ეს ნოუთბუქები AI დამწყებთათვის სასწავლო პროგრამა-ის ნაწილია. ის შთაგონებულია ეს ბლოგის პოსტი, ოფიციალური TensorFlow დოკუმენტაცია და ეს Keras RL მაგალითი-ით.
ამ მაგალითში, ჩვენ გამოვიყენებთ RL-ს, რათა მოვამზადოთ მოდელი, რათა დააბალანსოს ბოძები ეტლზე, რომელსაც შეუძლია მოძრაობდეს მარცხნივ და მარჯვნივ ჰორიზონტალური მასშტაბით. ჩვენ გამოვიყენებთ OpenAI სპორტული დარბაზი გარემოს ბოძის სიმულაციისთვის.
შენიშვნა: შეგიძლიათ ამ გაკვეთილის კოდი ადგილობრივად გაუშვათ (მაგ. Visual Studio Code-დან), ამ შემთხვევაში სიმულაცია გაიხსნება ახალ ფანჯარაში. კოდის ონლაინ გაშვებისას შეიძლება დაგჭირდეთ კოდის შესწორება, როგორც აღწერილია აქ.
ჩვენ დავიწყებთ იმით, რომ დარწმუნდებით, რომ სპორტული დარბაზი დაყენებულია:
იტვირთება…გამოტანა
Defaulting to user installation because normal site-packages is not writeable
Requirement already satisfied: gym in /home/leo/.local/lib/python3.10/site-packages (0.25.0)
Requirement already satisfied: pygame in /home/leo/.local/lib/python3.10/site-packages (2.1.2)
Requirement already satisfied: gym-notices>=0.0.4 in /home/leo/.local/lib/python3.10/site-packages (from gym) (0.0.7)
Requirement already satisfied: cloudpickle>=1.2.0 in /home/leo/.local/lib/python3.10/site-packages (from gym) (2.1.0)
Requirement already satisfied: numpy>=1.18.0 in /usr/lib/python3/dist-packages (from gym) (1.21.5)
ახლა მოდით შევქმნათ CartPole გარემო და ვნახოთ როგორ ვიმოქმედოთ მასზე. გარემოს აქვს შემდეგი თვისებები:
- სამოქმედო სივრცე არის შესაძლო მოქმედებების ერთობლიობა, რომელთა შესრულებაც შეგვიძლია სიმულაციის თითოეულ საფეხურზე
- დაკვირვების სივრცე არის დაკვირვებების სივრცე, რომლის გაკეთებაც შეგვიძლია
იტვირთება…გამოტანა
Action space: Discrete(2)
Observation space: Box([-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], [4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38], (4,), float32)
/home/leo/.local/lib/python3.10/site-packages/gym/core.py:329: DeprecationWarning: WARN: Initializing wrapper in old step API which returns one bool instead of two. It is recommended to set `new_step_api=True` to use new step API. This will be the default behaviour in future.
deprecation(
/home/leo/.local/lib/python3.10/site-packages/gym/wrappers/step_api_compatibility.py:39: DeprecationWarning: WARN: Initializing environment in old step API which returns one bool instead of two. It is recommended to set `new_step_api=True` to use new step API. This will be the default behaviour in future.
deprecation(
ვნახოთ როგორ მუშაობს სიმულაცია. შემდეგი ციკლი აწარმოებს სიმულაციას, სანამ env.step არ დააბრუნებს შეწყვეტის დროშას done. ჩვენ შემთხვევით ავირჩევთ მოქმედებებს env.action_space.sample()-ის გამოყენებით, რაც ნიშნავს, რომ ექსპერიმენტი, სავარაუდოდ, ძალიან სწრაფად ჩავარდება (CartPole გარემო მთავრდება, როდესაც CartPole-ის სიჩქარე, მისი პოზიცია ან კუთხე გარკვეულ საზღვრებს მიღმაა).
სიმულაცია გაიხსნება ახალ ფანჯარაში. თქვენ შეგიძლიათ რამდენჯერმე გაუშვათ კოდი და ნახოთ როგორ იქცევა იგი.
იტვირთება…გამოტანა
/home/leo/.local/lib/python3.10/site-packages/gym/core.py:57: DeprecationWarning: WARN: You are calling render method, but you didn't specified the argument render_mode at environment initialization. To maintain backward compatibility, the environment will render in human mode.
If you want to render in human mode, initialize the environment in this way: gym.make('EnvName', render_mode='human') and don't call the render method.
See here for more information: https://www.gymlibrary.ml/content/api/
deprecation(
[ 0.00425272 -0.19994313 0.00917169 0.34113726] -> 1.0
[ 0.00025386 -0.00495286 0.01599443 0.05136059] -> 1.0
[ 1.5480528e-04 1.8993615e-01 1.7021643e-02 -2.3623335e-01] -> 1.0
[ 0.00395353 0.38481084 0.01229698 -0.5234989 ] -> 1.0
[ 0.01164974 0.18951797 0.001827 -0.22696657] -> 1.0
[ 0.0154401 0.38461378 -0.00271233 -0.51907265] -> 1.0
[ 0.02313238 0.5797738 -0.01309379 -0.812609 ] -> 1.0
[ 0.03472786 0.38483363 -0.02934597 -0.5240733 ] -> 1.0
[ 0.04242453 0.580356 -0.03982743 -0.8258571 ] -> 1.0
[ 0.05403165 0.38580072 -0.05634458 -0.54596174] -> 1.0
[ 0.06174766 0.19151384 -0.06726381 -0.27155042] -> 1.0
[ 0.06557794 -0.00258703 -0.07269482 -0.00081817] -> 1.0
[ 0.0655262 -0.19659522 -0.07271118 0.26807207] -> 1.0
[ 0.0615943 -0.00051497 -0.06734974 -0.04662942] -> 1.0
[ 0.061584 0.19550486 -0.06828233 -0.3597784 ] -> 1.0
[ 0.06549409 0.00141663 -0.0754779 -0.08938391] -> 1.0
[ 0.06552242 -0.19254686 -0.07726558 0.17856352] -> 1.0
[ 0.06167149 0.00359088 -0.0736943 -0.1374588 ] -> 1.0
[ 0.0617433 0.19968675 -0.07644348 -0.45245075] -> 1.0
[ 0.06573704 0.3958018 -0.0854925 -0.7682167 ] -> 1.0
[ 0.07365308 0.20195423 -0.10085683 -0.50361156] -> 1.0
[ 0.07769216 0.0083876 -0.11092906 -0.24433874] -> 1.0
[ 0.07785992 -0.18498953 -0.11581583 0.01139782] -> 1.0
[ 0.07416012 0.01158649 -0.11558788 -0.31546465] -> 1.0
[ 0.07439185 0.20814891 -0.12189718 -0.64224803] -> 1.0
[ 0.07855483 0.01491799 -0.13474214 -0.3903015 ] -> 1.0
[ 0.07885319 -0.17806001 -0.14254816 -0.14295265] -> 1.0
[ 0.07529199 0.01878517 -0.14540721 -0.47699296] -> 1.0
[ 0.07566769 -0.17401667 -0.15494707 -0.23344138] -> 1.0
[ 0.07218736 0.0229406 -0.1596159 -0.57071024] -> 1.0
[ 0.07264617 0.21989843 -0.1710301 -0.9091196 ] -> 1.0
[ 0.07704414 0.02745241 -0.1892125 -0.6747003 ] -> 1.0
[ 0.07759319 -0.16460665 -0.20270652 -0.4470505 ] -> 1.0
[ 0.07430106 -0.35637102 -0.21164753 -0.22448184] -> 1.0
Total reward: 34.0
თქვენ შეგიძლიათ შეამჩნიოთ, რომ დაკვირვებები შეიცავს 4 რიცხვს. ისინი არიან:
- ურიკის პოზიცია
- ურიკის სიჩქარე
- ბოძის კუთხე
- ბოძის ბრუნვის სიჩქარე
rew არის ჯილდო, რომელსაც ვიღებთ ყოველ ნაბიჯზე. თქვენ ხედავთ, რომ CartPole გარემოში თქვენ დაჯილდოვდებით 1 ქულით თითოეული სიმულაციური ნაბიჯისთვის და მიზანია მაქსიმალური ჯილდოს გაზრდა, ანუ დრო CartPole-ს შეუძლია დაბალანსება დაცემის გარეშე.
განმამტკიცებელი სწავლის დროს, ჩვენი მიზანია მოვამზადოთ პოლიტიკა $\pi$, რომელიც $s$ თითოეულ შტატზე გვეტყვის რომელი ქმედება $a$ უნდა მივიღოთ, ასე რომ, არსებითად $a = \pi(s)$.
თუ გსურთ სავარაუდო გამოსავალი, შეგიძლიათ იფიქროთ პოლიტიკაზე, როგორც აბრუნებს ალბათობების ერთობლიობას თითოეული ქმედებისთვის, ანუ $\pi(a|s)$ ნიშნავს ალბათობას, რომ ჩვენ უნდა განვახორციელოთ $a$ $s$ მდგომარეობაში.
პოლიტიკის გრადიენტის მეთოდი
უმარტივეს RL ალგორითმში, სახელწოდებით პოლიტიკის გრადიენტი, ჩვენ მოვამზადებთ ნერვულ ქსელს შემდეგი მოქმედების პროგნოზირებისთვის.
იტვირთება…გამოტანა
/usr/local/lib/python3.10/dist-packages/tensorflow/__init__.py:29: DeprecationWarning: The distutils package is deprecated and slated for removal in Python 3.12. Use setuptools or check PEP 632 for potential alternatives
import distutils as _distutils
2022-07-24 16:50:47.597258: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
2022-07-24 16:50:47.597280: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
/usr/local/lib/python3.10/dist-packages/flatbuffers/compat.py:19: DeprecationWarning: the imp module is deprecated in favour of importlib and slated for removal in Python 3.12; see the module's documentation for alternative uses
import imp
2022-07-24 16:50:49.838826: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:975] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-07-24 16:50:49.839078: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
2022-07-24 16:50:49.839143: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcublas.so.11'; dlerror: libcublas.so.11: cannot open shared object file: No such file or directory
2022-07-24 16:50:49.839194: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcublasLt.so.11'; dlerror: libcublasLt.so.11: cannot open shared object file: No such file or directory
2022-07-24 16:50:49.839245: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcufft.so.10'; dlerror: libcufft.so.10: cannot open shared object file: No such file or directory
2022-07-24 16:50:49.839295: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcurand.so.10'; dlerror: libcurand.so.10: cannot open shared object file: No such file or directory
2022-07-24 16:50:49.839345: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcusolver.so.11'; dlerror: libcusolver.so.11: cannot open shared object file: No such file or directory
2022-07-24 16:50:49.839392: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcusparse.so.11'; dlerror: libcusparse.so.11: cannot open shared object file: No such file or directory
2022-07-24 16:50:49.839441: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudnn.so.8'; dlerror: libcudnn.so.8: cannot open shared object file: No such file or directory
2022-07-24 16:50:49.839449: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1850] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices...
2022-07-24 16:50:49.839649: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
ჩვენ გავავარჯიშებთ ქსელს მრავალი ექსპერიმენტის ჩატარებით და ყოველი გაშვების შემდეგ ჩვენი ქსელის განახლებით. მოდით განვსაზღვროთ ფუნქცია, რომელიც ჩაატარებს ექსპერიმენტს და დააბრუნებს შედეგებს (ე.წ. კვალი) - ყველა მდგომარეობა, მოქმედება (და მათი რეკომენდებული ალბათობები) და ჯილდოები:
იტვირთება…შეგიძლიათ ერთი ეპიზოდის გაშვება მოუმზადებელი ქსელით და დააკვირდით, რომ ჯამური ჯილდო (AKA ეპიზოდის ხანგრძლივობა) ძალიან დაბალია:
იტვირთება…გამოტანა
Total reward: 27.0
პოლიტიკის გრადიენტის ალგორითმის ერთ-ერთი რთული ასპექტია ფასდაკლებული ჯილდოების გამოყენება. იდეა არის ის, რომ ჩვენ გამოვთვლით ჯამური ჯილდოების ვექტორს თამაშის ყოველ საფეხურზე და ამ პროცესის განმავლობაში ვამცირებთ ადრეულ ჯილდოებს რაღაც კოეფიციენტის $gamma$-ის გამოყენებით. ჩვენ ასევე ნორმალიზდება მიღებული ვექტორი, რადგან ჩვენ გამოვიყენებთ მას როგორც წონას, რომ გავლენა მოახდინოს ჩვენს ვარჯიშზე:
იტვირთება…ახლა მოდით გავაკეთოთ რეალური ტრენინგი! ჩვენ გავუშვებთ 300 ეპიზოდს და თითოეულ ეპიზოდში გავაკეთებთ შემდეგს:
- ჩაატარეთ ექსპერიმენტი და შეაგროვეთ კვალი
- გამოთვალეთ სხვაობა (
gradients) განხორციელებულ ქმედებებსა და პროგნოზირებულ ალბათობებს შორის. რაც უფრო ნაკლებია განსხვავება, მით უფრო დარწმუნებული ვართ, რომ სწორი ქმედება მივიღეთ. - გამოთვალეთ ფასდაკლებული ჯილდოები და გაამრავლეთ გრადიენტები ფასდაკლებულ ჯილდოებზე - რაც დარწმუნდება, რომ უფრო მაღალი ჯილდოს მქონე ნაბიჯები უფრო მეტ გავლენას მოახდენს საბოლოო შედეგზე, ვიდრე დაბალი ჯილდოებით
- ჩვენი ნერვული ქსელისთვის მოსალოდნელი სამიზნე მოქმედებები ნაწილობრივ იქნება აღებული სავარაუდო ალბათობებიდან გაშვების დროს და ნაწილობრივ გამოთვლილი გრადიენტებიდან. ჩვენ გამოვიყენებთ
alphaპარამეტრს, რათა განვსაზღვროთ, თუ რამდენად არის გათვალისწინებული გრადიენტები და ჯილდოები - ამას ეწოდება გაძლიერების ალგორითმის სწავლის სიჩქარე. - და ბოლოს, ჩვენ ვავარჯიშებთ ჩვენს ქსელს მდგომარეობებზე და მოსალოდნელ ქმედებებზე და ვიმეორებთ პროცესს
იტვირთება…გამოტანა
0 -> 29.0
2022-07-24 16:50:51.475024: W tensorflow/core/data/root_dataset.cc:247] Optimization loop failed: CANCELLED: Operation was cancelled
100 -> 135.0
200 -> 484.0
2022-07-24 16:51:35.910774: W tensorflow/core/data/root_dataset.cc:247] Optimization loop failed: CANCELLED: Operation was cancelled
2022-07-24 16:51:37.151017: W tensorflow/core/data/root_dataset.cc:247] Optimization loop failed: CANCELLED: Operation was cancelled
2022-07-24 16:51:39.284311: W tensorflow/core/data/root_dataset.cc:247] Optimization loop failed: CANCELLED: Operation was cancelled
2022-07-24 16:51:42.235074: W tensorflow/core/data/root_dataset.cc:247] Optimization loop failed: CANCELLED: Operation was cancelled
2022-07-24 16:51:44.691458: W tensorflow/core/data/root_dataset.cc:247] Optimization loop failed: CANCELLED: Operation was cancelled
2022-07-24 16:51:48.381946: W tensorflow/core/data/root_dataset.cc:247] Optimization loop failed: CANCELLED: Operation was cancelled
[<matplotlib.lines.Line2D at 0x7f40201e7b20>]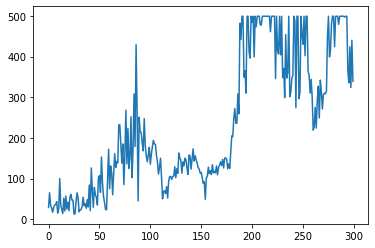
ახლა მოდით გავუშვათ ეპიზოდი რენდერით შედეგის სანახავად:
იტვირთება…გამოტანა
---------------------------------------------------------------------------
error Traceback (most recent call last)
/tmp/ipykernel_44248/1459719159.py in <module>
----> 1 _ = run_episode(render=True)
/tmp/ipykernel_44248/3855001447.py in run_episode(max_steps_per_episode, render)
4 for _ in range(max_steps_per_episode):
5 if render:
----> 6 env.render()
7 action_probs = model(np.expand_dims(state,0))[0]
8 action = np.random.choice(num_actions, p=np.squeeze(action_probs))
~/.local/lib/python3.10/site-packages/gym/core.py in render(self, *args, **kwargs)
64 )
65
---> 66 return render_func(self, *args, **kwargs)
67
68 return render
~/.local/lib/python3.10/site-packages/gym/core.py in render(self, *args, **kwargs)
429 def render(self, *args, **kwargs):
430 """Renders the environment."""
--> 431 return self.env.render(*args, **kwargs)
432
433 def close(self):
~/.local/lib/python3.10/site-packages/gym/core.py in render(self, *args, **kwargs)
64 )
65
---> 66 return render_func(self, *args, **kwargs)
67
68 return render
~/.local/lib/python3.10/site-packages/gym/wrappers/order_enforcing.py in render(self, *args, **kwargs)
49 "set `disable_render_order_enforcing=True` on the OrderEnforcer wrapper."
50 )
---> 51 return self.env.render(*args, **kwargs)
52
53 @property
~/.local/lib/python3.10/site-packages/gym/core.py in render(self, *args, **kwargs)
64 )
65
---> 66 return render_func(self, *args, **kwargs)
67
68 return render
~/.local/lib/python3.10/site-packages/gym/core.py in render(self, *args, **kwargs)
429 def render(self, *args, **kwargs):
430 """Renders the environment."""
--> 431 return self.env.render(*args, **kwargs)
432
433 def close(self):
~/.local/lib/python3.10/site-packages/gym/core.py in render(self, *args, **kwargs)
64 )
65
---> 66 return render_func(self, *args, **kwargs)
67
68 return render
~/.local/lib/python3.10/site-packages/gym/wrappers/env_checker.py in render(self, *args, **kwargs)
53 return env_render_passive_checker(self.env, *args, **kwargs)
54 else:
---> 55 return self.env.render(*args, **kwargs)
~/.local/lib/python3.10/site-packages/gym/core.py in render(self, *args, **kwargs)
64 )
65
---> 66 return render_func(self, *args, **kwargs)
67
68 return render
~/.local/lib/python3.10/site-packages/gym/envs/classic_control/cartpole.py in render(self, mode)
215 return self.renderer.get_renders()
216 else:
--> 217 return self._render(mode)
218
219 def _render(self, mode="human"):
~/.local/lib/python3.10/site-packages/gym/envs/classic_control/cartpole.py in _render(self, mode)
296
297 self.surf = pygame.transform.flip(self.surf, False, True)
--> 298 self.screen.blit(self.surf, (0, 0))
299 if mode == "human":
300 pygame.event.pump()
error: display Surface quitიმედია, ხედავთ, რომ ბოძს ახლა საკმაოდ კარგად შეუძლია წონასწორობა!
მსახიობი-კრიტიკოსი მოდელი
Actor-Critic მოდელი არის პოლიტიკის გრადიენტების შემდგომი განვითარება, რომელშიც ჩვენ ვაშენებთ ნერვულ ქსელს, რათა ვისწავლოთ როგორც პოლიტიკა, ასევე სავარაუდო ჯილდოები. ქსელს ექნება ორი გამომავალი (ან შეგიძლიათ იხილოთ როგორც ორი ცალკეული ქსელი):
- აქტორი რეკომენდაციას გაუწევს განსახორციელებელ ქმედებას და გვაძლევს მდგომარეობის ალბათობის განაწილებას, როგორც პოლიტიკის გრადიენტულ მოდელში
- კრიტიკოსი შეაფასებდა რა ჯილდოს მიიღებს ამ ქმედებებისგან. ის აბრუნებს მთლიან სავარაუდო ჯილდოს მომავალში მოცემულ მდგომარეობაში.
მოდით განვსაზღვროთ ასეთი მოდელი:
იტვირთება…ჩვენ დაგვჭირდება ოდნავ შევცვალოთ ჩვენი run_episode ფუნქცია, რათა დავაბრუნოთ ასევე კრიტიკული შედეგები:
იტვირთება…ახლა ჩვენ გავაგრძელებთ ძირითად სავარჯიშო ციკლს. ჩვენ გამოვიყენებთ ხელით ქსელის ტრენინგის პროცესს სათანადო დაკარგვის ფუნქციების გამოთვლით და ქსელის პარამეტრების განახლებით:
იტვირთება…გამოტანა
running reward: 5.82 at episode 10
running reward: 9.43 at episode 20
running reward: 10.30 at episode 30
running reward: 10.28 at episode 40
running reward: 11.00 at episode 50
running reward: 13.01 at episode 60
running reward: 21.78 at episode 70
running reward: 40.54 at episode 80
running reward: 73.70 at episode 90
running reward: 100.19 at episode 100
running reward: 159.20 at episode 110
Solved at episode 114!
მოდით გავუშვათ ეპიზოდი და ვნახოთ რამდენად კარგია ჩვენი მოდელი:
იტვირთება…საბოლოოდ დავხუროთ გარემო.
იტვირთება…Takeaway
ჩვენ ვნახეთ ორი RL ალგორითმი ამ დემოში: მარტივი პოლიტიკის გრადიენტი და უფრო დახვეწილი მსახიობი-კრიტიკოსი. თქვენ ხედავთ, რომ ეს ალგორითმები მოქმედებენ მდგომარეობის, მოქმედებისა და ჯილდოს აბსტრაქტული ცნებებით - ამგვარად, მათი გამოყენება შესაძლებელია ძალიან განსხვავებულ გარემოში.
განმტკიცების სწავლა საშუალებას გვაძლევს ვისწავლოთ პრობლემის გადაჭრის საუკეთესო სტრატეგია მხოლოდ საბოლოო ჯილდოს ნახვით. ის ფაქტი, რომ ჩვენ არ გვჭირდება ეტიკეტირებული მონაცემთა ნაკრები, საშუალებას გვაძლევს გავიმეოროთ სიმულაციები ბევრჯერ ჩვენი მოდელების ოპტიმიზაციისთვის. თუმცა, RL-ში ჯერ კიდევ ბევრი გამოწვევაა, რომელიც შეიძლება გაიგოთ, თუ გადაწყვეტთ მეტი ფოკუსირება მოახდინოთ AIს ამ საინტერესო სფეროზე.