წინა მოდულში განვიხილეთ ტექსტის მდიდარი სემანტიკური წარმოდგენები. არქიტექტურა, რომელსაც ჩვენ ვიყენებდით, აღწერს სიტყვების გაერთიანებულ მნიშვნელობას წინადადებაში, მაგრამ არ ითვალისწინებს სიტყვების მიმდევრობას, რადგან აგრეგაციის ოპერაცია, რომელიც მოჰყვება ჩაშენებებს, აშორებს ამ ინფორმაციას ორიგინალური ტექსტიდან. იმის გამო, რომ ამ მოდელებს არ შეუძლიათ სიტყვების დალაგების წარმოდგენა, მათ არ შეუძლიათ გადაჭრას უფრო რთული ან ორაზროვანი ამოცანები, როგორიცაა ტექსტის შექმნა ან კითხვებზე პასუხის გაცემა.
ტექსტის თანმიმდევრობის მნიშვნელობის გასაგებად, ჩვენ გამოვიყენებთ ნერვული ქსელის არქიტექტურას, რომელსაც ეწოდება განმეორებადი ნერვული ქსელი, ან RNN. RNN-ის გამოყენებისას, ჩვენ გადავცემთ ჩვენს წინადადებას ქსელში თითო-თითო ტოკენით და ქსელი აწარმოებს გარკვეულ მდგომარეობას, რომელსაც შემდეგ კვლავ გადავცემთ ქსელს შემდეგი ტოკენით.
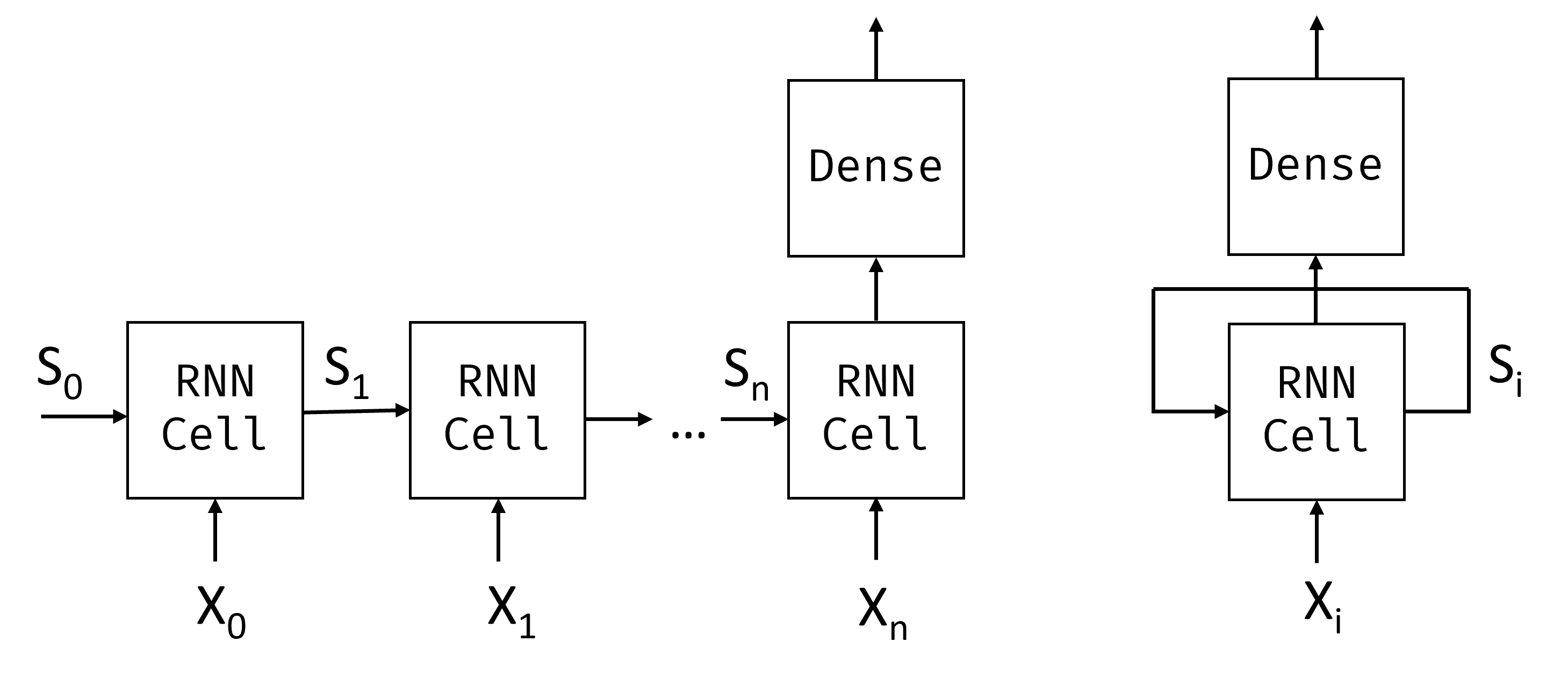
$X_0,\dots,X_n$ ნიშნების შეყვანის თანმიმდევრობის გათვალისწინებით, RNN ქმნის ნერვული ქსელის ბლოკების თანმიმდევრობას და ავარჯიშებს ამ თანმიმდევრობას ბოლომდე-ბოლომდე უკუს გავრცელების გამოყენებით. თითოეული ქსელის ბლოკი იღებს $(X_i,S_i)$ წყვილს, როგორც შეყვანას და შედეგად წარმოქმნის $S_{i+1}$-ს. საბოლოო მდგომარეობა $S_n$ ან გამომავალი $Y_n$ გადადის წრფივ კლასიფიკატორში შედეგის მისაღებად. ქსელის ყველა ბლოკი იზიარებს ერთსა და იმავე წონას და წვრთნიან ბოლომდე გავრცელების ერთი საშვის გამოყენებით.
ზემოთ მოყვანილი ფიგურა გვიჩვენებს განმეორებად ნერვულ ქსელს გაშლილი სახით (მარცხნივ) და უფრო კომპაქტური განმეორებითი წარმოდგენით (მარჯვნივ). მნიშვნელოვანია გვესმოდეს, რომ ყველა RNN უჯრედს აქვს იგივე გაზიარებადი წონა.
იმის გამო, რომ მდგომარეობის ვექტორები $S_0,\dots,S_n$ გადადის ქსელში, RNN-ს შეუძლია ისწავლოს თანმიმდევრული დამოკიდებულებები სიტყვებს შორის. მაგალითად, როდესაც სიტყვა not გამოჩნდება სადმე მიმდევრობაში, მას შეუძლია ისწავლოს გარკვეული ელემენტების უარყოფა მდგომარეობის ვექტორში.
შიგნით, თითოეული RNN უჯრედი შეიცავს ორ წონის მატრიცას: $W_H$ და $W_I$ და მიკერძოებას $b$. თითოეულ RNN საფეხურზე, $X_i$ შეყვანის და $S_i$ შეყვანის მდგომარეობის გათვალისწინებით, გამომავალი მდგომარეობა გამოითვლება როგორც $S_{i+1} = f(W_H\ჯერ S_i + W_I\ჯერ X_i+b)$, სადაც $f$ არის აქტივაციის ფუნქცია (ხშირად $\tanh$).
ისეთი პრობლემებისთვის, როგორიცაა ტექსტის გენერირება (რომელსაც განვიხილავთ შემდეგ ერთეულში) ან მანქანური თარგმანი, ჩვენ ასევე გვსურს მივიღოთ გარკვეული გამომავალი მნიშვნელობა ყოველ RNN საფეხურზე. ამ შემთხვევაში, ასევე არის სხვა $W_O$ მატრიცა და გამომავალი გამოითვლება როგორც $Y_i=f(W_O\ჯერ S_i+b_O)$.
ვნახოთ, როგორ დაგვეხმარება განმეორებადი ნერვული ქსელები ახალი ამბების მონაცემთა ბაზის კლასიფიკაციაში.
Sandbox გარემოსთვის, ჩვენ უნდა გავუშვათ შემდეგი უჯრედი, რათა დავრწმუნდეთ, რომ დაინსტალირებულია საჭირო ბიბლიოთეკა და მონაცემები წინასწარ არის ამოღებული. თუ ადგილობრივად მუშაობთ, შეგიძლიათ გამოტოვოთ შემდეგი უჯრედი.
იტვირთება…იტვირთება…დიდი მოდელების ვარჯიშისას, GPU მეხსიერების განაწილება შეიძლება პრობლემად იქცეს. ჩვენ ასევე შეიძლება დაგვჭირდეს ექსპერიმენტების ჩატარება სხვადასხვა მინი-სამეფო ზომებზე, რათა მონაცემები მოთავსდეს ჩვენს GPU მეხსიერებაში, მაგრამ ტრენინგი საკმაოდ სწრაფია. თუ თქვენ იყენებთ ამ კოდს საკუთარ GPU აპარატზე, შეგიძლიათ ექსპერიმენტი ჩაატაროთ მინი ჯგუფის ზომის რეგულირებით, რათა დააჩქაროთ ვარჯიში.
შენიშვნა: ცნობილია, რომ NVidia-ს დრაივერების ზოგიერთი ვერსია არ ათავისუფლებს მეხსიერებას მოდელის ვარჯიშის შემდეგ. ჩვენ ვატარებთ რამდენიმე მაგალითს ამ ნოუთბუქებში და ამან შეიძლება გამოიწვიოს მეხსიერების ამოწურვა გარკვეულ პარამეტრებში, განსაკუთრებით იმ შემთხვევაში, თუ თქვენ აკეთებთ საკუთარ ექსპერიმენტებს იმავე ნოუთბუქის ნაწილად. თუ მოდელის მომზადების დაწყებისას უცნაურ შეცდომებს წააწყდებით, შეიძლება დაგჭირდეთ ნოუთბუქის ბირთვის გადატვირთვა.
იტვირთება…მარტივი RNN კლასიფიკატორი
მარტივი RNN-ის შემთხვევაში, ყოველი განმეორებადი ერთეული არის მარტივი წრფივი ქსელი, რომელიც იღებს შეყვანის ვექტორს და მდგომარეობის ვექტორს და აწარმოებს ახალ მდგომარეობის ვექტორს. Keras-ში ეს შეიძლება იყოს წარმოდგენილი SimpleRNN ფენით.
მიუხედავად იმისა, რომ ჩვენ შეგვიძლია პირდაპირ გადავიტანოთ one-hot კოდირებული ტოკენები RNN ფენაზე, ეს არ არის კარგი იდეა მათი მაღალი განზომილების გამო. ამიტომ, ჩვენ გამოვიყენებთ ჩაშენების ფენას სიტყვების ვექტორების განზომილების შესამცირებლად, რასაც მოჰყვება RNN ფენა და ბოლოს Dense კლასიფიკატორი.
შენიშვნა: იმ შემთხვევებში, როდესაც განზომილება არც თუ ისე მაღალია, მაგალითად, სიმბოლოების დონის ტოკენიზაციის გამოყენებისას, შეიძლება გონივრული იყოს ერთჯერადი კოდირებული ტოკენების პირდაპირ RNN უჯრედში გადატანა.
იტვირთება…გამოტანა
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization (TextVect (None, None) 0
_________________________________________________________________
embedding (Embedding) (None, None, 64) 1280000
_________________________________________________________________
simple_rnn (SimpleRNN) (None, 16) 1296
_________________________________________________________________
dense (Dense) (None, 4) 68
=================================================================
Total params: 1,281,364
Trainable params: 1,281,364
Non-trainable params: 0
_________________________________________________________________
შენიშვნა: ჩვენ ვიყენებთ უვარჯიშებელ ჩაშენების ფენას აქ სიმარტივისთვის, მაგრამ უკეთესი შედეგისთვის შეგვიძლია გამოვიყენოთ წინასწარ გაწვრთნილი ჩაშენების ფენა Word2Vec-ის გამოყენებით, როგორც ეს აღწერილია წინა განყოფილებაში. კარგი სავარჯიშო იქნება თქვენთვის ამ კოდის მორგება წინასწარ მომზადებულ ჩაშენებებთან მუშაობისთვის.
ახლა მოდით ვავარჯიშოთ ჩვენი RNN. ზოგადად, RNN-ების მომზადება საკმაოდ რთულია, რადგან მას შემდეგ, რაც RNN უჯრედები გაიხსნება მიმდევრობის სიგრძის გასწვრივ, შედეგად მიღებული ფენების რაოდენობა, რომლებიც ჩართულია უკანა გავრცელებაში, საკმაოდ დიდია. ამრიგად, ჩვენ უნდა ავირჩიოთ უფრო მცირე სწავლის სიჩქარე და ვავარჯიშოთ ქსელი უფრო დიდ მონაცემთა ბაზაზე, რათა მივიღოთ კარგი შედეგები. ამას შეიძლება საკმაოდ დიდი დრო დასჭირდეს, ამიტომ სასურველია GPU-ს გამოყენება.
საქმეების დასაჩქარებლად, ჩვენ მოვამზადებთ RNN მოდელს მხოლოდ ახალი ამბების სათაურებზე, აღწერილობის გამოტოვებით. შეგიძლიათ სცადოთ ტრენინგი აღწერილობით და ნახოთ, შეძლებთ თუ არა მოდელის მომზადებას.
იტვირთება…გამოტანა
Training vectorizer
იტვირთება…გამოტანა
7500/7500 [==============================] - 82s 11ms/step - loss: 0.6629 - acc: 0.7623 - val_loss: 0.5559 - val_acc: 0.7995
<tensorflow.python.keras.callbacks.History at 0x7f3e0030d350>გაითვალისწინეთ, რომ აქ სიზუსტე სავარაუდოდ უფრო დაბალია, რადგან ჩვენ ვვარჯიშობთ მხოლოდ ახალი ამბების სათაურებზე.
ცვლადი თანმიმდევრობების ხელახლა ნახვა
დაიმახსოვრეთ, რომ TextVectorization ფენა ავტომატურად შეავსებს ცვლადი სიგრძის თანმიმდევრობებს მინიჯგუფში ბალიშის ნიშნებით. გამოდის, რომ ეს ნიშნებიც მონაწილეობენ ტრენინგში და მათ შეუძლიათ გაართულონ მოდელის კონვერგენცია.
არსებობს რამდენიმე მიდგომა, რომლის გამოყენებაც შეგვიძლია შევსების რაოდენობის შესამცირებლად. ერთ-ერთი მათგანია მონაცემთა ნაკრების გადალაგება მიმდევრობის სიგრძის მიხედვით და ყველა თანმიმდევრობის დაჯგუფება ზომის მიხედვით. ეს შეიძლება გაკეთდეს tf.data.experimental.bucket_by_sequence_length ფუნქციის გამოყენებით (იხ. დოკუმენტაცია).
კიდევ ერთი მიდგომაა ნიღბის გამოყენება. Keras-ში, ზოგიერთი ფენა მხარს უჭერს დამატებით შეყვანას, რომელიც გვიჩვენებს, თუ რომელი ნიშნები უნდა იქნას გათვალისწინებული ვარჯიშის დროს. ჩვენს მოდელში ნიღბის ჩასართავად, ჩვენ შეგვიძლია დავამატოთ ცალკე Masking ფენა (დოკუმენტები), ან შეგვიძლია დავაკონკრეტოთ ჩვენი Embedding ფენის mask_zero=True პარამეტრი.
შენიშვნა: ამ ტრენინგს დაახლოებით 5 წუთი დასჭირდება მთელი მონაცემთა ერთი ეპოქის დასრულებას. მოგერიდებათ შეწყვიტოთ ვარჯიში ნებისმიერ დროს, თუ მოთმინება ამოგეწურებათ. რისი გაკეთებაც შეგიძლიათ, არის შეზღუდოთ ტრენინგისთვის გამოყენებული მონაცემების რაოდენობა
.take(...)პუნქტის დამატებითds_trainდაds_testმონაცემთა ნაკრების შემდეგ.
იტვირთება…გამოტანა
7500/7500 [==============================] - 371s 49ms/step - loss: 0.5401 - acc: 0.8079 - val_loss: 0.3780 - val_acc: 0.8822
<tensorflow.python.keras.callbacks.History at 0x7f3dec118850>ახლა, როდესაც ჩვენ ვიყენებთ ნიღბებს, ჩვენ შეგვიძლია მოვამზადოთ მოდელი სათაურებისა და აღწერილობების მთელ მონაცემთა ბაზაზე.
შენიშვნა: შეგიმჩნევიათ, რომ ჩვენ ვიყენებდით ახალი ამბების სათაურებზე გაწვრთნილ ვექტორიზატორს და არა სტატიის მთელ ნაწილს? პოტენციურად, ამან შეიძლება გამოიწვიოს ზოგიერთი ტოკენის იგნორირება, ამიტომ უმჯობესია ვექტორიზატორის ხელახლა მომზადება. თუმცა, მას შეიძლება ჰქონდეს მხოლოდ ძალიან მცირე ეფექტი, ამიტომ სიმარტივისთვის ჩვენ დავიცავთ წინა წინასწარ გაწვრთნილ ვექტორიზატორს.
LSTM: გრძელვადიანი მოკლევადიანი მეხსიერება
RNN-ების ერთ-ერთი მთავარი პრობლემაა გრადიენტების გაქრობა. RNN-ები შეიძლება საკმაოდ გრძელი იყოს და შეიძლება გაუჭირდეს გრადიენტების გავრცელება ქსელის პირველ ფენამდე უკან გავრცელების დროს. როდესაც ეს მოხდება, ქსელი ვერ ისწავლის ურთიერთობას შორეულ ტოკენებს შორის. ამ პრობლემის თავიდან აცილების ერთ-ერთი გზაა გამოკვეთილი მდგომარეობის მართვა კარიბჭის გამოყენებით. ორი ყველაზე გავრცელებული არქიტექტურა, რომელიც შემოაქვს კარიბჭეებს, არის გრძელვადიანი მოკლევადიანი მეხსიერება (LSTM) და კარით სარელეო ერთეული (GRU). ჩვენ გავაშუქებთ LSTM-ებს აქ.

LSTM ქსელი ორგანიზებულია RNN-ის მსგავსად, მაგრამ არის ორი მდგომარეობა, რომლებიც გადაეცემა ფენიდან ფენას: რეალური მდგომარეობა $c$ და ფარული ვექტორი $h$. თითოეულ ერთეულზე, ფარული ვექტორი $h_{t-1}$ შერწყმულია $x_t$-თან და ისინი ერთად აკონტროლებენ რა დაემართება $c_t$ მდგომარეობას და გამომავალი $h_{t}$ კარიბჭის გავლით. თითოეულ კარიბჭეს აქვს სიგმოიდური გააქტიურება (გამომავალი $[0,1]$ დიაპაზონში), რომელიც შეიძლება ჩაითვალოს ბიტიურ ნიღბად, როდესაც მრავლდება მდგომარეობის ვექტორზე. LSTM-ებს აქვთ შემდეგი კარიბჭე (მარცხნიდან მარჯვნივ ზემოთ სურათზე):
- Forget Gate რომელიც განსაზღვრავს $c_{t-1}$ ვექტორის რომელი კომპონენტები უნდა დავივიწყოთ და რომელი გავიაროთ.
- შესვლის კარიბჭე, რომელიც განსაზღვრავს, თუ რამდენი ინფორმაცია უნდა იყოს ჩართული შეყვანის ვექტორიდან და წინა ფარული ვექტორიდან მდგომარეობის ვექტორში.
- გამომავალი კარიბჭე, რომელიც იღებს ახალ მდგომარეობის ვექტორს და წყვეტს, რომელი მისი კომპონენტი იქნება გამოყენებული ახალი ფარული ვექტორის $h_t$-ის შესაქმნელად.
$c$ სახელმწიფოს კომპონენტები შეიძლება ჩაითვალოს დროშებად, რომლებიც შეიძლება ჩართოთ და გამორთოთ. მაგალითად, როდესაც თანმიმდევრობით ვხვდებით სახელს ალისა, ვხვდებით, რომ ის ქალს ეხება და დროშას ავწევთ ისეთ მდგომარეობაში, რომელიც ამბობს, რომ წინადადებაში გვაქვს ქალი არსებითი სახელი. როდესაც ჩვენ შემდგომ ვხვდებით სიტყვებს and Tom, ჩვენ ავწევთ დროშას, რომელიც ამბობს, რომ გვაქვს მრავლობითი არსებითი სახელი. ამრიგად, მდგომარეობის მანიპულირებით ჩვენ შეგვიძლია თვალყური ადევნოთ წინადადების გრამატიკულ თვისებებს.
შენიშვნა: აქ არის შესანიშნავი რესურსი LSTM-ების შინაგანი გაგებისთვის: LSTM ქსელების გაგება კრისტოფერ ოლაჰის მიერ.
მიუხედავად იმისა, რომ LSTM უჯრედის შიდა სტრუქტურა შეიძლება რთულად გამოიყურებოდეს, Keras მალავს ამ განხორციელებას LSTM ფენაში, ასე რომ, ერთადერთი, რაც უნდა გავაკეთოთ ზემოთ მოცემულ მაგალითში, არის განმეორებითი ფენის შეცვლა:
იტვირთება…გამოტანა
15000/15000 [==============================] - 188s 13ms/step - loss: 0.5692 - acc: 0.7916 - val_loss: 0.3441 - val_acc: 0.8870
<tensorflow.python.keras.callbacks.History at 0x7f3d6af5c350>გაითვალისწინეთ, რომ LSTM-ების სწავლება ასევე საკმაოდ ნელია და შესაძლოა, ვარჯიშის დასაწყისში სიზუსტე მნიშვნელოვნად არ გაზარდოთ. შეიძლება დაგჭირდეთ ვარჯიშის გაგრძელება გარკვეული დროის განმავლობაში კარგი სიზუსტის მისაღწევად.
ორმხრივი და მრავალშრიანი RNN
ჩვენს მაგალითებში აქამდე მორეციდივე ქსელები მოქმედებენ მიმდევრობის დასაწყისიდან ბოლომდე. ეს ბუნებრივია ჩვენთვის, რადგან ის მიჰყვება იმავე მიმართულებას, რომლითაც ჩვენ ვკითხულობთ ან ვუსმენთ მეტყველებას. თუმცა, სცენარებისთვის, რომლებიც საჭიროებენ შეყვანის თანმიმდევრობის შემთხვევით წვდომას, უფრო ლოგიკურია განმეორებითი გამოთვლების გაშვება ორივე მიმართულებით. RNN-ებს, რომლებიც საშუალებას აძლევს გამოთვლას ორივე მიმართულებით, ეწოდება ორმხრივი RNN და მათი შექმნა შესაძლებელია განმეორებადი ფენის სპეციალური Bidirectonal ფენით შეფუთვით.
შენიშვნა:
Bidirectionalფენა აკეთებს ფენის ორ ასლს მასში და აყენებს ერთ-ერთი ასლისgo_backwardsთვისებასTrue-ზე, რის შედეგადაც ის მიდის საპირისპირო მიმართულებით მიმდევრობის გასწვრივ.
განმეორებადი ქსელები, ცალმხრივი ან ორმხრივი, იღებენ შაბლონებს მიმდევრობის ფარგლებში და ინახავენ მათ მდგომარეობის ვექტორებში ან აბრუნებენ მათ გამომავალს. როგორც კონვოლუციური ქსელების შემთხვევაში, ჩვენ შეგვიძლია ავაშენოთ კიდევ ერთი განმეორებადი ფენა პირველის შემდეგ უფრო მაღალი დონის შაბლონების აღსაბეჭდად, რომელიც აგებულია პირველი ფენის მიერ ამოღებული ქვედა დონის შაბლონებიდან. ეს მიგვიყვანს მრავალფენიანი RNN-ის ცნებამდე, რომელიც შედგება ორი ან მეტი განმეორებადი ქსელისაგან, სადაც წინა ფენის გამომავალი გადაეცემა შემდეგ ფენას შეყვანის სახით.
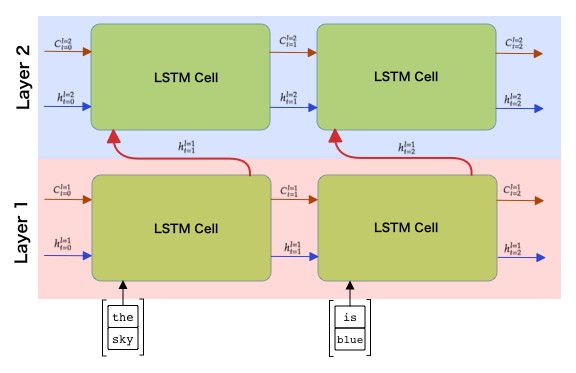
სურათი ეს მშვენიერი პოსტი-დან ფერნანდო ლოპესიდან.
Keras ამ ქსელების მშენებლობას მარტივ ამოცანას ხდის, რადგან თქვენ უბრალოდ უნდა დაამატოთ მეტი განმეორებადი ფენა მოდელს. ყველა ფენისთვის უკანასკნელის გარდა, ჩვენ უნდა მივუთითოთ return_sequences=True პარამეტრი, რადგან გვჭირდება ფენა ყველა შუალედური მდგომარეობის დასაბრუნებლად და არა მხოლოდ განმეორებითი გამოთვლის საბოლოო მდგომარეობა.
მოდით ავაშენოთ ორფენიანი ორმხრივი LSTM ჩვენი კლასიფიკაციის პრობლემისთვის.
შენიშვნა ამ კოდის შევსებას კვლავ საკმაოდ დიდი დრო სჭირდება, მაგრამ ის გვაძლევს ყველაზე მაღალ სიზუსტეს, რაც აქამდე გვინახავს. ასე რომ, იქნებ ღირს ლოდინი და შედეგის ნახვა.
იტვირთება…გამოტანა
5044/7500 [===================>..........] - ETA: 2:33 - loss: 0.3709 - acc: 0.8706
5045/7500 [===================>..........] - ETA: 2:33 - loss: 0.3709 - acc: 0.8706RNN სხვა ამოცანებისთვის
აქამდე ჩვენ ორიენტირებული ვიყავით RNN-ების გამოყენებაზე ტექსტის თანმიმდევრობის კლასიფიკაციისთვის. მაგრამ მათ შეუძლიათ მრავალი სხვა დავალების შესრულება, როგორიცაა ტექსტის შექმნა და მანქანური თარგმანი — ჩვენ განვიხილავთ ამ ამოცანებს შემდეგ განყოფილებაში.