ეს ნოუთბუქი AI დამწყებთათვის სასწავლო გეგმები-ის ნაწილია. ეწვიეთ საცავს სასწავლო მასალების სრული ნაკრებისთვის.
ნერვული ჩარჩოები
ჩვენ გავიგეთ, რომ ნერვული ქსელების მოსამზადებლად გჭირდებათ:
- სწრაფად გაამრავლეთ მატრიცები (ტენსორები)
- გამოთვალეთ გრადიენტები გრადიენტული წარმოშობის ოპტიმიზაციის შესასრულებლად
რა საშუალებას გაძლევთ გააკეთოთ ნერვული ქსელის ჩარჩოები:
- იმუშავეთ ტენსორებით ნებისმიერ გამოთვლაზე, CPU ან GPU, ან თუნდაც TPU
- გრადიენტების ავტომატური გამოთვლა (ისინი აშკარად დაპროგრამებულია ყველა ჩაშენებული ტენზორული ფუნქციისთვის)
სურვილისამებრ:
- ნერვული ქსელის კონსტრუქტორი / უმაღლესი დონის API (აღწერეთ ქსელი, როგორც ფენების თანმიმდევრობა)
- მარტივი სასწავლო ფუნქციები (
fit, როგორც Scikit Learn-ში) - ოპტიმიზაციის მთელი რიგი ალგორითმები გრადიენტული წარმოშობის გარდა
- მონაცემთა დამუშავების აბსტრაქციები (რომელიც იდეალურად იმუშავებს GPU-ზეც)
ყველაზე პოპულარული ჩარჩოები
- Tensorflow 1.x - პირველი ფართოდ ხელმისაწვდომი ჩარჩო (Google). ნებადართულია განსაზღვროს სტატიკური გამოთვლითი გრაფიკი, დააყენოს იგი GPU-ზე და მკაფიოდ შეაფასოს იგი
- PyTorch - ფეისბუქის ჩარჩო, რომელიც იზრდება პოპულარობით
- Keras - უფრო მაღალი დონის API Tensorflow/PyTorch-ის თავზე ნერვული ქსელების გაერთიანებისა და გამარტივების მიზნით (Francois Chollet)
- Tensorflow 2.x + Keras - Tensorflow-ის ახალი ვერსია ინტეგრირებული Keras ფუნქციონირებით, რომელიც მხარს უჭერს დინამიური გამოთვლის გრაფიკს, რაც საშუალებას გაძლევთ შეასრულოთ ტენზორული ოპერაციები, რომლებიც ძალიან ჰგავს numpy-ს (და PyTorch)
განვიხილავთ Tensorflow 2.x და Keras. დარწმუნდით, რომ დაინსტალირებული გაქვთ Tensorflow-ის ვერსია 2.x.x:pip install tensorflowან```
conda install tensorflow
იტვირთება…გამოტანა
2.7.0
ძირითადი ცნებები: ტენსორი
Tensor არის მრავალგანზომილებიანი მასივი. ძალიან მოსახერხებელია ტენსორების გამოყენება სხვადასხვა ტიპის მონაცემების წარმოსადგენად:
- 400x400 - შავ-თეთრი სურათი
- 400x400x3 - ფერადი სურათი
- 16x400x400x3 - 16 ფერადი სურათის მინი პარტია
- 25x400x400x3 - ერთი წამი 25-fps ვიდეოდან
- 8x25x400x400x3 - 8 1 წამიანი ვიდეოს მინი პარტია
მარტივი ტენსორები
თქვენ შეგიძლიათ მარტივად შექმნათ მარტივი ტენსორები np მასივების სიებიდან, ან შექმნათ შემთხვევითი:
იტვირთება…გამოტანა
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
tf.Tensor(
[[-0.33552304 -1.8252622 -1.8532339 ]
[ 1.0871267 -1.2779568 0.5240014 ]
[-0.12793781 -1.8618349 -0.9020286 ]
[ 0.5948797 0.11144501 -2.0396452 ]
[ 0.47620854 1.1726047 -0.4405675 ]
[-0.27211484 -0.08985762 -0.03376012]
[ 0.64274263 0.53368104 -0.9006528 ]
[-0.43745974 -1.0081122 -0.13442488]
[ 0.36497566 1.3221073 -1.8739727 ]
[ 0.94821155 -0.02817811 1.3563292 ]], shape=(10, 3), dtype=float32)
თქვენ შეგიძლიათ გამოიყენოთ არითმეტიკული მოქმედებები ტენსორებზე, რომლებიც შესრულებულია ელემენტების მიხედვით, როგორც numpy-ში. საჭიროების შემთხვევაში ტენზორები ავტომატურად აფართოებენ საჭირო განზომილებას. ტენსორიდან ნუმპი მასივის ამოსაღებად გამოიყენეთ .numpy():
იტვირთება…გამოტანა
tf.Tensor(
[[ 0. 0. 0. ]
[ 1.4226497 0.54730535 2.3772354 ]
[ 0.20758523 -0.03657269 0.9512053 ]
[ 0.93040276 1.9367073 -0.18641126]
[ 0.8117316 2.9978669 1.4126664 ]
[ 0.0634082 1.7354046 1.8194739 ]
[ 0.97826564 2.3589432 0.9525811 ]
[-0.1019367 0.81715 1.718809 ]
[ 0.7004987 3.1473694 -0.02073872]
[ 1.2837346 1.7970841 3.2095633 ]], shape=(10, 3), dtype=float32)
[0.71496403 0.16117539 0.15672949]
ცვლადები
ცვლადები სასარგებლოა ტენსორული მნიშვნელობების წარმოსაჩენად, რომლებიც შეიძლება შეიცვალოს assign და assign_add გამოყენებით. ისინი ხშირად გამოიყენება ნერვული ქსელის წონის წარმოსაჩენად.
მაგალითად, აქ არის სულელური გზა ტენზორის ყველა მწკრივის ჯამის მისაღებად a:
იტვირთება…გამოტანა
<tf.Variable 'Variable:0' shape=(3,) dtype=float32, numpy=array([ 2.9411097, -2.9513645, -6.2979555], dtype=float32)>
ბევრად უკეთესი გზა ამის გასაკეთებლად:
იტვირთება…გამოტანა
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([ 2.9411097, -2.9513645, -6.2979555], dtype=float32)>გამოთვლითი გრადიენტები
უკანა გამრავლებისთვის საჭიროა გრადიენტების გამოთვლა. ეს კეთდება tf.GradientTape() იდიომის გამოყენებით:
- დაამატეთ
with tf.GradientTapeბლოკი ჩვენი გამოთვლების გარშემო - მონიშნეთ ის ტენსორები, რომლებთან მიმართებაშიც უნდა გამოვთვალოთ გრადიენტები
tape.watch-ის გამოძახებით (ყველა ცვლადი ყურება ავტომატურად ხდება) - გამოვთვალოთ რაც გვჭირდება (გამოთვლითი გრაფიკის შექმნა)
- მიიღეთ გრადიენტები
tape.gradient-ის გამოყენებით
იტვირთება…გამოტანა
tf.Tensor(
[[ 0.40935674 -0.3495818 ]
[ 0.94165146 -0.33209163]], shape=(2, 2), dtype=float32)
მაგალითი 1: ხაზოვანი რეგრესია
ახლა ჩვენ საკმარისი ვიცით წრფივი რეგრესიის კლასიკური ამოცანის გადასაჭრელად. მოდით შევქმნათ მცირე სინთეზური მონაცემთა ნაკრები:
იტვირთება…იტვირთება…გამოტანა
<matplotlib.collections.PathCollection at 0x12892776880>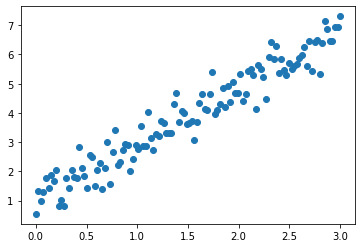
წრფივი რეგრესია განისაზღვრება სწორი ხაზით $f_{W,b}(x) = Wx+b$, სადაც $W, b$ არის მოდელის პარამეტრები, რომლებიც უნდა ვიპოვოთ. შეცდომა ჩვენს მონაცემთა ბაზაში ${x_i,y_u}{i=1}^N$ (ასევე უწოდებენ დაკარგვის ფუნქციას) შეიძლება განისაზღვროს, როგორც საშუალო კვადრატული შეცდომა: $$ \mathcal{L}(W,b) = {1\ მეტი N}\sum{i=1}^N (f_{W,b}(x_i)-y_i)^2 $$
მოდით განვსაზღვროთ ჩვენი მოდელი და დაკარგვის ფუნქცია:
იტვირთება…ჩვენ მოვამზადებთ მოდელს მინი პატჩების სერიაზე. ჩვენ გამოვიყენებთ გრადიენტულ დაშვებას, მოდელის პარამეტრების კორექტირებას შემდეგი ფორმულების გამოყენებით: $$ \დაწყება{მასივი}{l} W^{(n+1)}=W^{(n)}-\eta\frac{\partial\mathcal{L}}{\partial W} \ b^{(n+1)}=b^{(n)}-\eta\frac{\partial\mathcal{L}}{\partial b} \ \დასრულება{მასივი} $$
იტვირთება…ჩავატაროთ ტრენინგი. ჩვენ გავაკეთებთ რამდენიმე გავლას მონაცემთა ნაკრებში (ე.წ. ეპოქები), გავყოფთ მას მინიპატჩებად და გამოვიძახებთ ზემოთ განსაზღვრულ ფუნქციას:
იტვირთება…იტვირთება…გამოტანა
Epoch 0: last batch loss = 94.5247
Epoch 1: last batch loss = 9.3428
Epoch 2: last batch loss = 1.4166
Epoch 3: last batch loss = 0.5224
Epoch 4: last batch loss = 0.3807
Epoch 5: last batch loss = 0.3495
Epoch 6: last batch loss = 0.3413
Epoch 7: last batch loss = 0.3390
Epoch 8: last batch loss = 0.3384
Epoch 9: last batch loss = 0.3382
ჩვენ ახლა მივიღეთ ოპტიმიზებული პარამეტრები $W$ და $b$. Note that their values are similar to the original values used when generating the dataset ($W=2, b=1$)
იტვირთება…გამოტანა
(<tf.Variable 'Variable:0' shape=(1, 1) dtype=float32, numpy=array([[1.8616779]], dtype=float32)>,
<tf.Variable 'Variable:0' shape=(1,) dtype=float32, numpy=array([1.0710956], dtype=float32)>)იტვირთება…გამოტანა
[<matplotlib.lines.Line2D at 0x12892ae5eb0>]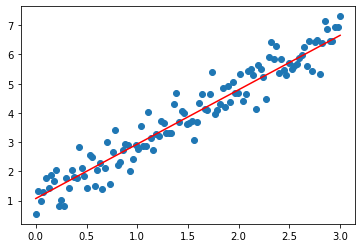
გამოთვლითი გრაფიკი და GPU გამოთვლები
როდესაც ჩვენ გამოვთვლით ტენზორის გამოხატვას, Tensorflow აშენებს გამოთვლით გრაფიკს, რომელიც შეიძლება გამოითვალოს ხელმისაწვდომ გამოთვლით მოწყობილობაზე, მაგ. CPU ან GPU. ვინაიდან ჩვენ ვიყენებდით პითონის თვითნებურ ფუნქციას ჩვენს კოდში, ისინი არ შეიძლება იყოს ჩართული გამოთვლითი გრაფიკის ნაწილად და, შესაბამისად, ჩვენი კოდის GPU-ზე გაშვებისას, დაგვჭირდება მონაცემების გადაცემა CPU-სა და GPU-ს შორის წინ და უკან, და გამოვთვალოთ მორგებული ფუნქცია CPU-ზე.
Tensorflow საშუალებას გვაძლევს აღვნიშნოთ ჩვენი პითონის ფუნქცია @tf.function დეკორატორის გამოყენებით, რაც ამ ფუნქციას იგივე გამოთვლითი გრაფიკის ნაწილად აქცევს. ეს დეკორატორი შეიძლება გამოყენებულ იქნას ფუნქციებზე, რომლებიც იყენებენ სტანდარტულ Tensorflow ტენსორის ოპერაციებს.
იტვირთება…კოდი არ შეცვლილა, მაგრამ თუ ამ კოდს აწარმოებდით GPU-ზე და უფრო დიდ მონაცემთა ბაზაზე - შეამჩნევდით განსხვავებას სიჩქარეში.
მონაცემთა ნაკრები API
Tensorflow შეიცავს მოსახერხებელ API-ს მონაცემებთან მუშაობისთვის. ვცადოთ მისი გამოყენება. ჩვენ ასევე მოვამზადებთ ჩვენს მოდელს ნულიდან.
იტვირთება…გამოტანა
Epoch 0: last batch loss = 173.4585
Epoch 1: last batch loss = 13.8459
Epoch 2: last batch loss = 4.5407
Epoch 3: last batch loss = 3.7364
Epoch 4: last batch loss = 3.4334
Epoch 5: last batch loss = 3.1790
Epoch 6: last batch loss = 2.9458
Epoch 7: last batch loss = 2.7311
Epoch 8: last batch loss = 2.5332
Epoch 9: last batch loss = 2.3508
მაგალითი 2: კლასიფიკაცია
ახლა განვიხილავთ ორობითი კლასიფიკაციის პრობლემას. ასეთი პრობლემის კარგი მაგალითი იქნება სიმსივნის კლასიფიკაცია ავთვისებიანსა და კეთილთვისებიანს შორის მისი ზომისა და ასაკის მიხედვით.
ძირითადი მოდელი რეგრესიის მსგავსია, მაგრამ ჩვენ უნდა გამოვიყენოთ სხვადასხვა დანაკარგის ფუნქცია. დავიწყოთ ნიმუშის მონაცემების გენერირებით:
იტვირთება…იტვირთება…იტვირთება…გამოტანა
C:\Users\dmitryso\AppData\Local\Temp/ipykernel_66184/2721537645.py:17: UserWarning: Matplotlib is currently using module://matplotlib_inline.backend_inline, which is a non-GUI backend, so cannot show the figure.
fig.show()
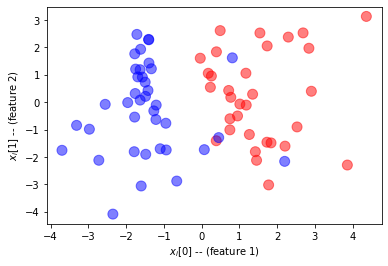
მონაცემთა ნორმალიზება
ვარჯიშის დაწყებამდე ჩვეულებრივია ჩვენი შეყვანის მახასიათებლების [0,1] (ან [-1,1]) სტანდარტულ დიაპაზონში მიყვანა. ამის ზუსტ მიზეზებს მოგვიანებით განვიხილავთ, მაგრამ მოკლედ ამის მიზეზი შემდეგია. ჩვენ გვინდა, რომ ავიცილოთ მნიშვნელობები, რომლებიც მიედინება ჩვენს ქსელში, არ გახდეს ძალიან დიდი ან ძალიან მცირე, და ჩვენ ჩვეულებრივ ვთანხმდებით, რომ ყველა მნიშვნელობა შევინარჩუნოთ მცირე დიაპაზონში 0-თან ახლოს. ამრიგად, ჩვენ ვაყენებთ წონებს მცირე შემთხვევითი რიცხვებით და ვინახავთ სიგნალებს იმავე დიაპაზონში.
მონაცემთა ნორმალიზებისას, ჩვენ უნდა გამოვაკლოთ min მნიშვნელობა და გავყოთ დიაპაზონზე. ჩვენ ვიანგარიშებთ მინიმალურ მნიშვნელობას და დიაპაზონს სასწავლო მონაცემების გამოყენებით, შემდეგ კი ტესტირების/დამოწმების მონაცემთა ნაკრების ნორმალიზებას იგივე მინ/დიაპაზონის მნიშვნელობების გამოყენებით სასწავლო ნაკრებიდან. ეს იმიტომ ხდება, რომ რეალურ ცხოვრებაში ჩვენ ვიცნობთ მხოლოდ სასწავლო კომპლექტს და არა ყველა შემომავალ ახალ მნიშვნელობას, რომლის პროგნოზირებაც ქსელს მოეთხოვება. ხანდახან, ახალი მნიშვნელობა შესაძლოა [0,1] დიაპაზონში აღმოჩნდეს, მაგრამ ეს არ არის გადამწყვეტი.
იტვირთება…ტრენინგი ერთშრიანი პერცეპტრონი
მოდით გამოვიყენოთ ტენსორფლოს გრადიენტური გამოთვლითი აპარატურა ერთშრიანი პერცეპტრონის მოსამზადებლად.
ჩვენს ნერვულ ქსელს ექნება 2 შეყვანა და 1 გამომავალი. წონის მატრიცას $W$ ექნება ზომა $2\ჯერ1$ და მიკერძოების ვექტორი $b$ -- $1$.
ძირითადი მოდელი იქნება იგივე, რაც წინა მაგალითში, მაგრამ დაკარგვის ფუნქცია იქნება ლოგისტიკური დანაკარგი. ლოგისტიკური დანაკარგის გამოსაყენებლად, ჩვენ უნდა მივიღოთ ალბათობა, როგორც ჩვენი ქსელის გამოსავალი, ანუ გამომავალი $z$ უნდა მივიყვანოთ დიაპაზონში [0,1] sigmoid აქტივაციის ფუნქციის გამოყენებით: $p=\sigma(z)$.
თუ მივიღებთ ალბათობას $p_i$ i-ის შეყვანის მნიშვნელობისთვის, რომელიც შეესაბამება $y_i\in{0,1}$ ფაქტობრივ კლასს, ჩვენ გამოვთვლით დანაკარგს $\mathcal{L_i}=-(y_i\log p_i + (1-y_i)log(1-p_i))$.
Tensorflow-ში ორივე ეს ნაბიჯი (სიგმოიდური და შემდეგ ლოგისტიკური დანაკარგის გამოყენება) შეიძლება განხორციელდეს ერთი ზარის გამოყენებით sigmoid_cross_entropy_with_logits ფუნქციაზე. იმის გამო, რომ ჩვენ ვავარჯიშებთ ჩვენს ქსელს მინი პარტიებში, ჩვენ უნდა გამოვთვალოთ დანაკარგის საშუალო რაოდენობა მინიპაკეტის ყველა ელემენტში reduce_mean-ის გამოყენებით:
იტვირთება…ჩვენ გამოვიყენებთ 16 ელემენტისგან შემდგარ მინი პაკეტებს და გავაკეთებთ ვარჯიშის რამდენიმე ეპოქას:
იტვირთება…გამოტანა
Epoch 0: last batch loss = 0.3823
Epoch 1: last batch loss = 0.5243
Epoch 2: last batch loss = 0.4510
Epoch 3: last batch loss = 0.3261
Epoch 4: last batch loss = 0.4177
Epoch 5: last batch loss = 0.3323
Epoch 6: last batch loss = 0.6294
Epoch 7: last batch loss = 0.6334
Epoch 8: last batch loss = 0.2571
Epoch 9: last batch loss = 0.3425
იმისათვის, რომ დავრწმუნდეთ, რომ ჩვენი ტრენინგი მუშაობდა, მოდით დავხატოთ ხაზი, რომელიც ჰყოფს ორ კლასს. გამოყოფის ხაზი განისაზღვრება განტოლებით $W\ჯერ x + b = 0.5$
იტვირთება…გამოტანა
C:\Users\dmitryso\AppData\Local\Temp/ipykernel_66184/2721537645.py:17: UserWarning: Matplotlib is currently using module://matplotlib_inline.backend_inline, which is a non-GUI backend, so cannot show the figure.
fig.show()
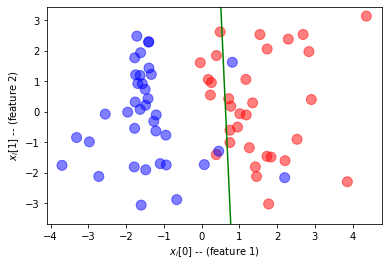
ვნახოთ, როგორ იქცევა ჩვენი მოდელი ვალიდაციის მონაცემებზე.
იტვირთება…გამოტანა
<matplotlib.collections.PathCollection at 0x12892a01460>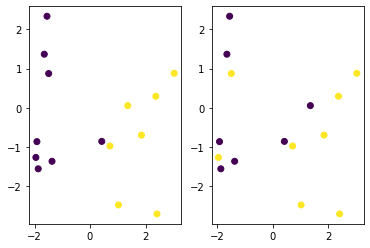
ვალიდაციის მონაცემებზე სიზუსტის გამოსათვლელად, ჩვენ შეგვიძლია მივცეთ ლოგიკური ტიპი float-ზე და გამოვთვალოთ საშუალო:
იტვირთება…გამოტანა
<tf.Tensor: shape=(), dtype=float32, numpy=0.46666667>მოდი ავხსნათ რა ხდება აქ:
predარის ქსელის მიერ პროგნოზირებული მნიშვნელობები. ისინი არ არის საკმაოდ ალბათობა, რადგან ჩვენ არ გამოგვიყენებია აქტივაციის ფუნქცია, მაგრამ 0.5-ზე მეტი მნიშვნელობები შეესაბამება 1 კლასს, ხოლო უფრო მცირე - კლასს 0.pred[0]>0.5ქმნის შედეგების ლოგიკურ ტენსორს, სადაცTrueშეესაბამება 1 კლასს, ხოლოFalse- 0 კლასს- ჩვენ ვადარებთ ამ ტენსორს მოსალოდნელ ეტიკეტებს
valid_labels, ვიღებთ ლოგიკურ ვექტორს ან სწორ პროგნოზებს, სადაცTrueშეესაბამება სწორ პროგნოზს დაFalse- არასწორს. - ჩვენ ამ ტენზორს ვცვლით მცურავ წერტილად
tf.cast-ის გამოყენებით - შემდეგ ჩვენ გამოვთვლით საშუალო მნიშვნელობას
tf.reduce_mean-ის გამოყენებით - ეს არის ზუსტად ჩვენი სასურველი სიზუსტე
TensorFlow/Keras ოპტიმიზატორების გამოყენება
Tensorflow მჭიდროდ არის ინტეგრირებული Keras-თან, რომელიც შეიცავს უამრავ სასარგებლო ფუნქციას. მაგალითად, ჩვენ შეგვიძლია გამოვიყენოთ სხვადასხვა ოპტიმიზაციის ალგორითმები. მოდით გავაკეთოთ ეს და ასევე დავბეჭდოთ ვარჯიშის დროს მიღებული სიზუსტე.
იტვირთება…გამოტანა
Epoch 0: last batch loss = 4.7787, acc = 1.0000
Epoch 1: last batch loss = 8.4343, acc = 0.5000
Epoch 2: last batch loss = 8.3255, acc = 0.5000
Epoch 3: last batch loss = 7.5579, acc = 0.5000
Epoch 4: last batch loss = 6.5254, acc = 0.5000
Epoch 5: last batch loss = 7.3800, acc = 0.5000
Epoch 6: last batch loss = 7.7586, acc = 0.5000
Epoch 7: last batch loss = 10.4724, acc = 0.0000
Epoch 8: last batch loss = 9.4423, acc = 0.5000
Epoch 9: last batch loss = 4.1888, acc = 1.0000
Epoch 10: last batch loss = 11.2127, acc = 0.0000
Epoch 11: last batch loss = 9.0417, acc = 0.5000
Epoch 12: last batch loss = 7.9847, acc = 0.5000
Epoch 13: last batch loss = 3.7879, acc = 1.0000
Epoch 14: last batch loss = 6.8455, acc = 0.5000
Epoch 15: last batch loss = 6.5204, acc = 0.5000
Epoch 16: last batch loss = 9.2386, acc = 0.5000
Epoch 17: last batch loss = 6.2447, acc = 0.5000
Epoch 18: last batch loss = 3.9107, acc = 1.0000
Epoch 19: last batch loss = 5.7645, acc = 1.0000
ამოცანა 1: დახაზეთ ზარალის ფუნქციისა და სიზუსტის გრაფიკები ტრენინგის დროს და დამოწმების მონაცემები
ამოცანა 2: სცადეთ გადაჭრათ MNIST კლასიფიკაციის პრობლემა ამ კოდის გამოყენებით. მინიშნება: გამოიყენეთ softmax_crossentropy_with_logits ან sparse_softmax_cross_entropy_with_logits დაკარგვის ფუნქციად. პირველ შემთხვევაში თქვენ უნდა მიაწოდოთ მოსალოდნელი გამომავალი მნიშვნელობები one-hot დაშიფვრაში, ხოლო მეორე შემთხვევაში - როგორც მთელი კლასის რიცხვი.
კერასი
ღრმა სწავლა ადამიანებისთვის
- Keras არის ბიბლიოთეკა, რომელიც თავდაპირველად შეიქმნა ფრანსუა შოლეტის მიერ, რათა იმუშაოს Tensorflow-ზე, CNTK-სა და Theano-ზე, რათა გააერთიანოს ყველა ქვედა დონის ჩარჩო. თქვენ მაინც შეგიძლიათ დააინსტალიროთ Keras, როგორც ცალკე ბიბლიოთეკა, მაგრამ ამის გაკეთება არ არის რეკომენდებული.
- ახლა Keras შედის Tensorflow ბიბლიოთეკის ნაწილად
- თქვენ შეგიძლიათ მარტივად ააწყოთ ნერვული ქსელები ფენებისგან
- შეიცავს
fitფუნქციას ყველა ვარჯიშის შესასრულებლად, პლუს უამრავ ფუნქციას ტიპიურ მონაცემებთან მუშაობისთვის (სურათები, ტექსტი და ა.შ.) - ბევრი ნიმუში
- ფუნქციური API vs. Sequential API
Keras უზრუნველყოფს უფრო მაღალი დონის აბსტრაქციას ნერვული ქსელებისთვის, რაც საშუალებას გვაძლევს ვიმოქმედოთ ფენების, მოდელებისა და ოპტიმიზატორების თვალსაზრისით და არა ტენსორებისა და გრადიენტების თვალსაზრისით.
კლასიკური ღრმა სწავლის წიგნი Keras-ის შემქმნელისგან: ღრმა სწავლა პითონთან ერთად
ფუნქციური API
ფუნქციური API-ს გამოყენებისას, ჩვენ განვსაზღვრავთ შესასვლელს ქსელში, როგორც keras.Input და შემდეგ გამოვთვალოთ გამომავალი გამოთვლების სერიის გავლით. და ბოლოს, ჩვენ განვსაზღვრავთ მოდელს, როგორც ობიექტს, რომელიც აქცევს შეყვანას გამოსავალად.
მას შემდეგ რაც მივიღეთ model ობიექტი, ჩვენ გვჭირდება:
- შეადგინეთ იგი, დაკარგვის ფუნქციის და ოპტიმიზატორის მითითებით, რომელიც გვინდა გამოვიყენოთ ჩვენს მოდელთან ერთად
- გაავარჯიშეთ
fitფუნქციის დარეკვით ტრენინგის (და შესაძლოა ვალიდაციის) მონაცემებით
იტვირთება…გამოტანა
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 2)] 0
dense (Dense) (None, 1) 3
=================================================================
Total params: 3
Trainable params: 3
Non-trainable params: 0
_________________________________________________________________
Epoch 1/15
9/9 [==============================] - 1s 2ms/step - loss: 0.7812 - accuracy: 0.2857
Epoch 2/15
9/9 [==============================] - 0s 2ms/step - loss: 0.7142 - accuracy: 0.4000
Epoch 3/15
9/9 [==============================] - 0s 2ms/step - loss: 0.6683 - accuracy: 0.6143
Epoch 4/15
9/9 [==============================] - 0s 2ms/step - loss: 0.6221 - accuracy: 0.8429
Epoch 5/15
9/9 [==============================] - 0s 2ms/step - loss: 0.5843 - accuracy: 0.8857
Epoch 6/15
9/9 [==============================] - 0s 2ms/step - loss: 0.5447 - accuracy: 0.9429
Epoch 7/15
9/9 [==============================] - 0s 2ms/step - loss: 0.5135 - accuracy: 0.9286
Epoch 8/15
9/9 [==============================] - 0s 2ms/step - loss: 0.4878 - accuracy: 0.9429
Epoch 9/15
9/9 [==============================] - 0s 2ms/step - loss: 0.4679 - accuracy: 0.9429
Epoch 10/15
9/9 [==============================] - 0s 2ms/step - loss: 0.4446 - accuracy: 0.9429
Epoch 11/15
9/9 [==============================] - 0s 2ms/step - loss: 0.4349 - accuracy: 0.8714
Epoch 12/15
9/9 [==============================] - 0s 2ms/step - loss: 0.4156 - accuracy: 0.9286
Epoch 13/15
9/9 [==============================] - 0s 2ms/step - loss: 0.4019 - accuracy: 0.9429
Epoch 14/15
9/9 [==============================] - 0s 2ms/step - loss: 0.3908 - accuracy: 0.9286
Epoch 15/15
9/9 [==============================] - 0s 2ms/step - loss: 0.3777 - accuracy: 0.9286
იტვირთება…გამოტანა
[<matplotlib.lines.Line2D at 0x12894b95250>]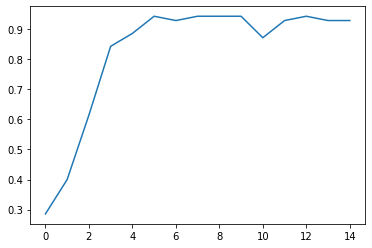
თანმიმდევრული API
ალტერნატიულად, ჩვენ შეგვიძლია დავიწყოთ მოდელზე ფიქრი, როგორც შრეების თანმიმდევრობა და უბრალოდ დავაზუსტოთ ეს შრეები model ობიექტზე დამატებით:
იტვირთება…გამოტანა
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 5) 15
dense_2 (Dense) (None, 1) 6
=================================================================
Total params: 21
Trainable params: 21
Non-trainable params: 0
_________________________________________________________________
Epoch 1/15
9/9 [==============================] - 1s 64ms/step - loss: 0.6994 - accuracy: 0.5000 - val_loss: 0.6719 - val_accuracy: 0.4667
Epoch 2/15
9/9 [==============================] - 0s 6ms/step - loss: 0.6635 - accuracy: 0.5429 - val_loss: 0.6531 - val_accuracy: 0.4667
Epoch 3/15
9/9 [==============================] - 0s 5ms/step - loss: 0.6469 - accuracy: 0.5857 - val_loss: 0.5775 - val_accuracy: 1.0000
Epoch 4/15
9/9 [==============================] - 0s 4ms/step - loss: 0.5639 - accuracy: 0.9143 - val_loss: 0.5395 - val_accuracy: 0.7333
Epoch 5/15
9/9 [==============================] - 0s 5ms/step - loss: 0.5236 - accuracy: 0.7143 - val_loss: 0.4498 - val_accuracy: 0.9333
Epoch 6/15
9/9 [==============================] - 0s 5ms/step - loss: 0.4573 - accuracy: 0.8714 - val_loss: 0.3584 - val_accuracy: 1.0000
Epoch 7/15
9/9 [==============================] - 0s 5ms/step - loss: 0.3867 - accuracy: 0.8714 - val_loss: 0.2989 - val_accuracy: 0.9333
Epoch 8/15
9/9 [==============================] - 0s 7ms/step - loss: 0.3388 - accuracy: 0.8857 - val_loss: 0.2204 - val_accuracy: 1.0000
Epoch 9/15
9/9 [==============================] - 0s 6ms/step - loss: 0.2815 - accuracy: 0.9429 - val_loss: 0.1957 - val_accuracy: 1.0000
Epoch 10/15
9/9 [==============================] - 0s 6ms/step - loss: 0.2692 - accuracy: 0.8857 - val_loss: 0.1323 - val_accuracy: 1.0000
Epoch 11/15
9/9 [==============================] - 0s 5ms/step - loss: 0.2591 - accuracy: 0.9429 - val_loss: 0.1105 - val_accuracy: 1.0000
Epoch 12/15
9/9 [==============================] - 0s 6ms/step - loss: 0.2229 - accuracy: 0.9286 - val_loss: 0.1051 - val_accuracy: 1.0000
Epoch 13/15
9/9 [==============================] - 0s 5ms/step - loss: 0.2146 - accuracy: 0.9143 - val_loss: 0.0919 - val_accuracy: 1.0000
Epoch 14/15
9/9 [==============================] - 0s 5ms/step - loss: 0.2031 - accuracy: 0.9429 - val_loss: 0.0859 - val_accuracy: 1.0000
Epoch 15/15
9/9 [==============================] - 0s 5ms/step - loss: 0.1997 - accuracy: 0.9429 - val_loss: 0.0829 - val_accuracy: 1.0000
<keras.callbacks.History at 0x12894cfba30>კლასიფიკაციის დაკარგვის ფუნქციები
მნიშვნელოვანია სწორად მიუთითოთ დაკარგვის ფუნქცია და აქტივაციის ფუნქცია ქსელის ბოლო ფენაზე. ძირითადი წესები შემდეგია:
- თუ ქსელს აქვს ერთი გამომავალი (ორობითი კლასიფიკაცია), ჩვენ ვიყენებთ sigmoid აქტივაციის ფუნქციას, მრავალკლასიანი კლასიფიკაციისთვის - softmax
- თუ გამომავალი კლასი წარმოდგენილია როგორც one-hot კოდირება, დანაკარგის ფუნქცია იქნება ჯვარედინი ენტროპიის დაკარგვა (კატეგორიული ჯვარედინი ენტროპია), თუ გამომავალი შეიცავს კლასის ნომერს - მწირი კატეგორიული ჯვარედინი ენტროპია. ორობითი კლასიფიკაციისთვის - გამოიყენეთ ორობითი ჯვარედინი ენტროპია (იგივე ლოგის დაკარგვა)
- მულტილეიბლიანი კლასიფიკაცია არის ის, როდესაც შეგვიძლია ერთდროულად რამდენიმე კლასს მიეკუთვნოს ობიექტი. ამ შემთხვევაში, ჩვენ გვჭირდება ეტიკეტების დაშიფვრა one-hot კოდირების გამოყენებით და გამოვიყენოთ sigmoid როგორც აქტივაციის ფუნქცია, ისე რომ თითოეული კლასის ალბათობა იყოს 0-დან 1-მდე.
| კლასიფიკაცია | ეტიკეტის ფორმატი | აქტივაციის ფუნქცია | დაკარგვა | |---------------------------------------|---------------|----------| | ორობითი | 1 კლასის ალბათობა | სიგმოიდური | ბინარული კროსენტროპია | | ორობითი | one-hot კოდირება (2 გამომავალი) | softmax | კატეგორიული კროსენტროპია | | მრავალკლასიანი | one-hot კოდირება | softmax | კატეგორიული კროსენტროპია | | მრავალკლასიანი | კლასის ნომერი | softmax | იშვიათი კატეგორიული კროსენტროპია | | მრავალნიშანი | one-hot კოდირება | სიგმოიდური | კატეგორიული კროსენტროპია |
ბინარული კლასიფიკაცია ასევე შეიძლება განიხილებოდეს, როგორც მრავალკლასიანი კლასიფიკაციის განსაკუთრებული შემთხვევა ორი გამოსავლით. ამ შემთხვევაში, ჩვენ უნდა გამოვიყენოთ softmax.
ამოცანა 3: გამოიყენეთ Keras MNIST კლასიფიკატორის მოსამზადებლად:
- გაითვალისწინეთ, რომ Keras შეიცავს რამდენიმე სტანდარტულ მონაცემთა ნაკრებს, მათ შორის MNIST. Keras-ის MNIST-ის გამოსაყენებლად საჭიროა მხოლოდ რამდენიმე ხაზი კოდი (დამატებითი ინფორმაცია აქ)
- სცადეთ რამდენიმე ქსელის კონფიგურაცია, სხვადასხვა რაოდენობის ფენებით/ნეირონებით, აქტივაციის ფუნქციებით.
რა არის საუკეთესო სიზუსტე, რისი მიღწევაც შეძელით?
Takeaways
- Tensorflow საშუალებას გაძლევთ იმუშაოთ ტენსორებზე დაბალ დონეზე, თქვენ გაქვთ ყველაზე მეტი მოქნილობა.
- არსებობს მოსახერხებელი ხელსაწყოები მონაცემებთან (
td.Data) და ფენებთან მუშაობისთვის (tf.layers) - დამწყებთათვის/ტიპიური ამოცანებისთვის რეკომენდებულია Keras-ის გამოყენება, რომელიც საშუალებას გაძლევთ შექმნათ ქსელები ფენებიდან.
- თუ საჭიროა არასტანდარტული არქიტექტურა, შეგიძლიათ განახორციელოთ საკუთარი Keras ფენა და შემდეგ გამოიყენოთ Keras მოდელებში
- კარგი იდეაა გადახედოთ PyTorch-საც და შევადაროთ მიდგომები.
კარგი ნიმუში ნოუთბუქის შემქმნელი Keras on Keras და Tensorflow 2.0 შეგიძლიათ იხილოთ აქ.