სალექციო ვიქტორინა
BoW ან TF/IDF-ზე დაფუძნებული კლასიფიკატორების მომზადებისას, ჩვენ ვმუშაობდით მაღალი განზომილებიანი ჩანთა-სიტყვების ვექტორებზე სიგრძით vocab_size და ჩვენ აშკარად ვცვლიდით დაბალგანზომილებიანი პოზიციური წარმოდგენის ვექტორებიდან იშვიათ ერთ-ცხელ გამოსახულებად. თუმცა, ეს ერთჯერადი წარმოდგენა არ არის მეხსიერების ეფექტური. გარდა ამისა, თითოეული სიტყვა განიხილება ერთმანეთისგან დამოუკიდებლად, ანუ one-hot კოდირებული ვექტორები არ გამოხატავს რაიმე სემანტიკურ მსგავსებას სიტყვებს შორის.
ჩაშენების იდეა არის სიტყვების წარმოდგენა ქვედა განზომილებიანი მკვრივი ვექტორებით, რომლებიც ერთგვარად ასახავს სიტყვის სემანტიკურ მნიშვნელობას. ჩვენ მოგვიანებით განვიხილავთ, თუ როგორ უნდა ავაშენოთ შინაარსიანი სიტყვების ემბედინგი, მაგრამ ახლა მოდით, უბრალოდ ვიფიქროთ ემბედინგიზე, როგორც სიტყვის ვექტორის განზომილების შემცირების გზაზე.
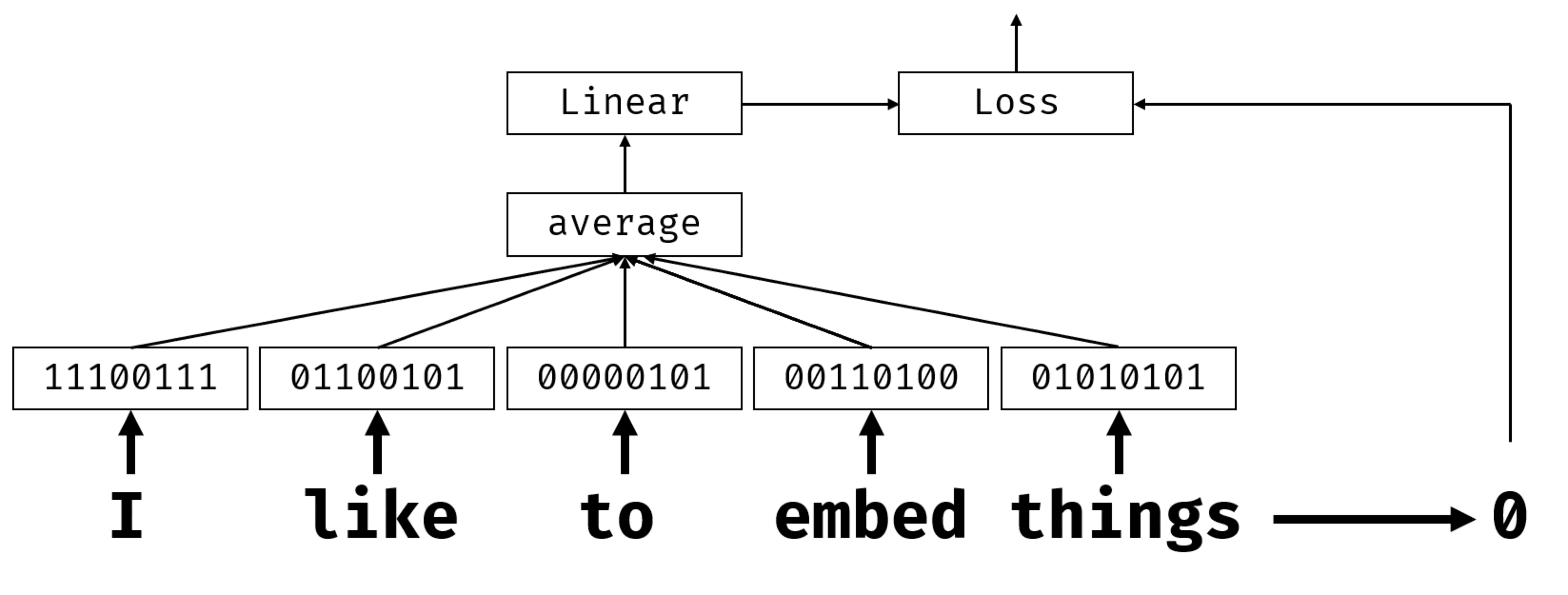
ასე რომ, ჩაშენებული ფენა მიიღებს სიტყვას, როგორც შეყვანის სახით და წარმოქმნის გამომავალ ვექტორს მითითებული embedding_size-ით. გარკვეული გაგებით, ის ძალიან ჰგავს Linear ფენას, მაგრამ იმის ნაცვლად, რომ აიღოს one-hot კოდირებული ვექტორი, მას შეუძლია მიიღოს სიტყვის რიცხვი, როგორც შეყვანა, რაც საშუალებას მოგვცემს თავიდან ავიცილოთ დიდი one-hot კოდირებული ვექტორების შექმნა.
ჩვენს კლასიფიკატორის ქსელში პირველ ფენად ჩაშენებული ფენის გამოყენებით, ჩვენ შეგვიძლია გადავიტანოთ ჩანთა-of-word-დან embedding bag მოდელზე, სადაც ჯერ ჩვენს ტექსტში თითოეულ სიტყვას გადავიყვანთ შესაბამის ემბედინგიდ, შემდეგ კი გამოვთვალოთ აგრეგატული ფუნქცია ყველა ამ ემბედინგიზე, როგორიცაა sum, ____DE _____________________________.
ავტორის სურათი
სავარჯიშოები: ჩასმა
განაგრძეთ სწავლა შემდეგ რვეულებში:
- ემბედინგები PyTorch-თან ერთად
- ემბედინგები TensorFlow
სემანტიკური ემბედინგები: Word2Vec
მიუხედავად იმისა, რომ ემბედინგის ფენას შეუძლია სიტყვების ვექტორულ წარმოდგენაში გარდაქმნა (ასახვა), ამ წარმოდგენას მაინც არ გააჩნია დიდი სემანტიკური მნიშვნელობა. კარგი იქნებოდა ისეთი ვექტორული წარმოდგენის აგება, სადაც მსგავსი სიტყვები ან სინონიმები ერთმანეთთან ახლოს მდებარე ვექტორებს შეესაბამებოდეს გარკვეული ვექტორული მანძილის მიხედვით (მაგ. ევკლიდეს მანძილით).
ამისათვის ჩვენ წინასწარ უნდა გავწვრთნათ ემბედინგის მოდელი ტექსტის დიდ კოლექციაზე კონკრეტული გზით. სემანტიკური ემბედინგის გაწვრთნის ერთ-ერთ მეთოდს ეწოდება Word2Vec. იგი დაფუძნებულია ორ მთავარ არქიტექტურაზე, რომლებიც გამოიყენება სიტყვების განაწილებული წარმოდგენის შესაქმნელად:
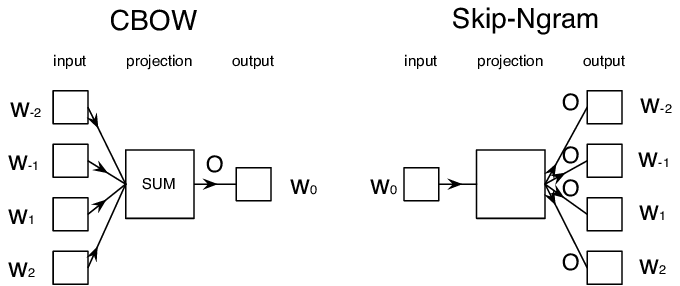
- სიტყვების უწყვეტი ტომარა (CBoW): ამ არქიტექტურაში ჩვენ ვწვრთნით მოდელს სიტყვის პროგნოზირებისთვის მიმდებარე კონტექსტიდან. $(W_{-2},W_{-1},W_0,W_1,W_2)$ n-გრამის გათვალისწინებით, მოდელის მიზანია $W_0$-ის პროგნოზირება $(W_{-2},W_{-1},W_1,W_2)$-დან.
- უწყვეტი skip-gram: ის CBoW-ის საპირისპიროა. მოდელი იყენებს კონტექსტური სიტყვების მიმდებარე ფანჯარას მიმდინარე სიტყვის პროგნოზირებისთვის.
CBoW უფრო სწრაფია, ხოლო skip-gram უფრო ნელი, მაგრამ უკეთესად ასრულებს იშვიათი სიტყვების წარმოდგენას.
სურათი ეს ქაღალდი-დან
Word2Vec წინასწარ მომზადებული ემბედინგები (ისევე როგორც სხვა მსგავსი მოდელები, როგორიცაა GloVe) ასევე შეიძლება გამოყენებულ იქნას ნერვულ ქსელებში ჩაშენებული ფენის ნაცვლად. თუმცა, ჩვენ უნდა შევეხოთ ლექსიკას, რადგან Word2Vec/GloVe-ის წინასწარ მომზადებისთვის გამოყენებული ლექსიკა, სავარაუდოდ, განსხვავდება ჩვენი ტექსტური კორპუსის ლექსიკისგან. გადახედეთ ზემოთ მოცემულ ნოუთბუქებს, რათა ნახოთ, როგორ შეიძლება ამ პრობლემის მოგვარება.
კონტექსტური ემბედინგები
ტრადიციული წინასწარ გაწვრთნილი ჩაშენების წარმოდგენის ერთ-ერთი მთავარი შეზღუდვა, როგორიცაა Word2Vec, არის სიტყვის გაგების გაუგებრობის პრობლემა. მიუხედავად იმისა, რომ წინასწარ გაწვრთნილ ჩაშენებებს შეუძლიათ სიტყვების ზოგიერთი მნიშვნელობის აღქმა კონტექსტში, სიტყვის ყველა შესაძლო მნიშვნელობა დაშიფრულია იმავე ჩასმაში. ამან შეიძლება გამოიწვიოს პრობლემები ქვედა დინების მოდელებში, რადგან ბევრ სიტყვას, როგორიცაა სიტყვა „თამაში“ განსხვავებული მნიშვნელობა აქვს იმისდა მიხედვით, თუ რა კონტექსტში გამოიყენება.
მაგალითად, სიტყვა "თამაში" ამ ორ განსხვავებულ წინადადებაში საკმაოდ განსხვავებული მნიშვნელობა აქვს:
- თეატრში სპექტაკლზე წავედი.
- ჯონს სურს თამაში მეგობრებთან ერთად.
ზემოთ მომზადებული ემბედინგები წარმოადგენს სიტყვა „თამაშის“ ორივე მნიშვნელობას იმავე ემბედინგიში. ამ შეზღუდვის დასაძლევად, ჩვენ უნდა ავაშენოთ ემბედინგები ენის მოდელზე საფუძველზე, რომელიც გაწვრთნილია ტექსტის დიდ კორპუსზე და იცის როგორ შეიძლება სიტყვების გაერთიანება სხვადასხვა კონტექსტში. კონტექსტური ემბედინგების განხილვა არ არის ამ სახელმძღვანელოსთვის, მაგრამ ჩვენ მათ დავუბრუნდებით, როდესაც მოგვიანებით კურსში ვისაუბრებთ ენის მოდელებზე.
დასკვნა
ამ გაკვეთილზე თქვენ აღმოაჩინეთ, თუ როგორ უნდა ააწყოთ და გამოიყენოთ ჩაშენებული ფენები TensorFlow-სა და Pytorch-ში, რათა უკეთ აისახოს სიტყვების სემანტიკური მნიშვნელობები.
გამოწვევა
Word2Vec გამოიყენებოდა რამდენიმე საინტერესო აპლიკაციისთვის, მათ შორის სიმღერის ტექსტისა და პოეზიის გენერირებისთვის. გადახედეთ ამ სტატიას-ს, სადაც აღწერილია, თუ როგორ გამოიყენა ავტორმა Word2Vec პოეზიის შესაქმნელად. ასევე უყურეთ ეს ვიდეო დენ შიფმანის მიერ-ს, რომ იპოვოთ ამ ტექნიკის განსხვავებული ახსნა. შემდეგ შეეცადეთ გამოიყენოთ ეს ტექნიკა თქვენს საკუთარ ტექსტურ კორპუსში, შესაძლოა კაგლიდან მომდინარეობდეს.
ლექციის შემდგომი ვიქტორინა
მიმოხილვა და თვითშესწავლა
წაიკითხეთ ეს ნაშრომი Word2Vec-ზე: ვექტორულ სივრცეში სიტყვების წარმოდგენის ეფექტური შეფასება