ტრანსფორმატორის მოდელების წარმატების შემდეგ NLP ამოცანების გადასაჭრელად, იგივე ან მსგავსი არქიტექტურები იქნა გამოყენებული კომპიუტერული ხედვის ამოცანებისთვის. იზრდება ინტერესი მოდელების შექმნის მიმართ, რომლებიც * აერთიანებს* ხედვას და ბუნებრივი ენის შესაძლებლობებს. ერთ-ერთი ასეთი მცდელობა OpenAI-მ გააკეთა და მას CLIP და DALL.E ჰქვია.
კონტრასტული გამოსახულების წინასწარი ტრენინგი (CLIP)
CLIP-ის მთავარი იდეაა შეგეძლოთ ტექსტური მოთხოვნის შედარება სურათთან და განსაზღვროთ რამდენად შეესაბამება სურათი მოთხოვნას.
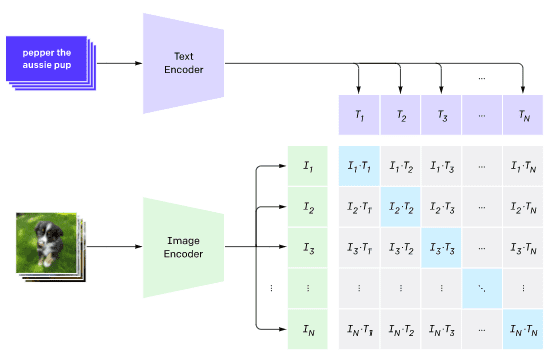
სურათი ეს ბლოგის პოსტი-დან
მოდელი ივარჯიშება ინტერნეტიდან მოპოვებულ სურათებზე და მათ წარწერებზე. თითოეული პარტიისთვის ვიღებთ N წყვილს (სურათს, ტექსტს) და ვაკონვერტირებთ მათ ვექტორულ გამოსახულებებად I1,..., IN / T1_, ...__HTML_7. შემდეგ ეს წარმოდგენები ერთმანეთს ემთხვევა. დანაკარგის ფუნქცია განისაზღვრება იმისათვის, რომ მაქსიმალურად გაზარდოს კოსინუსური მსგავსება ვექტორებს შორის, რომლებიც შეესაბამება ერთ წყვილს (მაგ. Ii და Ti) და მინიმუმამდე დაიყვანოს კოსინუსური მსგავსება ყველა სხვა წყვილს შორის. სწორედ ამიტომ ამ მიდგომას ეწოდება კონტრასტული.
CLIP მოდელი/ბიბლიოთეკა ხელმისაწვდომია OpenAI GitHub-დან. მიდგომა აღწერილია ეს ბლოგის პოსტი-ში და უფრო დეტალურად ეს ქაღალდი-ში.
მას შემდეგ, რაც ეს მოდელი წინასწარ იქნება მომზადებული, ჩვენ შეგვიძლია მივცეთ მას სურათების და ტექსტური მოთხოვნის პარტია და ის დაბრუნდება როგორც ტენზორი ალბათობით. CLIP შეიძლება გამოყენებულ იქნას რამდენიმე ამოცანისთვის:
გამოსახულების კლასიფიკაცია
დავუშვათ, ჩვენ გვჭირდება სურათების კლასიფიკაცია, ვთქვათ, კატებს, ძაღლებს და ადამიანებს შორის. ამ შემთხვევაში, ჩვენ შეგვიძლია მივცეთ მოდელს გამოსახულება, ხოლო ტექსტის სერიის მოთხოვნა: "კატის სურათი", "ძაღლის სურათი", "ადამიანის სურათი". შედეგად მიღებული 3 ალბათობის ვექტორში ჩვენ უბრალოდ უნდა ავირჩიოთ ყველაზე მაღალი მნიშვნელობის მქონე ინდექსი.
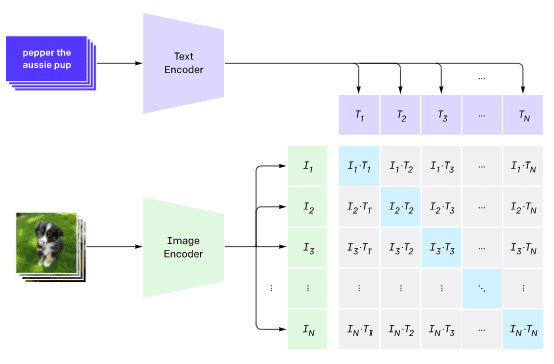
სურათი ეს ბლოგის პოსტი-დან
ტექსტზე დაფუძნებული სურათების ძიება
ჩვენ ასევე შეგვიძლია გავაკეთოთ პირიქით. თუ ჩვენ გვაქვს სურათების კოლექცია, შეგვიძლია გადავიტანოთ ეს კოლექცია მოდელს, ხოლო ტექსტური მოთხოვნა - ეს მოგვცემს სურათს, რომელიც ყველაზე მეტად ჰგავს მოცემულ მოთხოვნას.
მაგალითი: CLIP-ის გამოყენება გამოსახულების კლასიფიკაციისა და სურათების საძიებლად
გახსენით Clip.ipynb ბლოკნოტი, რომ ნახოთ CLIP მოქმედებაში.
სურათების გენერაცია VQGAN+ CLIP-ით
CLIP ასევე შეიძლება გამოყენებულ იქნას გამოსახულების გენერირებისთვის ტექსტური მოთხოვნისგან. ამისათვის ჩვენ გვჭირდება გენერატორის მოდელი, რომელიც შეძლებს სურათების გენერირებას ვექტორული შეყვანის საფუძველზე. ერთ-ერთ ასეთ მოდელს ჰქვია VQGAN (Vector-Quantized GAN).
VQGAN-ის ძირითადი იდეები, რომლებიც განასხვავებს მას ჩვეულებრივი GAN-სგან, შემდეგია:
- ავტორეგრესიული ტრანსფორმატორის არქიტექტურის გამოყენება კონტექსტით მდიდარი ვიზუალური ნაწილების თანმიმდევრობის შესაქმნელად, რომლებიც ქმნიან სურათს. ამ ვიზუალურ ნაწილებს თავის მხრივ ისწავლის CNN
- გამოიყენეთ ქვეგამოსახულების დისკრიმინატორი, რომელიც აღმოაჩენს არის თუ არა გამოსახულების ნაწილები "რეალური" და "ყალბი" (განსხვავებით "ყველა ან არაფერი" მიდგომისგან ტრადიციულ GAN-ში).
შეიტყვეთ მეტი VQGAN-ის შესახებ მოთვინიერება ტრანსფორმატორები ვებსაიტზე.
ერთ-ერთი მნიშვნელოვანი განსხვავება VQGAN-სა და ტრადიციულ GAN-ს შორის არის ის, რომ ამ უკანასკნელს შეუძლია შექმნას ღირსეული გამოსახულება ნებისმიერი შეყვანის ვექტორიდან, ხოლო VQGAN, სავარაუდოდ, წარმოქმნის სურათს, რომელიც არ იქნება თანმიმდევრული. ამრიგად, ჩვენ გვჭირდება შემდგომი წარმართვა სურათის შექმნის პროცესზე და ეს შეიძლება გაკეთდეს CLIP-ის გამოყენებით.
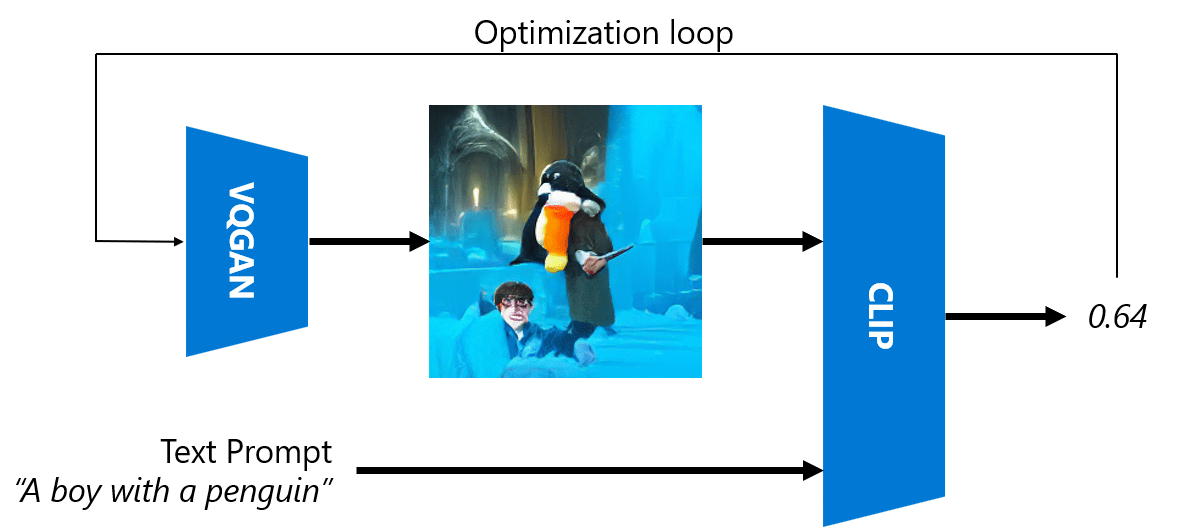
ტექსტური მოთხოვნის შესაბამისი გამოსახულების შესაქმნელად, ვიწყებთ შემთხვევითი კოდირების ვექტორით, რომელიც გადადის VQGAN-ში გამოსახულების შესაქმნელად. შემდეგ CLIP გამოიყენება დაკარგვის ფუნქციის შესაქმნელად, რომელიც აჩვენებს, რამდენად შეესაბამება სურათი ტექსტურ მოთხოვნას. მიზანი მაშინ არის ამ დანაკარგის მინიმუმამდე შემცირება, უკანა გამრავლების გამოყენებით შეყვანის ვექტორის პარამეტრების დასარეგულირებლად.
შესანიშნავი ბიბლიოთეკა, რომელიც ახორციელებს VQGAN+CLIP-ს არის პიქსრეი
 |  |  |
|---|---|---|
| სურათი გენერირებული მოწოდებიდან ახალი ლიტერატურის მასწავლებლის აკვარელიანი პორტრეტი წიგნით | სურათი გენერირებული მოწოდებიდან კომპიუტერული მეცნიერების ახალგაზრდა ქალი მასწავლებლის ზეთის პორტრეტი კომპიუტერით | სურათი შექმნილია მოთხოვნიდან მათემატიკის ძველი მამაკაცის მასწავლებლის ზეთის პორტრეტი დაფის წინ |
სურათები Artificial Teachers კოლექციიდან დიმიტრი სოშნიკოვი-ის მიერ
DALL-E
DALL-E 1
DALL-E არის GPT-3-ის ვერსია, რომელიც გაწვრთნილი იყო მოთხოვნიდან სურათების გენერირებისთვის. ის გაწვრთნილი იყო 12 მილიარდი პარამეტრით.
CLIP-ისგან განსხვავებით, DALL-E იღებს როგორც ტექსტს, ასევე სურათს, როგორც ნიშნების ერთი ნაკადი, როგორც სურათებისთვის, ასევე ტექსტისთვის. ამიტომ, მრავალი მოთხოვნისგან, შეგიძლიათ შექმნათ სურათები ტექსტის საფუძველზე.
DALL-E 2
მთავარი განსხვავება DALL.E 1-სა და 2-ს შორის არის ის, რომ ის უფრო რეალისტურ სურათებს და ხელოვნებას ქმნის.
სურათების თაობის მაგალითები DALL-E-ით:
|  |  |  |
|---|---|---|
| სურათი გენერირებული მოწოდებიდან ახალი ლიტერატურის მასწავლებლის აკვარელიანი პორტრეტი წიგნით | სურათი გენერირებული მოწოდებიდან კომპიუტერული მეცნიერების ახალგაზრდა ქალი მასწავლებლის ზეთის პორტრეტი კომპიუტერით | სურათი შექმნილია მოთხოვნიდან მათემატიკის ძველი მამაკაცის მასწავლებლის ზეთის პორტრეტი დაფის წინ |
ცნობები
- VQGAN ქაღალდი: ტრანსფორმატორების მოთვინიერება მაღალი გარჩევადობის გამოსახულების სინთეზისთვის
- CLIP ქაღალდი: ტრანსფერული ვიზუალური მოდელების სწავლა ბუნებრივი ენის ზედამხედველობიდან