სალექციო ვიქტორინა
ტექსტის კლასიფიკაცია
ამ განყოფილების პირველ ნაწილში ჩვენ ყურადღებას გავამახვილებთ ტექსტის კლასიფიკაციის ამოცანაზე. ჩვენ გამოვიყენებთ AG News მონაცემთა ნაკრების, რომელიც შეიცავს შემდეგ სტატიებს:
- კატეგორია: მეცნიერება/ტექ
- სათაური: Ky. კომპანიამ მოიგო გრანტი პეპტიდების შესასწავლად (AP)
- Body: AP - ლუისვილის უნივერსიტეტის ქიმიის მკვლევარის მიერ დაარსებულმა კომპანიამ მოიპოვა გრანტი განვითარებისთვის...
ჩვენი მიზანი იქნება ახალი ამბების კლასიფიკაცია ტექსტის მიხედვით ერთ-ერთ კატეგორიად.
ტექსტის წარმოდგენა
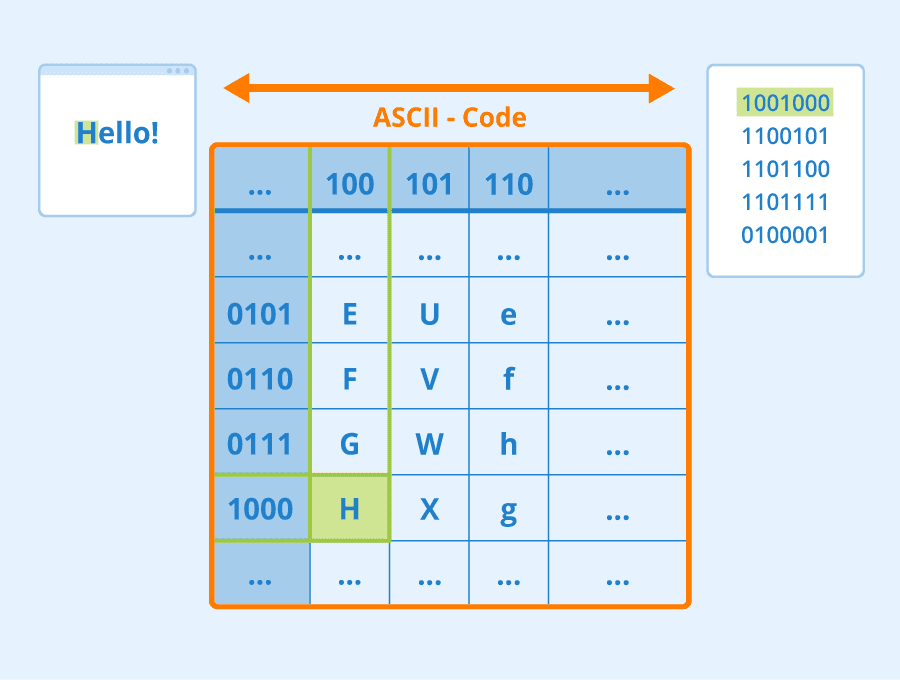
თუ ჩვენ გვსურს ბუნებრივი ენის დამუშავების (NLP) ამოცანები ნერვული ქსელებით გადავჭრათ, ტექსტის ტენზორებად წარმოდგენის გზა გვჭირდება. კომპიუტერები ტექსტურ სიმბოლოებს ისედაც წარმოადგენს რიცხვებად, რომლებიც ასახავს ეკრანზე არსებულ შრიფტებს ისეთი კოდირების გამოყენებით, როგორიცაა ASCII ან UTF-8.
გამოსახულების წყარო
როგორც ადამიანებს, ჩვენ გვესმის, თუ რას წარმოადგენს თითოეული ასო და როგორ ერთიანდება სიმბოლოები წინადადებაში სიტყვების შესაქმნელად. თუმცა, კომპიუტერებს თავისთავად არ აქვს ასეთი გაგება და ნერვულმა ქსელმა უნდა ისწავლოს მნიშვნელობა წვრთნის (training) პროცესში.
აქედან გამომდინარე, ჩვენ შეგვიძლია გამოვიყენოთ სხვადასხვა მიდგომა ტექსტის წარმოდგენისას:
- სიმბოლოების დონის წარმოდგენა, როდესაც ჩვენ წარმოვადგენთ ტექსტს თითოეული სიმბოლოს რიცხვად გარდაქმნით. თუ ჩვენს ტექსტურ კორპუსში C რაოდენობის სხვადასხვა სიმბოლო გვაქვს, სიტყვა Hello წარმოდგენილი იქნება 5xC ტენზორით. თითოეული ასო შეესაბამება ტენზორის სვეტს one-hot კოდირებით.
- სიტყვის დონის წარმოდგენა, რომელშიც ჩვენ ვქმნით ჩვენს ტექსტში არსებული ყველა სიტყვისგან შემდგარ ლექსიკონს და შემდეგ წარმოვადგენთ სიტყვებს one-hot კოდირების გამოყენებით. ეს მიდგომა გარკვეულწილად უკეთესია, რადგან თითოეულ ასოს თავისთავად დიდი მნიშვნელობა არ აქვს და ამგვარად, უფრო მაღალი დონის სემანტიკური ცნებების (სიტყვების) გამოყენებით, ჩვენ ვამარტივებთ ამოცანას ნერვული ქსელისთვის. თუმცა, ლექსიკონის დიდი ზომის გამო, საქმე გვაქვს მაღალგანზომილებიან მეჩხერ (sparse) ტენზორებთან.
წარმოდგენის ტიპის მიუხედავად, პირველ რიგში ტექსტი უნდა დავყოთ ტოკენების თანმიმდევრობად, სადაც თითოეული ტოკენი შეიძლება იყოს სიმბოლო, სიტყვა ან სიტყვის ნაწილი. შემდეგ ტოკენს გარდავქმნით რიცხვად (როგორც წესი, ლექსიკონის მეშვეობით) და ეს რიცხვი შეგვიძლია მივაწოდოთ ნერვულ ქსელს one-hot კოდირების სახით.
N-გრამები
ბუნებრივ ენაში სიტყვების ზუსტი მნიშვნელობის დადგენა შესაძლებელია მხოლოდ კონტექსტში. მაგალითად, ნერვული ქსელის და თევზავის ქსელის მნიშვნელობა სრულიად განსხვავებულია. ამის გათვალისწინების ერთ-ერთი გზა არის სიტყვის წყვილებზე ჩვენი მოდელის აგება და სიტყვების წყვილების ცალკე ლექსიკური ნიშნების გათვალისწინება. ამგვარად, წინადადება მე მიყვარს სათევზაოდ წასვლა წარმოდგენილი იქნება ნიშნების შემდეგი თანმიმდევრობით: მომწონს, მომწონს, წასვლა, სათევზაოდ წასვლა. ამ მიდგომის პრობლემა ის არის, რომ ლექსიკონის ზომა მნიშვნელოვნად იზრდება და კომბინაციები, როგორიცაა go fishing და go shopping წარმოდგენილია სხვადასხვა ნიშნით, რომლებიც არ იზიარებენ რაიმე სემანტიკურ მსგავსებას ერთი და იგივე ზმნის მიუხედავად.
ზოგიერთ შემთხვევაში, შეიძლება განვიხილოთ ტრიგრამის გამოყენება - სამი სიტყვის კომბინაციები - ასევე. ამრიგად, მიდგომას ხშირად უწოდებენ n-გრამს. ასევე, აზრი აქვს n-გრამების გამოყენებას სიმბოლოების დონის გამოსახულებით, ამ შემთხვევაში n-გრამები უხეშად შეესაბამება სხვადასხვა სილაბუსებს.
სიტყვების ტომარა და TF/IDF
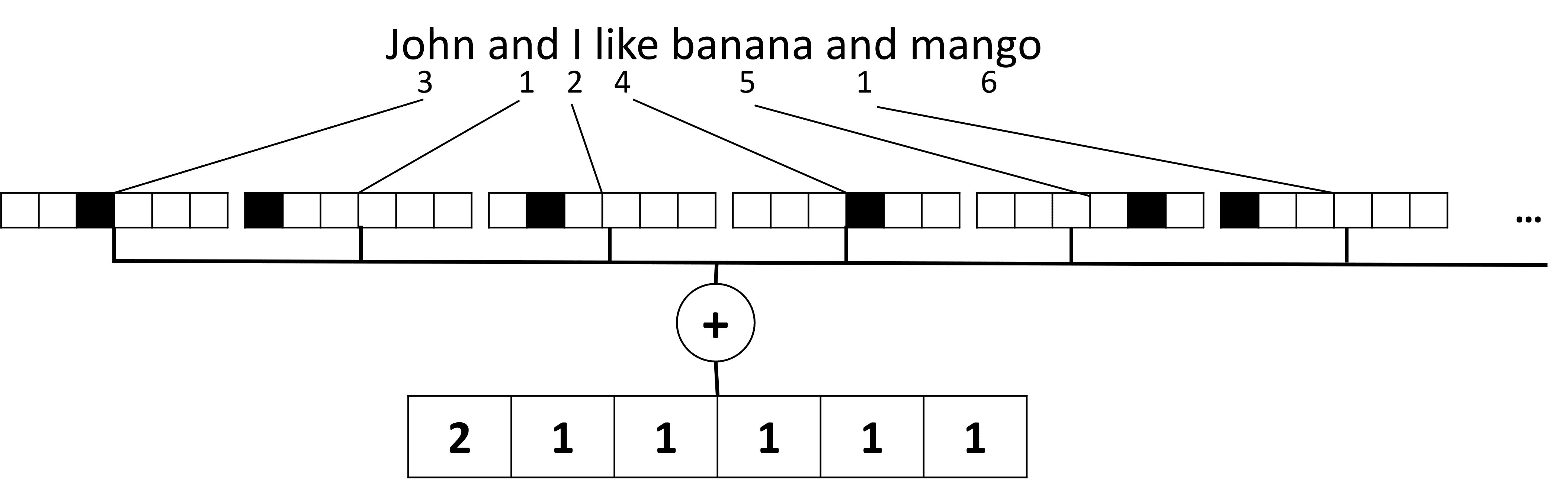
ტექსტის კლასიფიკაციის მსგავსი ამოცანების ამოხსნისას, ჩვენ უნდა შეგვეძლოს ტექსტის წარმოდგენა ერთი ფიქსირებული ზომის ვექტორით, რომელსაც გამოვიყენებთ, როგორც შესატანს საბოლოო მკვრივი კლასიფიკატორისთვის. ამის გაკეთების ერთ-ერთი უმარტივესი გზაა ყველა ინდივიდუალური სიტყვის წარმოდგენის გაერთიანება, მაგ. მათი დამატებით. თუ თითოეულ სიტყვას დავამატებთ one-hot დაშიფვრას, მივიღებთ სიხშირეების ვექტორს, რომელიც აჩვენებს რამდენჯერ გამოჩნდება თითოეული სიტყვა ტექსტში. ტექსტის ასეთ წარმოდგენას ეწოდება სიტყვების ტომარა (BoW).
ავტორის სურათი
BoW არსებითად ასახავს, თუ რომელი სიტყვები ჩნდება ტექსტში და რა რაოდენობით, რაც ნამდვილად შეიძლება იყოს კარგი მითითება იმისა, თუ რას ეხება ტექსტი. მაგალითად, ახალი ამბების სტატია პოლიტიკაზე, სავარაუდოდ, შეიცავს სიტყვებს, როგორიცაა president და country, ხოლო სამეცნიერო პუბლიკაციას ექნება მსგავსი რამ collider, discover და ა.შ. ამრიგად, სიტყვების სიხშირე ხშირ შემთხვევაში შეიძლება იყოს ტექსტის შინაარსის კარგი მაჩვენებელი.
BoW-ის პრობლემა ის არის, რომ ზოგიერთი ჩვეულებრივი სიტყვა, როგორიცაა and, is და ა.შ. ჩნდება ტექსტების უმეტესობაში და მათ აქვთ უმაღლესი სიხშირეები, ნიღბავს სიტყვებს, რომლებიც მართლაც მნიშვნელოვანია. ჩვენ შეგვიძლია შევამციროთ ამ სიტყვების მნიშვნელობა იმ სიხშირის გათვალისწინებით, რომლითაც სიტყვები გვხვდება დოკუმენტების მთელ კოლექციაში. ეს არის TF/IDF მიდგომის მთავარი იდეა, რომელიც უფრო დეტალურად არის გაშუქებული ამ გაკვეთილზე მიმაგრებულ რვეულებში.
თუმცა, არცერთ ამ მიდგომას არ შეუძლია სრულად გაითვალისწინოს ტექსტის სემანტიკა. ამისათვის ჩვენ გვჭირდება უფრო მძლავრი ნერვული ქსელების მოდელები, რაზეც მოგვიანებით განვიხილავთ ამ სექციაში.
სავარჯიშოები: ტექსტის წარმოდგენა
განაგრძეთ სწავლა შემდეგ რვეულებში:
- ტექსტის წარმოდგენა PyTorch-ით
- ტექსტის წარმოდგენა TensorFlow-ით
დასკვნა
აქამდე ჩვენ შევისწავლეთ ტექნიკა, რომელსაც შეუძლია სიხშირის წონის დამატება სხვადასხვა სიტყვებს. თუმცა, მათ არ შეუძლიათ წარმოადგინონ მნიშვნელობა ან წესრიგი. როგორც 1935 წელს თქვა ცნობილმა ენათმეცნიერმა J. R. Firth-მა, „სიტყვის სრული მნიშვნელობა ყოველთვის კონტექსტუალურია და კონტექსტის გარდა მნიშვნელობის შესწავლა არ შეიძლება სერიოზულად იქნას მიღებული“. კურსზე მოგვიანებით ვისწავლით, თუ როგორ უნდა აღვიქვათ ტექსტიდან კონტექსტური ინფორმაცია ენის მოდელირების გამოყენებით.
გამოწვევა
სცადეთ სხვა სავარჯიშოები სიტყვების ჩანთა და მონაცემთა სხვადასხვა მოდელების გამოყენებით. თქვენ შეიძლება შთაგონებული იყოთ ამ კონკურსი Kaggle-ზე
ლექციის შემდგომი ვიქტორინა
მიმოხილვა და თვითშესწავლა
ივარჯიშეთ თქვენი უნარ-ჩვევები ტექსტის ჩაშენების და სიტყვების ჩანთის ტექნიკით Microsoft Learn-ზე