ჩვენს წინა მაგალითში, ჩვენ ვიმუშავეთ მაღალგანზომილებიანი ჩანთა-სიტყვების ვექტორებზე vocab_size სიგრძით, და ჩვენ ცალსახად გადავაქციეთ დაბალგანზომილებიანი პოზიციური წარმოდგენის ვექტორები იშვიათ ერთ-ცხელ გამოსახულებად. ეს ერთჯერადი წარმოდგენა არ არის მეხსიერების ეფექტური. გარდა ამისა, თითოეული სიტყვა განიხილება ერთმანეთისგან დამოუკიდებლად, ასე რომ, one-hot კოდირებული ვექტორები არ გამოხატავენ სემანტიკურ მსგავსებებს სიტყვებს შორის.
ამ განყოფილებაში ჩვენ გავაგრძელებთ News AG მონაცემთა ბაზის შესწავლას. დასაწყისისთვის, მოდით ჩატვირთოთ მონაცემები და მივიღოთ გარკვეული განმარტებები წინა ერთეულიდან.
იტვირთება…რა არის ემბედინგი?
ჩანერგვის იდეა არის სიტყვების წარმოდგენა ქვედა განზომილებიანი მკვრივი ვექტორების გამოყენებით, რომლებიც ასახავს სიტყვის სემანტიკურ მნიშვნელობას. ჩვენ მოგვიანებით განვიხილავთ, თუ როგორ უნდა ავაშენოთ შინაარსიანი სიტყვების ემბედინგი, მაგრამ ახლა მოდით, უბრალოდ ვიფიქროთ ემბედინგიზე, როგორც სიტყვის ვექტორის განზომილების შემცირების გზაზე.
ასე რომ, ჩაშენებული ფენა იღებს სიტყვას, როგორც შეყვანა და აწარმოებს გამომავალ ვექტორს მითითებული embedding_size. გარკვეული გაგებით, ის ძალიან ჰგავს Dense ფენას, მაგრამ იმის ნაცვლად, რომ one-hot კოდირებული ვექტორი შეყვანის სახით მიიღოს, მას შეუძლია სიტყვის რიცხვის აღება.
ჩვენი ქსელის პირველ ფენად ჩაშენებული ფენის გამოყენებით, ჩვენ შეგვიძლია გადავიტანოთ ჩანთა-of-words ჩაშენების ტომარაზე მოდელზე, სადაც ჯერ ჩვენს ტექსტში თითოეულ სიტყვას გადავიყვანთ შესაბამის ჩასმაში და შემდეგ გამოვთვალოთ აგრეგატული ფუნქცია ყველა ამ ემბედინგიზე, როგორიცაა sum, _____________ ან ____________.
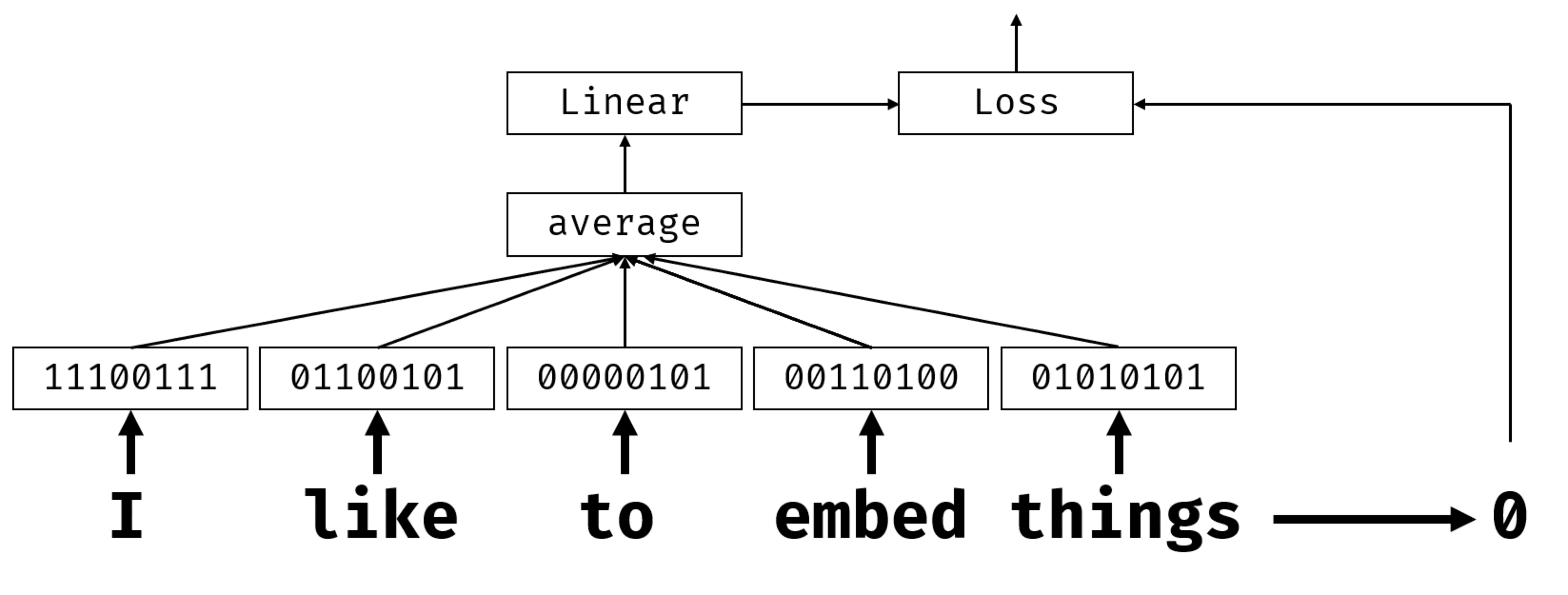
ჩვენი კლასიფიკატორის ნერვული ქსელი შედგება შემდეგი ფენებისგან:
TextVectorizationფენა, რომელიც იღებს სტრიქონს შეყვანად და აწარმოებს ტოკენური რიცხვების ტენსორს. ჩვენ დავაზუსტებთ ლექსიკის გონივრულ ზომასvocab_sizeდა უგულებელყოფთ ნაკლებად ხშირად გამოყენებულ სიტყვებს. შეყვანის ფორმა იქნება 1, ხოლო გამომავალი ფორმა იქნება $n$, რადგან შედეგად მივიღებთ $n$ ნიშნებს, რომელთაგან თითოეული შეიცავს რიცხვებს 0-დანvocab_size-მდე.Embeddingფენა, რომელიც იღებს $n$ რიცხვებს და ამცირებს თითოეულ რიცხვს მოცემული სიგრძის მკვრივ ვექტორამდე (ჩვენს მაგალითში 100). ამრიგად, $n$ ფორმის შეყვანის ტენსორი გარდაიქმნება $n\ჯერ 100$ ტენზორად.- აგრეგაციის ფენა, რომელიც იღებს ამ ტენზორის საშუალოს პირველი ღერძის გასწვრივ, ანუ გამოთვლის ყველა $n$ შეყვანის ტენზორის საშუალოს, რომელიც შეესაბამება სხვადასხვა სიტყვას. ამ ფენის განსახორციელებლად, ჩვენ გამოვიყენებთ
Lambdaფენას და მასში გადავცემთ ფუნქციას საშუალოს გამოსათვლელად. გამომავალს ექნება 100-ის ფორმა და ეს იქნება მთელი შეყვანის თანმიმდევრობის რიცხვითი წარმოდგენა. - საბოლოო
Denseწრფივი კლასიფიკატორი.
იტვირთება…გამოტანა
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization (TextVec (None, None) 0
torization)
embedding (Embedding) (None, None, 100) 3000000
lambda (Lambda) (None, 100) 0
dense (Dense) (None, 4) 404
=================================================================
Total params: 3,000,404
Trainable params: 3,000,404
Non-trainable params: 0
_________________________________________________________________
summary ამონაბეჭდში, გამომავალი ფორმის სვეტში, პირველი ტენზორის განზომილება None შეესაბამება მინი-სარტყის ზომას, ხოლო მეორე შეესაბამება ნიშნის მიმდევრობის სიგრძეს. ყველა ნიშანთა თანმიმდევრობას მინი პარტიაში განსხვავებული სიგრძე აქვს. ჩვენ განვიხილავთ, თუ როგორ გავუმკლავდეთ მას შემდეგ ნაწილში.
ახლა ვავარჯიშოთ ქსელი:
იტვირთება…გამოტანა
Training vectorizer
938/938 [==============================] - 20s 20ms/step - loss: 0.7891 - acc: 0.8155 - val_loss: 0.4470 - val_acc: 0.8642
<keras.callbacks.History at 0x22255515100>შენიშვნა, რომ ჩვენ ვაშენებთ ვექტორიზატორს მონაცემების ქვეჯგუფზე დაყრდნობით. ეს კეთდება პროცესის დაჩქარების მიზნით და შეიძლება გამოიწვიოს სიტუაცია, როდესაც ჩვენი ტექსტიდან ყველა ნიშანი არ არის ლექსიკაში. ამ შემთხვევაში, ეს ნიშნები იქნება იგნორირებული, რამაც შეიძლება გამოიწვიოს ოდნავ დაბალი სიზუსტე. თუმცა, რეალურ ცხოვრებაში ტექსტის ქვეჯგუფი ხშირად იძლევა კარგ ლექსიკურ შეფასებას.
საქმე ცვლადი თანმიმდევრობის ზომებთან
მოდით გავიგოთ, როგორ ხდება ტრენინგი მინიპატჩებში. ზემოთ მოცემულ მაგალითში, შეყვანის ტენსორს აქვს განზომილება 1 და ჩვენ ვიყენებთ 128 სიგრძის მინი პარტიას, ასე რომ ტენზორის რეალური ზომა არის $128 \ჯერ 1$. თუმცა, ნიშნების რაოდენობა თითოეულ წინადადებაში განსხვავებულია. თუ გამოვიყენებთ TextVectorization ფენას ერთ შეყვანაზე, დაბრუნებული ტოკენების რაოდენობა განსხვავებულია, იმისდა მიხედვით, თუ როგორ ხდება ტექსტის ტოკენიზაცია:
იტვირთება…გამოტანა
tf.Tensor([ 1 45], shape=(2,), dtype=int64)
tf.Tensor([ 112 1271 1 3 1747 158], shape=(6,), dtype=int64)
თუმცა, როდესაც ვექტორიზატორს რამდენიმე თანმიმდევრობაზე ვიყენებთ, მან უნდა შექმნას მართკუთხა ფორმის ტენსორი, ასე რომ, ის ავსებს გამოუყენებელ ელემენტებს PAD ნიშნით (რომელიც ჩვენს შემთხვევაში არის ნული):
იტვირთება…გამოტანა
<tf.Tensor: shape=(2, 6), dtype=int64, numpy=
array([[ 1, 45, 0, 0, 0, 0],
[ 112, 1271, 1, 3, 1747, 158]], dtype=int64)>აქ ჩვენ შეგვიძლია ვნახოთ ემბედინგები:
იტვირთება…გამოტანა
array([[[ 1.53059261e-02, 6.80514947e-02, 3.14026810e-02, ...,
-8.92002955e-02, 1.52911525e-04, -5.65562584e-02],
[ 2.57456154e-01, 2.79364467e-01, -2.03605562e-01, ...,
-2.07474351e-01, 8.31158683e-02, -2.03911960e-01],
[ 3.98201384e-02, -8.03454965e-03, 2.39790026e-02, ...,
-7.18549127e-04, 2.66963355e-02, -4.30646613e-02],
[ 3.98201384e-02, -8.03454965e-03, 2.39790026e-02, ...,
-7.18549127e-04, 2.66963355e-02, -4.30646613e-02],
[ 3.98201384e-02, -8.03454965e-03, 2.39790026e-02, ...,
-7.18549127e-04, 2.66963355e-02, -4.30646613e-02],
[ 3.98201384e-02, -8.03454965e-03, 2.39790026e-02, ...,
-7.18549127e-04, 2.66963355e-02, -4.30646613e-02]],
[[ 1.89674050e-01, 2.61548996e-01, -3.67433839e-02, ...,
-2.07366899e-01, -1.05442435e-01, -2.36952081e-01],
[ 6.16133213e-02, 1.80511594e-01, 9.77298319e-02, ...,
-5.46628237e-02, -1.07340455e-01, -1.06589928e-01],
[ 1.53059261e-02, 6.80514947e-02, 3.14026810e-02, ...,
-8.92002955e-02, 1.52911525e-04, -5.65562584e-02],
[-4.84890305e-02, -8.41715634e-02, 1.51529670e-01, ...,
1.28192469e-01, -7.77286515e-02, 1.26041949e-01],
[-4.17212099e-02, -5.60694858e-02, 4.08860669e-02, ...,
8.70475471e-02, 8.92383084e-02, 1.67974353e-01],
[ 2.85779923e-01, 4.57767487e-01, 4.52292450e-02, ...,
-1.97419018e-01, -2.04659685e-01, -2.79758364e-01]]],
dtype=float32)შენიშვნა: შიგთავსის რაოდენობის შესამცირებლად, ზოგიერთ შემთხვევაში აზრი აქვს მონაცემთა ნაკრების ყველა თანმიმდევრობის დალაგებას სიგრძის გაზრდის (ან, უფრო ზუსტად, ტოკენების რაოდენობის) მიხედვით. ეს უზრუნველყოფს, რომ თითოეული მინი პარტია შეიცავს მსგავსი სიგრძის თანმიმდევრობებს.
სემანტიკური ემბედინგები: Word2Vec
ჩვენს წინა მაგალითში, ჩაშენების ფენამ ისწავლა სიტყვების ვექტორულ წარმოდგენაზე გადატანა, თუმცა ამ წარმოდგენებს არ ჰქონდათ სემანტიკური მნიშვნელობა. კარგი იქნება ვისწავლოთ ვექტორული წარმოდგენა ისეთი, რომ მსგავსი სიტყვები ან სინონიმები შეესაბამებოდეს ვექტორებს, რომლებიც ახლოს არიან ერთმანეთთან გარკვეული ვექტორული მანძილით (მაგალითად, ევკლიდიური მანძილით).
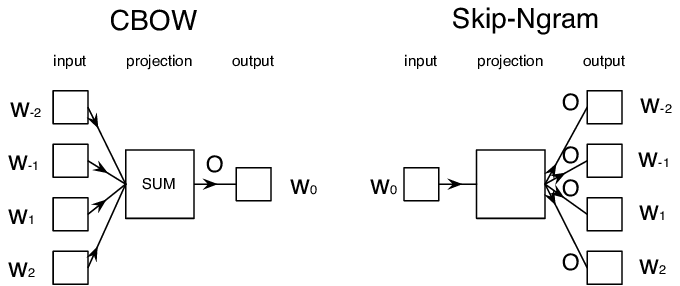
ამისათვის ჩვენ უნდა მოვამზადოთ ჩვენი ჩაშენების მოდელი ტექსტის დიდ კოლექციაზე ისეთი ტექნიკის გამოყენებით, როგორიცაა Word2Vec. ის დაფუძნებულია ორ მთავარ არქიტექტურაზე, რომლებიც გამოიყენება სიტყვების განაწილებული წარმოდგენის შესაქმნელად:
- სიტყვების უწყვეტი ტომარა (CBoW), სადაც ვავარჯიშებთ მოდელს სიტყვის პროგნოზირებისთვის მიმდებარე კონტექსტიდან. $(W_{-2},W_{-1},W_0,W_1,W_2)$ ნგრამის გათვალისწინებით, მოდელის მიზანია $W_0$-ის პროგნოზირება $(W_{-2},W_{-1},W_1,W_2)$-დან.
- უწყვეტი skip-gram არის CBoW-ის საპირისპირო. მოდელი იყენებს კონტექსტური სიტყვების მიმდებარე ფანჯარას მიმდინარე სიტყვის პროგნოზირებისთვის.
CBoW უფრო სწრაფია და სანამ skip-gram უფრო ნელია, ის უკეთესად ასრულებს იშვიათად სიტყვებს.
Google News-ის მონაცემთა ბაზაში წინასწარ მომზადებული Word2Vec ჩაშენების ექსპერიმენტებისთვის, შეგვიძლია გამოვიყენოთ gensim ბიბლიოთეკა. ქვემოთ ვპოულობთ სიტყვებს, რომლებიც ყველაზე მეტად ჰგავს "ნერვულს".
შენიშვნა: როდესაც პირველად ქმნით სიტყვების ვექტორებს, მათ ჩამოტვირთვას შეიძლება გარკვეული დრო დასჭირდეს!
იტვირთება…იტვირთება…გამოტანა
neuronal -> 0.7804799675941467
neurons -> 0.7326500415802002
neural_circuits -> 0.7252851724624634
neuron -> 0.7174385190010071
cortical -> 0.6941086649894714
brain_circuitry -> 0.6923246383666992
synaptic -> 0.6699118614196777
neural_circuitry -> 0.6638563275337219
neurochemical -> 0.6555314064025879
neuronal_activity -> 0.6531826257705688
ჩვენ ასევე შეგვიძლია გამოვყოთ ვექტორული ემბედინგი სიტყვიდან, რომელიც გამოყენებული იქნება კლასიფიკაციის მოდელის ტრენინგში. ემბედინგის აქვს 300 კომპონენტი, მაგრამ აქ ჩვენ ვაჩვენებთ მხოლოდ ვექტორის პირველ 20 კომპონენტს სიცხადისთვის:
იტვირთება…გამოტანა
array([ 0.01226807, 0.06225586, 0.10693359, 0.05810547, 0.23828125,
0.03686523, 0.05151367, -0.20703125, 0.01989746, 0.10058594,
-0.03759766, -0.1015625 , -0.15820312, -0.08105469, -0.0390625 ,
-0.05053711, 0.16015625, 0.2578125 , 0.10058594, -0.25976562],
dtype=float32)სემანტიკური ჩაშენების შესანიშნავი რამ არის ის, რომ თქვენ შეგიძლიათ მანიპულირება ვექტორული კოდირებით სემანტიკაზე დაყრდნობით. მაგალითად, შეგვიძლია მოვითხოვოთ ვიპოვოთ სიტყვა, რომლის ვექტორული წარმოდგენა რაც შეიძლება ახლოს იყოს სიტყვებთან king და woman და რაც შეიძლება შორს სიტყვიდან man:
იტვირთება…გამოტანა
('queen', 0.7118192911148071)ზემოთ მოყვანილი მაგალითი იყენებს ზოგიერთ შიდა GenSym მაგიას, მაგრამ ძირითადი ლოგიკა სინამდვილეში საკმაოდ მარტივია. ჩაშენებებთან დაკავშირებით საინტერესოა ის, რომ თქვენ შეგიძლიათ შეასრულოთ ნორმალური ვექტორული ოპერაციები ვექტორების ემბედინგიზე და ეს ასახავს ოპერაციებს სიტყვის მნიშვნელობებზე. ზემოთ მოყვანილი მაგალითი შეიძლება გამოიხატოს ვექტორული ოპერაციებით: ჩვენ ვიანგარიშებთ ვექტორს, რომელიც შეესაბამება KING-MAN+WOMAN (ოპერაციები + და - შესრულებულია შესაბამისი სიტყვების ვექტორულ გამოსახულებებზე) და შემდეგ ვპოულობთ ლექსიკონში უახლოეს სიტყვას ამ ვექტორთან:
იტვირთება…გამოტანა
'queen'შენიშვნა: ჩვენ უნდა დავამატოთ პატარა კოეფიციენტები კაცი და ქალი ვექტორებს - სცადეთ მათი ამოღება, რათა ნახოთ რა მოხდება.
უახლოესი ვექტორის მოსაძებნად, ჩვენ ვიყენებთ TensorFlow აპარატს, რომ გამოვთვალოთ მანძილების ვექტორი ჩვენს ვექტორსა და ლექსიკაში არსებულ ყველა ვექტორს შორის და შემდეგ ვიპოვოთ მინიმალური სიტყვის ინდექსი argmin-ის გამოყენებით.
მიუხედავად იმისა, რომ Word2Vec, როგორც ჩანს, შესანიშნავი გზაა სიტყვების სემანტიკის გამოხატვისთვის, მას აქვს მრავალი უარყოფითი მხარე, მათ შორის შემდეგი:
- ორივე CBoW და skip-gram მოდელი პროგნოზირებადი ემბედინგია და ის მხოლოდ ლოკალურ კონტექსტს ითვალისწინებს. Word2Vec არ იყენებს გლობალურ კონტექსტს.
- Word2Vec არ ითვალისწინებს სიტყვას მორფოლოგია, ანუ იმ ფაქტს, რომ სიტყვის მნიშვნელობა შეიძლება დამოკიდებული იყოს სიტყვის სხვადასხვა ნაწილზე, მაგალითად, ფესვზე.
FastText ცდილობს დაძლიოს მეორე შეზღუდვა და ეფუძნება Word2Vec-ს ყოველი სიტყვისთვის ვექტორული წარმოდგენებისა და თითოეულ სიტყვაში ნაპოვნი სიმბოლოების n-გრამების შესწავლით. შემდეგ წარმომადგენლობების მნიშვნელობები საშუალოდ ერთ ვექტორად ხდება ყოველი ვარჯიშის საფეხურზე. მიუხედავად იმისა, რომ ეს უამრავ დამატებით გამოთვლას მატებს წინასწარ ტრენინგს, ის აძლევს სიტყვის ემბედინგის ქვესიტყვის ინფორმაციის დაშიფვრის საშუალებას.
კიდევ ერთი მეთოდი, GloVe, იყენებს განსხვავებულ მიდგომას სიტყვების ჩაშენების მიმართ, რომელიც დაფუძნებულია სიტყვა-კონტექსტის მატრიცის ფაქტორიზაციაზე. პირველ რიგში, ის აშენებს დიდ მატრიცას, რომელიც ითვლის სიტყვების გაჩენის რაოდენობას სხვადასხვა კონტექსტში, შემდეგ კი ცდილობს ეს მატრიცა წარმოაჩინოს ქვედა ზომებში ისე, რომ მინიმუმამდე დაიყვანოს რეკონსტრუქციის დანაკარგი.
Gensim ბიბლიოთეკა მხარს უჭერს ამ სიტყვების ემბედინგის და შეგიძლიათ ექსპერიმენტი გააკეთოთ მათზე ზემოთ მოყვანილი მოდელის ჩატვირთვის კოდის შეცვლით.
წინასწარ მომზადებული ემბედინგების გამოყენება კერასში
ჩვენ შეგვიძლია შევცვალოთ ზემოთ მოყვანილი მაგალითი, რათა განვსაზღვროთ მატრიცა ჩვენს ჩაშენების ფენაში სემანტიკური ემბედინგებით, როგორიცაა Word2Vec. წინასწარ მომზადებული ჩაშენების ლექსიკა და ტექსტის კორპუსები, სავარაუდოდ, არ ემთხვევა, ამიტომ ჩვენ უნდა ავირჩიოთ ერთი. აქ ჩვენ ვიკვლევთ ორ შესაძლო ვარიანტს: ტოკენიზატორის ლექსიკის გამოყენება და Word2Vec ემბედინგების ლექსიკის გამოყენება.
ტოკენიზატორის ლექსიკის გამოყენება
ტოკენიზატორის ლექსიკის გამოყენებისას, ლექსიკის ზოგიერთ სიტყვას ექნება შესაბამისი Word2Vec ემბედინგი, ზოგს კი აკლია. იმის გათვალისწინებით, რომ ჩვენი ლექსიკის ზომაა vocab_size და Word2Vec ჩაშენებული ვექტორის სიგრძე embed_size, ჩაშენებული ფენა განმეორდება ფორმის წონის მატრიცით vocab_size$\ჯერ$embed_size. ჩვენ შევავსებთ ამ მატრიცას ლექსიკის გავლის გზით:
იტვირთება…გამოტანა
Embedding size: 300
Populating matrix, this will take some time...Done, found 4551 words, 784 words missing
სიტყვებისთვის, რომლებიც არ არის Word2Vec ლექსიკაში, შეგვიძლია დავტოვოთ ისინი ნულებად, ან შევქმნათ შემთხვევითი ვექტორი.
ახლა ჩვენ შეგვიძლია განვსაზღვროთ ჩაშენებული ფენა წინასწარ მომზადებული წონებით:
იტვირთება…ახლა მოდით ვავარჯიშოთ ჩვენი მოდელი.
იტვირთება…გამოტანა
938/938 [==============================] - 10s 10ms/step - loss: 1.1075 - acc: 0.7822 - val_loss: 0.9134 - val_acc: 0.8175
<keras.callbacks.History at 0x2220226ef10>შენიშვნა: გაითვალისწინეთ, რომ ჩვენ დავაყენეთ
trainable=FalseEmbedding-ის შექმნისას, რაც ნიშნავს, რომ ჩვენ არ ვამზადებთ Embedding ფენას. ამან შეიძლება გამოიწვიოს სიზუსტის ოდნავ დაქვეითება, მაგრამ ეს აჩქარებს ვარჯიშს.
ლექსიკის ჩანერგვის გამოყენება
წინა მიდგომის ერთი პრობლემა ის არის, რომ ტექსტის ვექტორიზაციასა და ემბედინგიში გამოყენებული ლექსიკა განსხვავებულია. ამ პრობლემის დასაძლევად შეგვიძლია გამოვიყენოთ ერთ-ერთი შემდეგი გამოსავალი:
- ხელახლა ივარჯიშეთ Word2Vec მოდელი ჩვენს ლექსიკაზე.
- ჩატვირთეთ ჩვენი მონაცემთა ნაკრები წინასწარ მომზადებული Word2Vec მოდელის ლექსიკით. მონაცემთა ნაკრების ჩასატვირთად გამოყენებული ლექსიკა შეიძლება დაზუსტდეს ჩატვირთვის დროს.
ეს უკანასკნელი მიდგომა უფრო ადვილი ჩანს, ამიტომ განვახორციელოთ იგი. უპირველეს ყოვლისა, ჩვენ შევქმნით TextVectorization ფენას მითითებული ლექსიკით, აღებული Word2Vec ემბედინგებიდან:
იტვირთება…Gensim Word embeddings ბიბლიოთეკა შეიცავს მოსახერხებელ ფუნქციას, get_keras_embeddings, რომელიც ავტომატურად შექმნის თქვენთვის Keras-ის ჩაშენების შესაბამის ფენას.
იტვირთება…გამოტანა
Epoch 1/5
938/938 [==============================] - 20s 14ms/step - loss: 1.3377 - acc: 0.4978 - val_loss: 1.2995 - val_acc: 0.5647
Epoch 2/5
938/938 [==============================] - 10s 10ms/step - loss: 1.2587 - acc: 0.5722 - val_loss: 1.2339 - val_acc: 0.5842
Epoch 3/5
938/938 [==============================] - 10s 10ms/step - loss: 1.1980 - acc: 0.5884 - val_loss: 1.1826 - val_acc: 0.5954
Epoch 4/5
938/938 [==============================] - 12s 13ms/step - loss: 1.1503 - acc: 0.6002 - val_loss: 1.1417 - val_acc: 0.6018
Epoch 5/5
938/938 [==============================] - 11s 12ms/step - loss: 1.1120 - acc: 0.6097 - val_loss: 1.1083 - val_acc: 0.6104
<keras.callbacks.History at 0x2220ccb81c0>ერთ-ერთი მიზეზი, რის გამოც ჩვენ ვერ ვხედავთ უფრო მაღალ სიზუსტეს, არის ის, რომ ზოგიერთი სიტყვა ჩვენი მონაცემთა ნაკრებიდან აკლია წინასწარ გამზადებულ GloVe ლექსიკაში და, შესაბამისად, ისინი არსებითად იგნორირებულია. ამის დასაძლევად, ჩვენ შეგვიძლია მოვამზადოთ საკუთარი ემბედინგები ჩვენს მონაცემთა ბაზაზე დაყრდნობით.
კონტექსტური ემბედინგები
ტრადიციული წინასწარ მომზადებული ჩაშენების წარმოდგენების ერთ-ერთი მთავარი შეზღუდვა, როგორიცაა Word2Vec, არის ის ფაქტი, რომ მიუხედავად იმისა, რომ მათ შეუძლიათ სიტყვის გარკვეული მნიშვნელობის აღქმა, მათ არ შეუძლიათ განასხვავონ სხვადასხვა მნიშვნელობა. ამან შეიძლება გამოიწვიოს პრობლემები ქვედა დინების მოდელებში.
მაგალითად, სიტყვა "თამაშს" განსხვავებული მნიშვნელობა აქვს ამ ორ განსხვავებულ წინადადებაში:
- თეატრში სპექტაკლზე წავედი.
- ჯონს სურს თამაში მეგობრებთან ერთად.
წინასწარ მომზადებული ემბედინგები, რომლებზეც ჩვენ ვისაუბრეთ, წარმოადგენს სიტყვა „თამაშის“ ორივე მნიშვნელობას ერთსა და იმავე ჩადგმაში. ამ შეზღუდვის დასაძლევად, ჩვენ უნდა ავაშენოთ ემბედინგები ენის მოდელზე საფუძველზე, რომელიც გაწვრთნილია ტექსტის დიდ კორპუსზე და იცის როგორ შეიძლება სიტყვების გაერთიანება სხვადასხვა კონტექსტში. კონტექსტური ემბედინგების განხილვა არ არის ამ სახელმძღვანელოსთვის, მაგრამ ჩვენ მათ დავუბრუნდებით, როდესაც ვისაუბრებთ ენის მოდელებზე მომდევნო თავში.