შინაური ცხოველის სახეების # კლასიფიკაცია
ლაბორატორიული დავალება AI დამწყებთათვის სასწავლო პროგრამა-დან.
ამ დავალებაში გავამახვილებთ ყურადღებას შედარებით მარტივ კლასიფიკაციის ამოცანაზე - შინაური ცხოველის სახეების კლასიფიკაციაზე. ჩვენ გამოვიყენებთ Oxford-IIIT Pet Dataset-ს, რომელიც შეიცავს 37 სხვადასხვა ჯიშის ძაღლებისა და კატების სურათებს. დავიწყოთ მონაცემთა ნაკრების ჩამოტვირთვისა და ვიზუალიზაციით.
შენიშვნა: Oxford-IIIT შინაური ცხოველების მონაცემთა ნაკრები შეიცავს შინაური ცხოველების სრულ სურათებს. სურათები დალაგდება ჯიშის მიხედვით ამოღებულ საქაღალდეში.
იტვირთება…გამოტანა
--2022-02-17 12:32:43-- https://thor.robots.ox.ac.uk/~vgg/data/pets/images.tar.gz
Resolving mslearntensorflowlp.blob.core.windows.net... 20.150.90.68
Connecting to mslearntensorflowlp.blob.core.windows.net|20.150.90.68|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 24483412 (23M) [application/x-gzip]
Saving to: ‘images.tar.gz’
images.tar.gz 100%[===================>] 23.35M 12.5MB/s in 1.9s
2022-02-17 12:32:45 (12.5 MB/s) - ‘images.tar.gz’ saved [24483412/24483412]
ჩვენ განვსაზღვრავთ ზოგად ფუნქციას სიიდან სურათების სერიის საჩვენებლად:
იტვირთება…ახლა მოდით გადავხედოთ კლასის ყველა ქვედირექტორიას და დავხატოთ თითოეული კლასის პირველი რამდენიმე სურათი:
იტვირთება…მოდით ასევე განვსაზღვროთ კლასების რაოდენობა ჩვენს მონაცემთა ბაზაში:
იტვირთება…გამოტანა
35მონაცემთა ნაკრების მომზადება ღრმა სწავლისთვის
ჩვენი ნერვული ქსელის სწავლების დასაწყებად, ჩვენ უნდა გადავიყვანოთ ყველა სურათი ტენსორებად და ასევე შევქმნათ ეტიკეტების შესაბამისი ტენსორები (კლასის ნომრები). Most neural network frameworks contain simple tools for dealing with images:
- In Tensorflow, use
tf.keras.preprocessing.image_dataset_from_directory - In PyTorch, use
torchvision.datasets.ImageFolder
როგორც ზემოთ მოყვანილი სურათებიდან ხედავთ, ყველა მათგანი ახლოსაა კვადრატულ გამოსახულების თანაფარდობასთან, ამიტომ ჩვენ უნდა შევცვალოთ ყველა სურათის ზომა კვადრატულ ზომამდე. ასევე, ჩვენ შეგვიძლია სურათების ორგანიზება მინი პატჩებში.
იტვირთება…ახლა ჩვენ უნდა გავყოთ მონაცემთა ბაზა მატარებლისა და ტესტის ნაწილებად:
იტვირთება…ახლა მოდით დავბეჭდოთ ტენსორების ზომა ჩვენს მონაცემთა ბაზაში. თუ ყველაფერი სწორად გააკეთე, სასწავლო ელემენტების ზომა უნდა იყოს
(batch_size,image_size,image_size,3)Tensorflow-სთვის,batch_size,3,image_size,image_sizePyTorch-ისთვისbatch_sizeლეიბლებისთვის
ეტიკეტები უნდა შეიცავდეს კლასების რაოდენობას.
იტვირთება…იტვირთება…გამოტანა
<Figure size 3024x2016 with 7 Axes><Figure size 3024x2016 with 7 Axes><Figure size 3024x2016 with 7 Axes>განსაზღვრეთ ნერვული ქსელი
For image classification, you should probably define a convolutional neural network with several layers. რას მივაქციოთ თვალი:
- Keep in mind the pyramid architecture, i.e. number of filters should increase as you go deeper
- არ დაგავიწყდეთ აქტივაციის ფუნქციები ფენებს შორის (ReLU) და Max Pooling
- საბოლოო კლასიფიკატორი შეიძლება იყოს ფარული შრეებით ან მის გარეშე, მაგრამ გამომავალი ნეირონების რაოდენობა უნდა იყოს კლასების რაოდენობის ტოლი.
მნიშვნელოვანი ის არის, რომ სწორად მივიღოთ აქტივაციის ფუნქცია ბოლო ფენაზე + დაკარგვის ფუნქცია:
- Tensorflow-ში შეგიძლიათ გამოიყენოთ
softmaxროგორც გააქტიურება დაsparse_categorical_crossentropyროგორც დაკარგვა. განსხვავება იშვიათ კატეგორიულ ჯვარედინი ენტროპიასა და არასპარსს შორის არის ის, რომ პირველი მოელის გამომავალს, როგორც კლასის რაოდენობას და არა როგორც one-hot ვექტორს. - PyTorch-ში შეგიძლიათ გქონდეთ საბოლოო ფენა აქტივაციის ფუნქციის გარეშე და გამოიყენოთ
CrossEntropyLossდაკარგვის ფუნქცია. ეს ფუნქცია ავტომატურად მოქმედებს softmax-ზე.
იტვირთება…ავარჯიშეთ ნერვული ქსელი
ახლა ჩვენ მზად ვართ გავავარჯიშოთ ნერვული ქსელი. ტრენინგის დროს, გთხოვთ, შეაგროვოთ მატარებლის სიზუსტე და ტესტის მონაცემები თითოეულ ეპოქაზე და შემდეგ დახაზოთ სიზუსტე, რათა ნახოთ, არის თუ არა გადაჭარბებული მორგება.
ტრენინგის დასაჩქარებლად, თქვენ უნდა გამოიყენოთ GPU, თუ ეს შესაძლებელია. მიუხედავად იმისა, რომ TensorFlow/Keras ავტომატურად გამოიყენებს GPU-ს, PyTorch-ში თქვენ უნდა გადაიტანოთ როგორც მოდელი, ასევე მონაცემები GPU-ზე ტრენინგის დროს
.to()მეთოდის გამოყენებით, რათა ისარგებლოთ GPU აჩქარებით.
იტვირთება…იტვირთება…გამოტანა
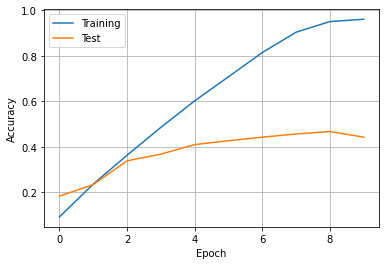
რას იტყვით ზედმეტად მორგებაზე? რა შეიძლება გაკეთდეს მოდელის სიზუსტის გასაუმჯობესებლად
სურვილისამებრ: გამოთვალეთ Top3 სიზუსტე
ამ სავარჯიშოში ჩვენ საქმე გვქონდა კლასიფიკაციასთან საკმაოდ მაღალი რაოდენობის კლასებთან (35), ამიტომ ჩვენი შედეგი - დაახლოებით 50% ვალიდაციის სიზუსტე - საკმაოდ კარგია. სტანდარტულ ImageNet მონაცემთა ბაზას აქვს კიდევ უფრო მეტი - 1000 კლასი.
ასეთ შემთხვევებში ძნელია იმის უზრუნველყოფა, რომ მოდელი ყოველთვის სწორად პროგნოზირებს კლასს. არის შემთხვევები, როდესაც ორი ჯიში ძალიან ჰგავს ერთმანეთს და მოდელი აბრუნებს ძალიან მსგავს ალბათობას (მაგ., 0.45 და 0.43). თუ გავზომავთ სტანდარტულ სიზუსტეს, ეს ჩაითვლება არასწორ შემთხვევად, მიუხედავად იმისა, რომ მოდელმა ძალიან მცირე შეცდომა დაუშვა. ჩვენ ხშირად ვზომავთ სხვა მეტრიკას - სიზუსტეს მოდელის 3 ყველაზე სავარაუდო პროგნოზის ფარგლებში.
ჩვენ მიგვაჩნია, რომ შემთხვევა ზუსტია, თუ სამიზნე ეტიკეტი შეიცავს ტოპ 3 მოდელის პროგნოზს.
სატესტო მონაცემთა ნაკრების ტოპ-3 სიზუსტის გამოსათვლელად, თქვენ ხელით უნდა გადახვიდეთ მონაცემთა ბაზაში, გამოიყენოთ ნერვული ქსელი პროგნოზის მისაღებად და შემდეგ გააკეთოთ გამოთვლები. რამდენიმე მინიშნება:
- Tensorflow-ში გამოიყენეთ
tf.nn.in_top_kფუნქცია, რომ ნახოთpredictions(მოდელის გამომავალი) არის თუ არა top-k-ში (გაატარეთk=3პარამეტრად),targets-ის მიმართ. ეს ფუნქცია აბრუნებს ლოგიკური მნიშვნელობების ტენსორს, რომელიც შეიძლება გარდაიქმნასint-ადtf.cast-ის გამოყენებით და შემდეგ დაგროვდესtf.reduce_sum-ის გამოყენებით. - PyTorch-ში შეგიძლიათ გამოიყენოთ
torch.topkფუნქცია უფრო მაღალი ალბათობით კლასების ინდექსების მისაღებად და შემდეგ ნახოთ, ეკუთვნის თუ არა მათ სწორი კლასი. იხილეთ ეს დამატებითი მინიშნებებისთვის.
იტვირთება…სურვილისამებრ: Build Cats vs. ძაღლების კლასიფიკაცია
ჩვენ ასევე გვინდა ვნახოთ, რამდენად ზუსტი იქნება ჩვენი ორობითი კატების და ძაღლების კლასიფიკაცია იმავე თარიღის მიხედვით. ამისათვის ჩვენ უნდა დავარეგულიროთ ეტიკეტები:
იტვირთება…იტვირთება…