის თითოეული ფენა ამოიღებს გარკვეულ შაბლონებს ტექსტიდან, ხოლო სიმბოლოების დონის გენერატორის შემთხვევაში შეიძლება ველოდოთ, რომ ქვედა LSTM დონე პასუხისმგებელია სილაბების ამოღებაზე, ხოლო უფრო მაღალი დონეები - სიტყვებისა და სიტყვების კომბინაციებისთვის. ეს შეიძლება უბრალოდ განხორციელდეს LSTM კონსტრუქტორზე ფენების რაოდენობის პარამეტრის გადაცემით.
- თქვენ ასევე შეიძლება გინდოდეთ ექსპერიმენტი GRU ერთეულებით და ნახოთ რომელი მათგანი უკეთესად მუშაობს და სხვადასხვა ფარული ფენის ზომები. ძალიან დიდმა დამალულმა ფენამ შეიძლება გამოიწვიოს გადაჭარბება (მაგ. ქსელი ისწავლის ზუსტ ტექსტს), ხოლო მცირე ზომამ შეიძლება არ გამოიწვიოს კარგი შედეგი.
რბილი ტექსტის გენერაცია და ტემპერატურა
generate-ის წინა განმარტებაში, ჩვენ ყოველთვის ვიღებდით სიმბოლოს ყველაზე დიდი ალბათობით, როგორც შემდეგი სიმბოლო გენერირებულ ტექსტში. ამან განაპირობა ის, რომ ტექსტი ხშირად „ტრიალებს“ ერთი და იგივე სიმბოლოების თანმიმდევრობას შორის, როგორც ამ მაგალითში:```
today of the second the company and a second the company ...
იტვირთება…იტვირთება…გამოტანა
--- Temperature = 0.3
Today #39;s strike #39; to start at the store return
On Sunday PO to Be Data Profit Up (Reuters)
Moscow, SP wins straight to the Microsoft #39;s control of the space start
President olding of the blast start for the strike to pay <b>...</b>
Little red riding hood ficed to the spam countered in European <b>...</b>
--- Temperature = 0.8
Today countie strikes ryder missile faces food market blut
On Sunday collores lose-toppy of sale of Bullment in <b>...</b>
Moscow, IBM Diffeiting in Afghan Software Hotels (Reuters)
President Ol Luster for Profit Peaced Raised (AP)
Little red riding hood dace on depart talks #39; bank up
--- Temperature = 1.0
Today wits House buiting debate fixes #39; supervice stake again
On Sunday arling digital poaching In for level
Moscow, DS Up 7, Top Proble Protest Caprey Mamarian Strike
President teps help of roubler stepted lessabul-Dhalitics (AFP)
Little red riding hood signs on cash in Carter-youb
--- Temperature = 1.3
Today wits flawer ro, pSIA figat's co DroftwavesIs Talo up
On Sunday hround elitwing wint EU Powerburlinetien
Moscow, Bazz #39;s sentries olymen winnelds' next for Olympite Huc?
President lost securitys from power Elections in Smiltrials
Little red riding hood vides profit, exponituity, profitmainalist-at said listers
--- Temperature = 1.8
Today #39;It: He deat: N.KA Asside
On Sunday i arry Par aldeup patient Wo stele1
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-33-db32367a0feb> in <module>
18 print(f"\n--- Temperature = {i}")
19 for j in range(5):
---> 20 print(generate_soft(model,size=300,start=words[j],temperature=i))
<ipython-input-33-db32367a0feb> in generate_soft(model, size, start, temperature)
11 chars.append(nc)
12 inp = inp+[nc]
---> 13 return decode(chars)
14
15 words = ['Today ','On Sunday ','Moscow, ','President ','Little red riding hood ']
<ipython-input-10-3f5fa6130b1d> in decode(x)
2
3 def decode(x):
----> 4 return ''.join([reverse_map[t] for t in x])
<ipython-input-10-3f5fa6130b1d> in <listcomp>(.0)
2
3 def decode(x):
----> 4 return ''.join([reverse_map[t] for t in x])
KeyError: 0ჩვენ შემოვიღეთ კიდევ ერთი პარამეტრი, სახელწოდებით ტემპერატურა, რომელიც გამოიყენება იმის საჩვენებლად, თუ რამდენად უნდა დავიცვათ ყველაზე მაღალი ალბათობა. თუ ტემპერატურა 1.0-ია, ჩვენ ვაკეთებთ სამართლიან მრავალწევრებულ შერჩევას და როდესაც ტემპერატურა მიდის უსასრულობამდე - ყველა ალბათობა თანაბარი ხდება და შემთხვევით ვირჩევთ შემდეგ სიმბოლოს. ქვემოთ მოცემულ მაგალითში შეგვიძლია შევამჩნიოთ, რომ ტექსტი უაზრო ხდება, როდესაც ტემპერატურას ძალიან გავზრდით და ემსგავსება "ციკლურ" მძიმე გენერირებულ ტექსტს, როდესაც ის 0-ს მიუახლოვდება.