როგორც აღვნიშნეთ, ჩვენ ყურადღებას გავამახვილებთ ტექსტის კლასიფიკაციის მარტივ ამოცანაზე AG_NEWS მონაცემთა ბაზაზე, რომელიც არის ახალი ამბების სათაურების კლასიფიკაცია 4 კატეგორიაში: მსოფლიო, სპორტი, ბიზნესი და მეცნიერება/ტექნიკა.
The Dataset
ეს მონაცემთა ნაკრები ჩაშენებულია ჩირაღდნის ტექსტი მოდულში, ასე რომ ჩვენ შეგვიძლია მასზე წვდომა მარტივად.
იტვირთება…აქ, train_dataset და test_dataset შეიცავს კოლექციებს, რომლებიც აბრუნებენ ლეიბლის (კლასის რაოდენობა) და ტექსტის წყვილებს, მაგალითად:
იტვირთება…გამოტანა
(3,
"Wall St. Bears Claw Back Into the Black (Reuters) Reuters - Short-sellers, Wall Street's dwindling\\band of ultra-cynics, are seeing green again.")მოდით, დავბეჭდოთ პირველი 10 ახალი სათაური ჩვენი მონაცემთა ბაზიდან:
იტვირთება…გამოტანა
**Sci/Tech** -> Wall St. Bears Claw Back Into the Black (Reuters) Reuters - Short-sellers, Wall Street's dwindling\band of ultra-cynics, are seeing green again.
**Sci/Tech** -> Carlyle Looks Toward Commercial Aerospace (Reuters) Reuters - Private investment firm Carlyle Group,\which has a reputation for making well-timed and occasionally\controversial plays in the defense industry, has quietly placed\its bets on another part of the market.
**Sci/Tech** -> Oil and Economy Cloud Stocks' Outlook (Reuters) Reuters - Soaring crude prices plus worries\about the economy and the outlook for earnings are expected to\hang over the stock market next week during the depth of the\summer doldrums.
**Sci/Tech** -> Iraq Halts Oil Exports from Main Southern Pipeline (Reuters) Reuters - Authorities have halted oil export\flows from the main pipeline in southern Iraq after\intelligence showed a rebel militia could strike\infrastructure, an oil official said on Saturday.
**Sci/Tech** -> Oil prices soar to all-time record, posing new menace to US economy (AFP) AFP - Tearaway world oil prices, toppling records and straining wallets, present a new economic menace barely three months before the US presidential elections.
იმის გამო, რომ მონაცემთა ნაკრები არის განმეორებადი, თუ ჩვენ გვინდა მონაცემების მრავალჯერ გამოყენება, უნდა გადავიტანოთ სიაში:
იტვირთება…ტოკენიზაცია
ახლა ჩვენ უნდა გადავიყვანოთ ტექსტი რიცხვებად, რომლებიც შეიძლება იყოს წარმოდგენილი როგორც ტენსორები. თუ გვინდა სიტყვების დონეზე წარმოდგენა, ჩვენ უნდა გავაკეთოთ ორი რამ:
- გამოიყენეთ ტოკენიზატორი ტექსტის ტოკენებად გასაყოფად
- შექმენით ამ ნიშნების ლექსიკა.
იტვირთება…გამოტანა
['he', 'said', 'hello']იტვირთება…ლექსიკის გამოყენებით, ჩვენ შეგვიძლია მარტივად დავაშიფროთ ტოკენიზებული სტრიქონი რიცხვების ნაკრებში:
იტვირთება…გამოტანა
Vocab size if 95810
[599, 3279, 97, 1220, 329, 225, 7368]სიტყვების ჩანთა ტექსტის წარმოდგენა
იმის გამო, რომ სიტყვები წარმოადგენს მნიშვნელობას, ზოგჯერ ჩვენ შეგვიძლია გავარკვიოთ ტექსტის მნიშვნელობა მხოლოდ ცალკეული სიტყვების დათვალიერებით, წინადადებაში მათი თანმიმდევრობის მიუხედავად. მაგალითად, ახალი ამბების კლასიფიკაციისას, სიტყვები, როგორიცაა ამინდი, თოვლი, სავარაუდოდ მიუთითებს * ამინდის პროგნოზს*, ხოლო სიტყვები, როგორიცაა * აქციები *, *დოლარი * ჩაითვლება ფინანსურ სიახლეებში.
Bag of Words (BoW) ვექტორული წარმოდგენა არის ყველაზე ხშირად გამოყენებული ტრადიციული ვექტორული წარმოდგენა. თითოეული სიტყვა უკავშირდება ვექტორულ ინდექსს, ვექტორული ელემენტი შეიცავს მოცემულ დოკუმენტში სიტყვის გაჩენის რაოდენობას.
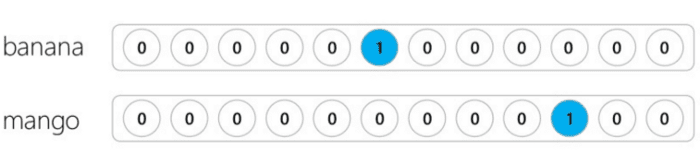
შენიშვნა: თქვენ ასევე შეგიძლიათ BoW წარმოიდგინოთ, როგორც ტექსტში ცალკეული სიტყვებისთვის one-hot კოდირებული ვექტორის ჯამი.
ქვემოთ მოცემულია მაგალითი იმისა, თუ როგორ უნდა გენერირება სიტყვის წარმოდგენის ტომარა Scikit Learn პითონის ბიბლიოთეკის გამოყენებით:
იტვირთება…გამოტანა
array([[1, 1, 0, 2, 0, 0, 0, 0, 0]], dtype=int64)ჩვენი AG_NEWS მონაცემთა ნაკრების ვექტორული წარმოდგენიდან სიტყვების ჩანთა ვექტორის გამოსათვლელად, შეგვიძლია გამოვიყენოთ შემდეგი ფუნქცია:
იტვირთება…გამოტანა
tensor([2., 1., 2., ..., 0., 0., 0.])
შენიშვნა: აქ ჩვენ ვიყენებთ გლობალურ
vocab_sizeცვლადს ლექსიკის ნაგულისხმევი ზომის დასაზუსტებლად. ვინაიდან ხშირად ლექსიკის ზომა საკმაოდ დიდია, შეგვიძლია შევზღუდოთ ლექსიკის ზომა ყველაზე ხშირი სიტყვებით. სცადეთ შეამციროთvocab_sizeმნიშვნელობა და გაუშვათ ქვემოთ მოცემული კოდი და ნახეთ, როგორ იმოქმედებს ეს სიზუსტეზე. თქვენ უნდა ელოდოთ სიზუსტის გარკვეულ ვარდნას, მაგრამ არა დრამატულს, უფრო მაღალი შესრულების ნაცვლად.
სასწავლო BoW კლასიფიკატორი
ახლა, როდესაც ვისწავლეთ, როგორ შევქმნათ ჩვენი ტექსტის ჩანთა-of-words წარმოდგენა, მოდით მოვამზადოთ კლასიფიკატორი მის თავზე. უპირველეს ყოვლისა, ჩვენ უნდა გადავიყვანოთ ჩვენი მონაცემთა ნაკრები ტრენინგისთვის ისე, რომ ყველა პოზიციური ვექტორული წარმოდგენა გარდაიქმნას სიტყვების ჩანთაში. ამის მიღწევა შესაძლებელია bowify ფუნქციის collate_fn პარამეტრის სახით გადაცემით სტანდარტულ ჩირაღდნ DataLoader-ზე:
იტვირთება…ახლა მოდით განვსაზღვროთ მარტივი კლასიფიკატორის ნერვული ქსელი, რომელიც შეიცავს ერთ ხაზოვან ფენას. შეყვანის ვექტორის ზომა უდრის vocab_size-ს, ხოლო გამომავალი ზომა შეესაბამება კლასების რაოდენობას (4). იმის გამო, რომ ჩვენ ვხსნით კლასიფიკაციის ამოცანას, საბოლოო აქტივაციის ფუნქციაა LogSoftmax().
იტვირთება…ახლა ჩვენ განვსაზღვრავთ სტანდარტულ PyTorch სასწავლო ციკლს. იმის გამო, რომ ჩვენი მონაცემთა ბაზა საკმაოდ დიდია, ჩვენი სწავლების მიზნით ჩვენ ვივარჯიშებთ მხოლოდ ერთი ეპოქისთვის, ზოგჯერ კი ეპოქზე ნაკლებ დროსაც (epoch_size პარამეტრის მითითება საშუალებას გვაძლევს შევზღუდოთ ტრენინგი). ჩვენ ასევე მოვახსენებთ ვარჯიშის დროს დაგროვილ სიზუსტეს; მოხსენების სიხშირე მითითებულია report_freq პარამეტრის გამოყენებით.
იტვირთება…იტვირთება…გამოტანა
3200: acc=0.8028125
6400: acc=0.8371875
9600: acc=0.8534375
12800: acc=0.85765625
(0.026090790722161722, 0.8620069296375267)ბიგრამები, ტრიგრამები და ნ-გრამები
ერთი შეზღუდვა სიტყვების მიდგომის არის ის, რომ ზოგიერთი სიტყვა მრავალსიტყვიანი გამონათქვამის ნაწილია, მაგალითად, სიტყვა „ჰოტ-დოგს“ აქვს სრულიად განსხვავებული მნიშვნელობა, ვიდრე სიტყვებს „ცხელი“ და „ძაღლი“ სხვა კონტექსტში. თუ ჩვენ წარმოვადგენთ სიტყვებს "ცხელი" და "ძაღლი" ყოველთვის ერთი და იგივე ვექტორებით, ამან შეიძლება დააბნიოს ჩვენი მოდელი.
ამის გადასაჭრელად N-გრამების წარმოდგენები ხშირად გამოიყენება დოკუმენტების კლასიფიკაციის მეთოდებში, სადაც თითოეული სიტყვის, ორსიტყვიანი ან სამსიტყვიანი სიხშირე სასარგებლო თვისებაა კლასიფიკატორების ტრენინგისთვის. მაგალითად, ბიგრამების წარმოდგენისას, ორიგინალური სიტყვების გარდა, ლექსიკას დავამატებთ ყველა სიტყვათა წყვილს.
ქვემოთ მოცემულია მაგალითი იმისა, თუ როგორ უნდა შექმნათ სიტყვების წარმოდგენის ბიგრამიანი ტომარა Scikit Learn-ის გამოყენებით:
იტვირთება…გამოტანა
Vocabulary:
{'i': 7, 'like': 11, 'hot': 4, 'dogs': 2, 'i like': 8, 'like hot': 12, 'hot dogs': 5, 'the': 16, 'dog': 0, 'ran': 14, 'fast': 3, 'the dog': 17, 'dog ran': 1, 'ran fast': 15, 'its': 9, 'outside': 13, 'its hot': 10, 'hot outside': 6}
array([[1, 0, 1, 0, 2, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
dtype=int64)N-გრამის მიდგომის მთავარი ნაკლი არის ის, რომ ლექსიკის ზომა ძალიან სწრაფად იწყებს ზრდას. პრაქტიკაში, ჩვენ უნდა გავაერთიანოთ N-გრამის წარმოდგენა განზომილების შემცირების ზოგიერთ ტექნიკასთან, როგორიცაა embeddings, რომელსაც განვიხილავთ შემდეგ ერთეულში.
იმისათვის, რომ გამოვიყენოთ N-გრამის წარმოდგენა ჩვენს AG News მონაცემთა ბაზაში, ჩვენ უნდა შევქმნათ სპეციალური ngram ლექსიკა:
იტვირთება…გამოტანა
Bigram vocabulary length = 1308842
შემდეგ ჩვენ შეგვიძლია გამოვიყენოთ იგივე კოდი, როგორც ზემოთ, კლასიფიკატორის მოსამზადებლად, თუმცა, ეს იქნება ძალიან არაეფექტური მეხსიერება. შემდეგ განყოფილებაში ჩვენ მოვამზადებთ ბიგრამის კლასიფიკატორს ჩაშენების გამოყენებით.
შენიშვნა: თქვენ შეგიძლიათ დატოვოთ მხოლოდ ის ნგრამები, რომლებიც ჩნდება ტექსტში მითითებულზე მეტჯერ. ეს დარწმუნდება, რომ იშვიათი ბიგრამები გამოტოვებული იქნება და მნიშვნელოვნად შეამცირებს განზომილებას. ამისათვის დააყენეთ
min_freqპარამეტრი უფრო მაღალ მნიშვნელობაზე და დააკვირდით ლექსიკის ცვლილების ხანგრძლივობას.
ტერმინი სიხშირე ინვერსიული დოკუმენტის სიხშირე TF-IDF
BoW წარმომადგენლობაში სიტყვების გამოვლინებები თანაბრად იწონის, მიუხედავად თავად სიტყვისა. თუმცა, ცხადია, რომ ხშირი სიტყვები, როგორიცაა a, in და ა.შ. გაცილებით ნაკლებად მნიშვნელოვანია კლასიფიკაციისთვის, ვიდრე სპეციალიზებული ტერმინები. სინამდვილეში, NLP ამოცანების უმეტესობაში ზოგიერთი სიტყვა უფრო აქტუალურია, ვიდრე სხვები.
TF-IDF ნიშნავს ტერმინის სიხშირე - დოკუმენტის შებრუნებული სიხშირე (Term Frequency-Inverse Document Frequency). ეს არის სიტყვების ტომრის ვარიაცია, სადაც ორობითი 0/1 მნიშვნელობის ნაცვლად, რომელიც მიუთითებს სიტყვის გამოჩენაზე დოკუმენტში, გამოიყენება მცურავი წერტილის მნიშვნელობა, რომელიც დაკავშირებულია კორპუსში სიტყვების გაჩენის სიხშირესთან.
უფრო ფორმალურად, $w_{ij}$ $i$ სიტყვის წონა დოკუმენტში $j$ განისაზღვრება როგორც: $$ w_{ij} = tf_{ij}\times\log ({N\ მეტი df_i}) $$ სადაც
- $tf_{ij}$ არის $i$-ის შემთხვევების რაოდენობა $j$-ში, ანუ BoW მნიშვნელობა, რომელიც ადრე ვნახეთ.
- $N$ არის კოლექციაში არსებული დოკუმენტების რაოდენობა
- $df_i$ არის დოკუმენტების რაოდენობა, რომლებიც შეიცავს სიტყვას $i$ მთელ კოლექციაში
TF-IDF ღირებულება $w_{ij}$ იზრდება პროპორციულად, რამდენჯერაც გამოჩნდება სიტყვა დოკუმენტში და კომპენსირდება კორპუსში არსებული დოკუმენტების რაოდენობით, რომელიც შეიცავს სიტყვას, რაც ხელს უწყობს იმ ფაქტს, რომ ზოგიერთი სიტყვა უფრო ხშირად ჩნდება, ვიდრე სხვები. მაგალითად, თუ სიტყვა გამოჩნდება კოლექციის ყველა დოკუმენტში, $df_i=N$ და $w_{ij}=0$ და ეს ტერმინები სრულიად უგულებელყოფილი იქნება.
თქვენ შეგიძლიათ მარტივად შექმნათ ტექსტის TF-IDF ვექტორიზაცია Scikit Learn-ის გამოყენებით:
იტვირთება…გამოტანა
array([[0.43381609, 0. , 0.43381609, 0. , 0.65985664,
0.43381609, 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. ]])დასკვნა
თუმცა, მიუხედავად იმისა, რომ TF-IDF წარმოდგენები იძლევა სიხშირის წონას სხვადასხვა სიტყვებს, ისინი ვერ წარმოადგენენ მნიშვნელობას ან წესრიგს. როგორც ცნობილმა ენათმეცნიერმა J. R. Firth-მა თქვა 1935 წელს, „სიტყვის სრული მნიშვნელობა ყოველთვის კონტექსტურია და კონტექსტის გარდა მნიშვნელობის შესწავლა არ შეიძლება სერიოზულად იქნას მიღებული“. კურსზე მოგვიანებით ვისწავლით, თუ როგორ უნდა აღვიქვათ ტექსტიდან კონტექსტური ინფორმაცია ენის მოდელირების გამოყენებით.